基于FPGA的Canny算法的硬件加速设计
0 引言
边缘检测是图像分析过程中非常基础和重要的研究领域,边缘提取的好坏将直接影响到后续处理的准确性和难易程度。用于边缘检测的方法有Roberts,Sobel,Laplace,Canny,PreWitt等众多算法。在这些算法当中,由于具有良好的边缘检测能力而使得Canny算法在数字图像处理中得到了广泛的应用。然而由于计算量的庞大,处理的时间又比较长,往往很难满足系统的要求。因为FPGA对数据的并行处理,能达到系统的实时性要求,且开发的周期短,采用电子设计的EDA技术使得开发、调试和验证更为直接和简单可行。
本文在FPGA基础上研究Canny算法的边缘检测,并对它进行了加速改进,且在数据处理过程中使用了流水线设计,更深入地挖掘了FPGA在数据处理速度中的优势。仿真实验证明了该方法的可行性,并且实现了良好的实时性。
1 Canny算子的边缘检测
边缘是指在其周围像素灰度有明显变化的那些像素的组合,它是具有幅值和方向的矢量,在图像中表现为灰度的突变。早在1986年Canny就提出了边缘检测应该满足的三个最优准则:
(1)重要的边缘不能丢失,没有虚假的边缘,并且误差检测率是最小的。
(2)实际边缘与检测到的边缘位置之间的变差最小。
(3)对单一边缘应具有惟一的响应。
Canny算子首先使用高斯滤波器来平滑图像,再计算图像梯度的强度和方向,接着对梯度图像进行非极大值抑制,最后采用双阈值方法从候选边缘点中检测和连接边缘。
1.1 Canny算子原理
Canny算子是把边缘检测问题转换为函数极大值的问题加以处理。提取边缘首先要进行高斯滤波,其目的是对原始图像进行平滑处理,以减弱或除去图像中的噪声。其高斯滤波的基本思想是将一个对称的二维高斯函数与原始的图像做卷积运算,再沿其梯度方向做微分,这样就形成了一个简单且有效的方向算子。
f(x,y)为原始图像,G(x,y)是二维高斯函数,则平滑滤波后的图像I(x,y)为:
I(x,y)=G(x,y)*_f(x,y) (1)
定义方向n为边缘方向的法向方向,则n可由下式得出: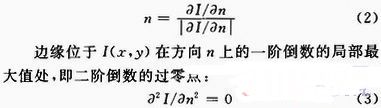
式(3)说明了如何寻找局部最大值,在非极大值抑制之后,还要通过阈值化处理来寻找极大值。先设定一低阈值Th1,然后选取高阈值Th2≈2*Th1,将极大值抑制后的图像按Th1,Th2进行两次阈值化处理,得到图像T1和T2。由于图像T2是通过高阈值得到的,噪声和伪边缘很少,但也造成了一些真实边缘信息的丢失;而图像T1保留的边缘信息相对全面,但是存在一些虚假的边缘信息。所以以图像T2为基础,图像T1为补充可以获得相对全面的边缘图像。
1.2 算法的模板
本文算法中的高斯滤波器和梯度强度计算时都采用3×3的方形移动窗口,同时梯度强度计算选用Sobel算子。在对图像进行平滑处理时,需要使用高斯模板与原图像中的像素点值做矩阵的卷积运算。本文选取高斯模板的模板系数为0.062 5,且σ=1。模板如下所示:
式中:h为水平方向上的模板;v为垂直方向上的模板。h与图像做卷积得到水平方向上的梯度强度Ex;v与图像做卷积得到垂直方向上的梯度强度Ev。然后通过式(4)计算梯度强度Gr为:
Gr=|Ex|+|Ey| (4)
在FPGA中,卷积的运算是通过移位和加法来实现的。对于8位的图像来说,在移位和加法的运算中,由于存在正负号的运算,像素值的大小会被调整为11位,在最后做完绝对值的加法运算后要把11位缩回8位并得到最终的像素导数值。
2 加速功能设计
本文对图像的快速处理采用了流水线技术。所谓流水线技术是把规模较大、层次较多的组合逻辑电路分为几个级,在每一级插入寄存器组并暂存中间数据。对于每个步骤只依赖于前面步骤的运算结果的顺序处理来说,流水线技术能大大地提高系统的性能。在本文的算法中,可将处理过程分为以下几个任务:图像平滑、梯度计算、非极大值抑制和图像边缘判定检测。任务与任务之间都是顺序执行的,即就是说下一任务的执行需要上级任务的结果输出数据,因此总的时间花销为各个任务所需时间的总和。要使系统使用的处理时间最小,也就是使每个任务所花费的时间最短。
2.1 加速器设计实现
本文使用了一种能运用于高斯平滑滤波和梯度计算的加速器的数据路径结构。由于这两种计算过程均采用相同大小的方形移动窗口,故其加速设计具有极大的相似性。对此,这里选取3×3的Sobel模块来解释说明。
Sobel的加速数据结构如图1所示。它是一个具有以下功能的流水线:先从原始的图像中读取像素值存入图中右方的3组12寄存器中,数据流过中间的3×3的乘法器阵列,即像素值与模板值做乘法运算;然后向下流过加法器,在加法器中完成和运算,至此实现了像素值与模板的卷积运算,之后到达Ex和Ey寄存器,通过绝对值电路和加法器(实现式(4))到达寄存器,最终流入最下面的寄存器。图中负号表示取反,数值1和2表示右移的位数。
为使得加速器能够有序地按照确定的步骤进行,本文使用了有限状态机。如图2所示为加速器的简单状态转换图。在加速器的执行过程中,当检测到3组寄存器中的数据为空时,读信号使能re_en置1,自动读入新的3组数据;且在下方寄存器存储满时,写信号使能wr_en置1,数据被提取进行写操作。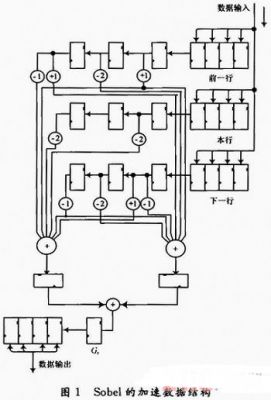
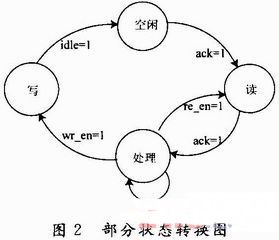
在加速器的执行过程中,像素每4个为一组进行读写,这样在高速处理过程中大大缩减了对相同像素点的多次重复读取而浪费的时间;同时,在处理过程中不需要在处理每个像素点时都对其邻域的8个像素点更新,这样节省了大量的读取时间;并且由于FPGA的并行特性,像素的读、移位及写操作和乘法器的运算是同时进行的,使得处理速度有一定的提升。
2.2 加速器的地址产生
在系统的连续处理过程当中,加速器没有专门的等待时间用来对数据进行读取和存储,这两类运算都是并行进行的。因此加速器需要具有自动选通的读/写地址电路。对于一幅512×512图像来说,从偏移值0开始计数,一次加1,以便于从内存中读一组4个像素值,把偏移地址和基地址加起来形成前一行的像素地址,把它加上512/4就形成当前行的读地址,再加上1 024/4就形成了下一行的读地址。对于写地址来说,从偏移值512/4开始计数,一次加1形成每次的写地址。地址发生器的部分代码如下:
- 流水线技术在编程器中的提速应用(06-30)
- 基于DSP的嵌入式显微图像处理系统的设计(06-28)
- 基于PCI总线和DSP芯片的图像处理平台的硬件设计(07-06)
- 超级图像编解码技术(Scalado)(01-01)
- 基于FPGA的多DSP红外实时图像处理系统(01-21)
- 一种新型的多DSP红外实时图像处理系统设计(02-03)