Turbo编码器提升毫微微蜂窝DSP的效率
输出1个奇偶校验位总共需要10个周期(包括开销)。

计算复杂度。由于我们使用查找表来检索交织地址,而不是即时计算,因此只有访问查找表需要一些周期(可能不涉及计算操作)。交织一个数据位需要大约三个周期(一个周期用于加载偏移,两个周期用于计算绝对地址)。Turbo编码涉及到两个RSC编码器和一个交织操作,因此编码一个数据位总共需要25个周期(包括开销)。对于14.4 Mbps比特率的毫微微蜂窝应用,我们需要大约360 MIPS,即约60%的Blackfin处理器MIPS。
Turbo码的处理
如前所述,如果实现不当,更高比特率的Turbo编码器将是一个昂贵的模块。接下来,我们将讨论高效实现Turbo编码器的技术。我们将Turbo编码器分为两部分:第一部分是来处理位的编码,第二部分是处理数据位的交织。
使用查找表进行编码。如前所述,使用两个RSC编码器进行Turbo编码时,每个输入位需要大约20个周期。下面我们将介绍一种不同的使用查找表方法,每个输入位只需2.5个周期(用于两个编码器)。为了存储查找表数据,需要256个字节的额外存储器。考虑到RSC编码器的目前状态,使用查找表一次可以编码多个位。通过预先计算长度L的输入位的所有可能组合和状态位的所有三种组合的查找表,我们一次可以编码L位。在这种编码中,我们使用的查找表含有2L+3项。随着L值增大,查找表也会增大。L = 4时(换言之,一次编码4位),查找表含有27或128项,如图2所示。各项包含4个编码位和3位更新状态信息。换言之,一个字节(或8位)足以代表查找表的各项。
基于查找表的Turbo编码
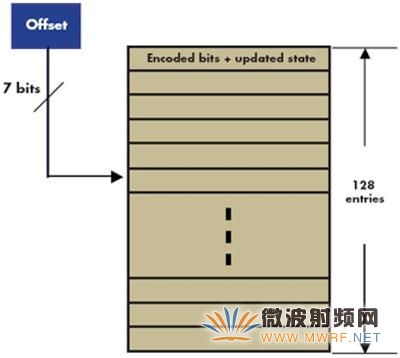
图2.
深入研究8位查找表设计可以发现,为了从4个输入位(假设位于寄存器r0)和3个当前状态位(假设位于寄存器r1)计算128项查找表的7位偏移,我们必须从输入字节(或从r0)提取(1个周期)4个数据位(假设存入寄存器r2),从前一编码的查找表输出(或从r1)提取(1个周期)当前状态(假设存入寄存器r3),将3个状态位移动(1个周期)4位(r3 = r3<<4),以及对提取的4个输入数据位至状态位求"或"(1个周期;即r4 = r2|r3)。只要正确设计查找表,我们就能避免状态位的提取和移位操作。如果我们对各查找表项使用两个字节,并将状态位置于移位位置,如图3所示,我们就能省掉两个偏移计算周期(节约50%)。
高效Turbo编码的查找表设计
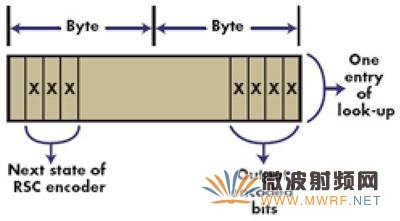
图3.
完成编码位的计算之后,我们必须将编码位封包。我们一次编码4位,并且一次输出一个编码的4位半字节,因此将半字节封包成字节是很容易的事。我们用两个周期将两个半字节封包成一个字节,一个周期用于左移,另一个周期用于"或"或"和"运算。对于双编码器输出封包,Blackfin需要四个周期。利用乘法累加器(MAC),我们可以在两个周期内完成两个编码器的封包工作,因为Blackfin有两个MAC单元。对于单迭代循环,用于Turbo编码器编码和封包的Blackfin ASM代码如表2所示。该ASM代码包括两个RSC编码器的编码和封包。ASM代码清楚地显示,一个字节的Turbo编码需要20个周期,或者说每个位需要2.5个周期。


在表2中,借助此ASM代码,我们可一次实现两个编码器的4位数据编码。但实际上,第二个编码器并不直接从输入比特流字节中获得数据。传送给第二编码器之前,我们必须对输入比特流进行交织处理。我们已经讨论了第二个编码器的交织,交织位存储在交织缓冲器中。我们假设,通过将交织位存储在可寻址的边界内(换言之,存储一位必须使用最小的字节),所存储的交织位可以直接从缓冲器存取进行编码。由于我们是利用查找表方法以半字节形式进行编码,因此必须先将交织位封包成字节,再将其存储在交织缓冲器中。
交织器设计。由于上述基于查找表的编码方法需要字节形式的交织位,因此必须将交织位封包成字节。这样,为了以正确的顺序将这些位送入第二个编码器,必须执行以下三个步骤:拆包、交织、封包。我们以字节表示数据,封包是将位多路复用为字节,拆包是将字节解多路复用为位。将位封包成字节需要所有交织位,我们首先必须完成交织处理。对于这两种操作(拆包和交织),每位大约需要3个周期,如表3所示。表3中的ASM代码对一个字节的输入数据执行拆包和交织处理。带进位的循环移位指令rot r by -1可提供从结尾最高有效位(MSB)开始的拆包数据位。

下一步是将交织数据位封包成字节。封包操作与表3所示的拆包操作完全相反。但是,如果我们使用进位循环指令rot r by 1进行封包,则每位需要2个周期,其中一个周期用于将寄存器中的数据位移入cc。因此,我们不使用循环,而使用比较和选择指令vit_max进
- 射频模拟前端在毫微微蜂窝基站中的应用(04-01)