HyperLink编程和性能考量
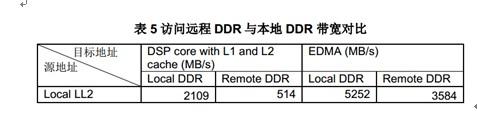
大体来说,对本地存储空间的写入吞吐率是对远程空间进行写入操作的吞吐率的3倍。对远程空间的读性能会更差些。我们应该尽量避免远程读取数据。
3.2 DSP core通过HyperLink进行远程访问的延迟
DSP核通过HyperLink访问远程空间的性能高度依赖于cache.当DSP内核通过HyperLink来访问远程存储空间的时候,一个TR(传输请求)可能会被生成并传送给XMC(这取决于数据是否可以进入cache和被预取)。TR将会是下面中的一种。
一个单一的元素-如果存储空间不能被cache和预存取。
一个L1 cache line -如果存储空间可以进入cache,但是L2 cache没有被使能。
一个L2 cache line -如果存储空间可以进入cache,同时L2 cache被使能。
如果存储空间可以被预存取,预存取将会被使能为一个预存取的buffer slot.
如果L1/L2cache或者预存取命中,Hyperlink端口不会有数据传输
远程空间数据可以被本地L1 cache/L2 cache缓存,或者都没有被cache.如果对应存储空间的MAR(Memory Attribute Register)寄存器上的PC(Permit copy)位没有被置位,那么对应存储区的数据将不会进入cache.
如果MAR寄存器上PC位被置位,同时L2的cache空间是0(L2被全部配置成SRAM),那么外部存储空间的数据可以进入L1cache.
如果MAR寄存器上PC位被置位,L2的Cache空间大于0.那么外部存储空间的数据就可以进入L1cache和L2cache.
读取远程存储空间数据也可以使用XMC中的prefetch buffer.该特性可以在MAR寄存器PFX(PreFetchable eXternally)被置位后使能。
地址步进长度也会影响Cache和Prefetch buffer的使用效果。连续空间的访问可以最充分的利用cache和prefetch buffer,从而达到更好的性能。
以64bytes距离或者更大间隔进行步进访问将会导致每次L1 cache命中失败(miss),这是因为L1 cache line的大小是64byte.
以128bytes距离或者更大间隔进行步进访问将会导致每次L2 cache命中失败(miss)。
如果cache miss发生,那么DSP核就会被stall(等待数据)。Stall的时间长度等于传输延迟、传输间隔,数据返回时间,cache请求延迟的总和。
下面的章节描述DSP内核通过HyperLink访问存储区的延迟。测试伪代码如下列所示。

下图(图4)为1GHz C6670EVM上配置DDR 64bit 1333M测试获得的结果。通过HyperLink实现512次LDDW(load double word)或者STDW( store double word)操作的性能测试。图4绘制了各种测试条件下的性能。LDB/STB和LDW/STW和LDDW/STDW的指令周期数相同。虽然cache和prefetch buffer可以被独立配置,但是测试的时候使用的配置是:如果cache被使能,那么prefetch也被使能,如果cache没有被使能,那么prefetch也没有被使能。
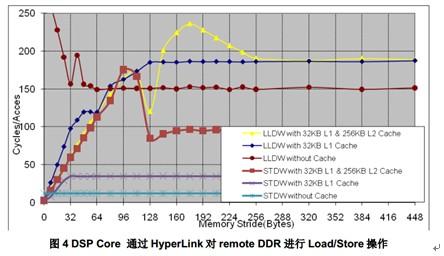
Non-cachable写是post操作。所以它只会stall DSP core很短的一段时间。
但是read是non-post的,所以DSP内核会等待数据的到来,所以它会stall DSP内核相对长一点时间。
当cache被使能后,DSP core访问remote空间的吞吐性能高度依赖于cache.
地址的步进间隔也会影响到cache的使用。连续的地址访问可以充分的利用cache.但是地址的步进间隔超过case line的大小(L1 case line =64Byte,L2 Case line =128Byte)将会导致每次cache都无法命中,从而制约了性能。所以,对连续地址空间的数据访问(像大块数据拷贝),cache需要被使能,在其他情况下cache应当不要使能。
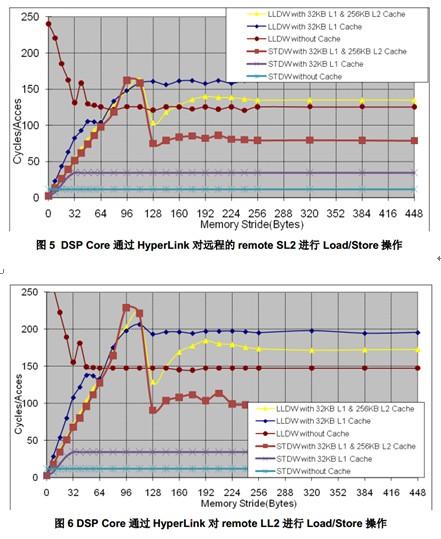
通过上面的图可以发现通过HyperLink访问DDR,SL2,LL2在性能上并没有明显的差异。所以,正常情况下,通过HyperLink来共享DDR是一个很好的选择,因为DDR容量大,而且成本低。
3.3 HyperLink传输使用DMA方式的开销(overhead)
初始延迟被定义为EMDA事件触发到真实数据之间的传输开始之间的延迟。因为初始延迟很难被测量。所以我们就测试传输的开销,它被定义为传输最小单元数据的延迟。延迟的大小取决于源和目标端的类型。下表描述了使用EDMA在1GHz TCI6618EVM不同端口间传输一个字(word)时,从EDMA触发(写ESR)到EDMA传输结束(读IPR=1)的平均指令数目。
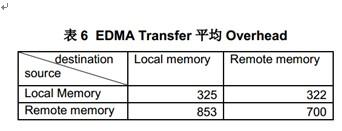
表6中,读Hyperlink的延迟是853个指令周期,写Hyperlink的延迟是322指令周期,因为写是post操作,而读是non-post操作。所以从HyperLink端口读取数据的延迟要高于写入数据到HyperLink.
对于小批量数据传送,传输开销(overhead)是很大的顾虑,尤其是系统中队列DMA阻塞的时候。单一元素的传送性能较差,延迟会占用大部分时间。所以,对于小批量数据传送,必须对使用EMDA方式还是DSP核方式来访问数据进行权衡。使用内核来访问单个随机数据的延迟会比DMA方式延迟小很多。本文3.2节已经做了详细的描述。
3.4 HyperLink中断延迟
HyperLink KeyStone 远程访问 中断延迟 相关文章:
- 基于KeyStone 器件建立鲁棒性系统(10-29)
- 在KeyStone 器件实现IEEE1588 时钟方案(10-15)
- 基于多核处理器的弹载嵌入式系统设计研究(02-18)
- Navigator Runtime 最大限度提高多内核效率(05-08)
- 基于KeyStone DSP的多核视频处理技术(09-15)
- KeyStone多核SoC工具套件: 单个平台满足所有需求(09-07)