ARM体系结构之:流水线
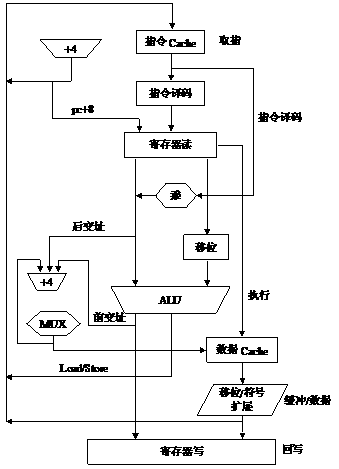
可以使用更高的时钟频率,分开的指令和数据存储器使核的CPI明显减少。 注意 分开的指令和数据存储器。一般是分开的Cache连接到统一的指令和数据存储器上。 在ARM9TDMI中使用了典型的5级流水线。ARM9TDMI的组织结构如图2.7所示。 5级流水线包括下面的流水线级: · 取指(fetch):从存储器中取出指令,并将其放入指令流水线。 · 译码(decode):指令被译码,从寄存器堆中读取寄存器操作数。在寄存器堆中有3个操作数读端口,因此,大多数ARM指令能在1个周期内读取其操作数。 · 执行(execute):将其中一个操作数移位,并在ALU中产生结果。如果指令是Load或Store指令,则在ALU中计算存储器的地址。 · 缓冲/数据(buffer/data):如果需要则访问数据存储器,否则ALU只是简单地缓冲一个时钟周期。 · 回写(write-back):将指令的结果回写到寄存器堆,包括任何从寄存器读出的数据。 图2.8显示了5级流水线指令的执行过程。 图2.7 5级流水线的组织结构 图2.8 5级流水线 在程序执行过程中,PC值是基于3级流水线操作特性的。5级流水线中提前1级来读取指令操作数,得到的值是不同的(PC+4而不是PC+8)。这产生的代码不兼容是不容许的。但5级流水线ARM完全仿真3级流水线的行为。在取指级增加的PC值被直接送到译码级的寄存器,穿过两极之间的流水线寄存器。下一条指令的PC+4等于当前指令的PC+8,因此,未使用额外的硬件便得到了正确的r15。 3.6级流水线ARM组织 在ARM10中,将流水线的级数增加到6级,使系统的平均处理能力达到了1.3Dhrystone MISP/MHz。图2.9显示了6级流水线上指令的执行过程。 图2.9 6级流水线 2.2.3 影响流水线性能的因素 1.互锁 在典型的程序处理过程中,经常会遇到这样的情形,即一条指令的结果被用做下一条指令的操作数。如例2.4所示。 【例2.4】 有如下指令序列: LDR r0,[r0,#0] ADD r0,r0,r1 ;在5级流水线上产生互锁 从例2.4中可以看出,流水线的操作产生中断,因为第一条指令的结果在第二条指令取数时还没有产生。第二条指令必须停止,直到结果产生为止。 2.跳转指令 跳转指令也会破坏流水线的行为,因为后续指令的取指步骤受到跳转目标计算的影响,因而必须推迟。但是,当跳转指令被译码时,在它被确认是跳转指令之前,后续的取指操作已经发生。这样一来,已经被预取进入流水线的指令不得不被丢弃。如果跳转目标的计算是在ALU阶段完成的,那么,在得到跳转目标之前已经有两条指令按原有指令流读取。 解决的办法是,如果有可能最好早一些计算转移目标,当然这需要硬件支持;如果转移指令具有固定格式,那么可以在解码阶段预测跳转目标,从而将跳转的执行时间减少到单个周期。但要注意,由于条件跳转与前一条指令的条件码结果有关,在这个流水线中,还会有条件转移的危险。 尽管有些技术可以减少这些流水线问题的影响,但是,不能完全消除这些困难。流水线级数越多,问题就越严重。对于相对简单的处理器,使用3~5级流水线效果最好。 显然,只有当所有指令都依照相似的步骤执行时,流水线的效率达到最高。如果处理器的指令非常复杂,每一条指令的行为都与下一条指令不同,那么就很难用流水线实现。


- 流水线处理技术在数据集成中的应用(03-11)
- DSP设计中的流水线数据相关问题及解决办法(06-11)
- 流水线技术在编程器中的提速应用(06-30)
- FPGA系统设计原则和技巧之:FPGA系统设计的3种常用技巧(06-05)
- 基于FPGA的Canny算法的硬件加速设计(06-05)
- 基于FPGA的流水线结构DDS多功能信号发生器的设计与实现(06-05)