HyperLink编程和性能考量
摘要
HyperLink为两个KeyStone架构DSP之间提供了一种高速,低延迟,引脚数量少的通信接口。HyperLink的用户手册已经详细的对其进行了描述。本文主要是为HyperLink的编程提供了一些额外的补充信息。
同时本文还讨论了HyperLink的性能,提供了在各种操作条件下的性能测试数据。对影响HyperLink性能的一些参数进行了讨论。
文章的最后附上对应本文的应用代码。
1、HyperLink介绍
HyperLink为两片DSP之间提供一种高速、低延迟,引脚数少的通信连接接口。
HyperLink的设计速度最高速率支持12.5Gbps,目前在大部分的KeyStone DSPs上,由于受限于SerDes和板级布线,速度接近为10Gbps.HyperLink是TI专有的外设接口。相对于用于高速Serdes接口的传统的8b10b编码方式,HyperLink减少了编码冗余,编码方式等效于8b9b.单片DSP为HyperLink提供4个SerDes通道,所以10Gbps的HyperLink理论吞吐率为10*4*(8/9)= 35.5Gbps= 4.44GB/s.
HyperLink使用了PCIE类似的内存映射机制,但它为多核DSP提供了一些更灵活的特性。本文将会使用几个范例来详细解释这一点。
本文还讨论了HyperLink的性能,提供了在各种操作条件下的性能测试数据。对影响HyperLink性能的一些因素进行了讨论。
2、HyperLink配置
本节提供了一些配置HyperLink模块的补充信息。
2.1 Serdes配置
Serdes必须配置成期望的链接速度。图1表示了输入参考时钟和输出时钟之间的关系。
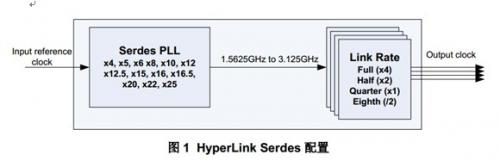
输入参考时钟建议限制在156.25MHz ~312.5MHz范围内。Serdes PLL的倍频系数必须合理配置生成的内部时钟(internal clock)限制在1.5625GHz ~ 3.125GHz范围内。
最后的链接速度由内部时钟(internal clock)驱动,通过link rate配置来得到。
2.2 HyperLink存储映射配置
HyperLink的存储映射非常的灵活。HyperLink的用户手册对此作了详细的描述。本节将用两个例子来详细的解释它。图2是第一个例子。
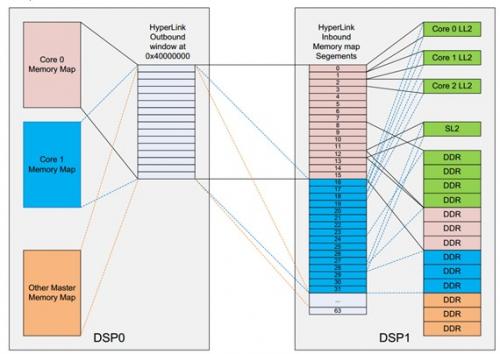
图2通过HyperLink窗口映射到远端不同类型的存储空间
在这个例子里面,DSP1的存储空间映射到了DSP0的存储空间窗口0x40000000~0x50000000DSP0可以访问DSP1的所有内存空间,包括LL2,SL2,DDR,就像访问自己的本地的存储空间一样。在DSP0上,所有的Master都可以通过以0x40000000起始的Outbound窗口地址来访问DSP1的存储空间,但是不同master事实上可能访问到DSP1上不同的存储空间。原因是HyperLink发送侧传输数据时,会将PrivID一起传输。接受侧通过PrivID值,可以建立不同的地址映射表
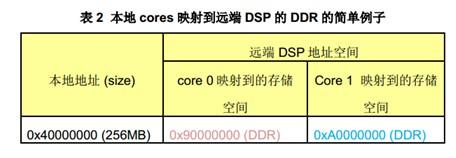
对DSP0与DSP1的内存映射关系总结在下表(表1)。

通过上表的配置,可知当DSP0的core 0/1访问0x40800000,它事实上访问了DSP1上的LL2地址空间。
当DSP0的core0访问0x4D000000,它事实上访问了DSP1上DDR的地址空间0x8C000000当DSP0的core1访问0x4D000000,它事实上访问了DSP1上DDR的地址空间0x8F000000与本文档对应的范例工程将HyperLink配置成上述的内存映射关系。下面是关键部分的配置代码。
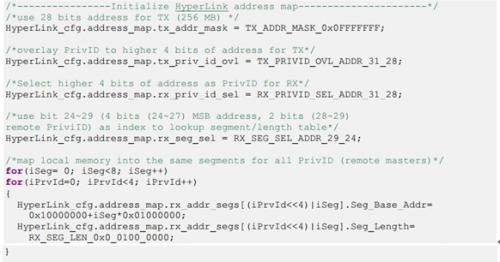
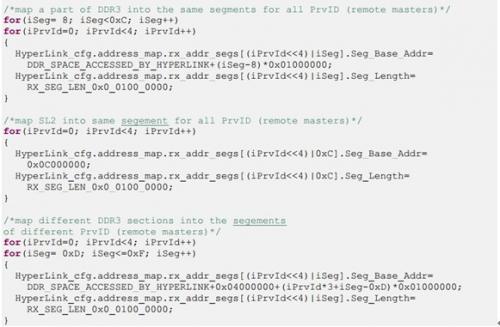
对于一些简单的应用,可能只是想访问远程DSP的DDR空间,那么下面的例子用于这种情况。存储映射关系如下图所示。
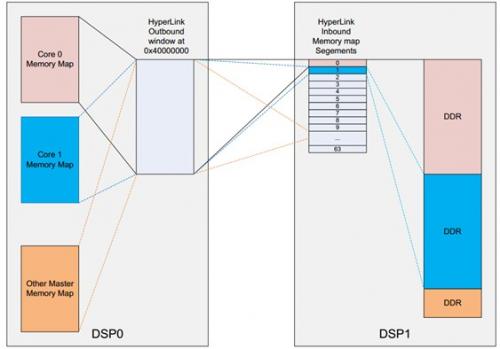
图3通过HyperLink窗口只映射到远端的DDR空间
这是最简单的例子,但是却可以访问远端DSP的大块存储空间。DSP0上的每个master(core或者其他外设)都可以可以访问DSP1上256MB DDR空间。下表描述了core0和core1的对remote DSP DDR存储映射。
3、HyperLink性能考虑
本节将让设计者对HyperLink访问远程存储空间的性能评估有基本的认识。同时提供了在不同的操作条件下获得的性能测试数据。大部分测试是在最理想的测试条件进行,以评估可以获得的最大吞吐量。
本文所描述的绝大部分性能数据是在C6670EVM上获得。C6670 EVM上DDR配置成64bit位宽1333M,HyperLink速率配置成10Gbit.
一些影响HyperLink访问性能的因素在本节中将会被讨论到。
3.1通过HyperLink实现存储拷贝的性能
下表(表3)描述了使用HyperLink在LL2与远程大块线性存储空间进行数据传送测试获得的传输带宽。传输块的大小为64KB.带宽的计算是通过计算传输总的字节数除以传输所用的时间获得。
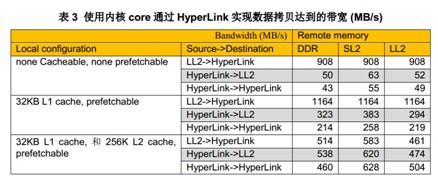
上述数据展示了cache能够极大的改善DSP内核通过HyperLink读取数据的性能。
但是L2 cache却遏制了通过HyperLink写数据的性能,这是因为L2是write-allocate cache.对于使能L2cache后的写操作,它总是会先从将要写入的存储区读取128字节的数据到L2cache,然后在L2 cache中修改数据,最后在cache冲突的时候回写回到原先的存储区,或者人为的回写回原存储区。
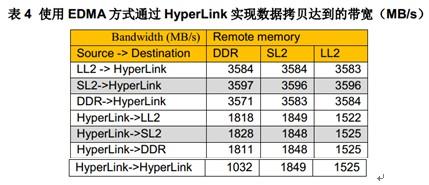
上述EDMA吞吐率数据是通过TC0 (传输控制器0)和CC0(通道控制器0)上测试得到,其他TCs的数据会比TC0稍低。整个传输的瓶颈是在HyperLink,不是在EDMA传输控制器上。
上述测试结果表明通过HyperLink进行写操作的性能会比通过HyperLink进行读操作的性能要好。
远程DSP存储空间类型不会对带宽造成明显的影响。访问远程DSP的SL2会比LL2快一些。
目前,通过HyperLink来访问远程DSP存储空间(相对其他接口)是具有最高的带宽性能的,但是访问远程存储空间比访问本地存储空间还是要慢。下表对比了访问本地LL2和DDR与远程DDR的吞吐性能。
HyperLink KeyStone 远程访问 中断延迟 相关文章:
- 基于KeyStone 器件建立鲁棒性系统(10-29)
- 在KeyStone 器件实现IEEE1588 时钟方案(10-15)
- 基于多核处理器的弹载嵌入式系统设计研究(02-18)
- Navigator Runtime 最大限度提高多内核效率(05-08)
- 基于KeyStone DSP的多核视频处理技术(09-15)
- KeyStone多核SoC工具套件: 单个平台满足所有需求(09-07)