ARM体系结构之:流水线
2.2 流水线
2.2.1 流水线的概念与原理
处理器按照一系列步骤来执行每一条指令。典型的步骤如下:
① 从存储器读取指令(fetch);
② 译码以鉴别它是属于哪一条指令(dec);
③ 从指令中提取指令的操作数(这些操作数往往存在于寄存器中)(reg);
④ 将操作数进行组合以得到结果或存储器地址(ALU);
⑤ 如果需要,则访问存储器以存储数据(mem);
⑥ 将结果写回到寄存器堆(res)。
并不是所有的指令都需要上述每一个步骤,但是,多数指令需要其中的多个步骤。这些步骤往往使用不同的硬件功能,例如,ALU可能只在第4步中用到。因此,如果一条指令不是在前一条指令结束之前就开始,那么在每一步骤内处理器只有少部分的硬件在使用。
有一种方法可以明显改善硬件资源的使用率和处理器的吞吐量,这就是当前一条指令结束之前就开始执行下一条指令,即通常所说的流水线(Pipeline)技术。流水线是RISC处理器执行指令时采用的机制。使用流水线,可在取下一条指令的同时译码和执行其他指令,从而加快执行的速度。可以把流水线看作是汽车生产线,每个阶段只完成专门的处理器任务。
采用上述操作顺序,处理器可以这样来组织:当一条指令刚刚执行完步骤①并转向步骤②时,下一条指令就开始执行步骤①。图2.1说明了这个过程。从原理上说,这样的流水线应该比没有重叠的指令执行快6倍,但由于硬件结构本身的一些限制,实际情况会比理想状态差一些。
2.2.2 流水线的分类
从Acorn Computer公司在1983~1985年间开发的第一个3µm器件,到ARM公司在1990~1995年间开发的ARM6和ARM7,ARM整数处理器核的组织结构变化很小,这些处理器都是采用3级流水线,而这一时期CMOS工艺的发展,几乎将特征尺寸减少了一个数量级。因此,核的性能提高很快,但基本的操作原理大部分没有变化。
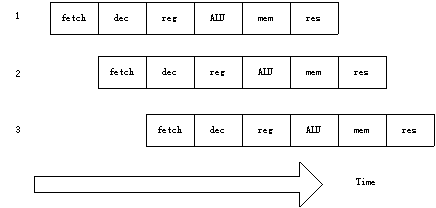
图2.1 流水线的指令执行过程
从1995年以来,ARM公司推出了几个新的ARM核。它们采用5级流水线和哈佛架构,获得了显著的高性能。例如,ARM9增加了存储器访问段和回写段,这使得ARM9的处理能力可达到平均1.1 Dhrystone1 MISP/MHz,与ARM7相比,指令吞吐量提高了约13%。
| | 注意 | 在许多高性能处理器内部,一级Cache一般都设置有两个,其中,一个是指令Cache,另一个是数据Cache。这样可以减少取指令和读操作数的访问冲突,这种结构被称为哈佛架构。 把主存储器分成两个独立编址的存储器,一个专门存放指令,称为指令存储器,简称指存;另一个专门存放操作数,称为数据存储器,简称数存。两个存储器可以同时访问,这样就解决了取指令和读操作数的冲突。如果在此基础上规定在执行指令阶段产生的运算结果只写到通用寄存器中,不写到主存,那么取指令、分析指令和执行指令就可以同时进行。 |
ARM10更是把流水线增加到6级。ARM10的平均处理能力达到1.3 Dhrystone MISP/MHz,与ARM7相比,指令吞吐量提高了约34%。
| | 注意 | 虽然ARM9和ARM10的流水线不同,但它们都使用了与ARM7相同的流水线执行机制,因此ARM7上的代码也可以在ARM9和ARM10上运行。 |
1.3级流水线ARM组织
3级流水线ARM组织如图2.2所示,其主要的组成如下:
① 处理器状态寄存器堆(Rigister Bank)。它有两个读端口和一个写端口,每个端口都可以访问任意寄存器。另外还有附加的可以访问PC的一个读端口和一个写端口。
| | 注意 | PC的附加写端口可以在取指地址增加后更新PC,读端口可以在数据地址发出之后从新开始取指。 |
② 桶形移位寄存器(Barrel Shifter)。它可以把一个操作数移位或循环移位任意位数。
③ ALU。完成指令集要求的算术或逻辑功能。

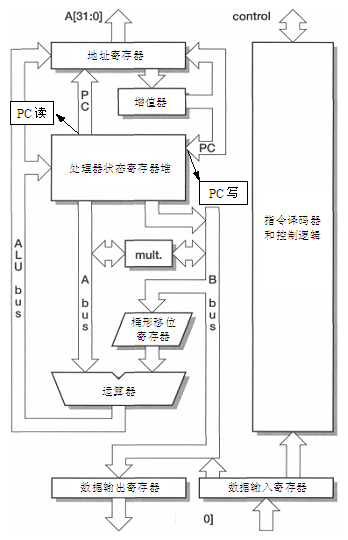
图2.2 3级流水线ARM的组织
④ 地址寄存器(Address Register)和增值器(Incrementer)。可选择和保存所用的存储器地址并在需要时产生顺序地址。
⑤ 数据输出寄存器(data-out register)和数据输入寄存器(data-in register)。用于保存传输到存储器和从存储器输出的数据。
⑥ 指令译码器和相关的控制逻辑(instruction decode and control)。
例2.1显示了一条单周期指令在流水线上的执行过程。
【例2.1】
ADD r1,r2
指令在流水线上的执行过程如图2.3所示。
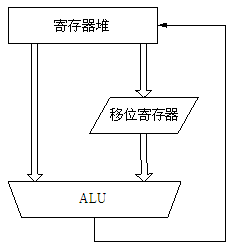
图2.3 单周期指令在流水线上的执行过程
在ADD指令中,需要访问两个寄存器操作数,B总线上的数据移位后与A总线上的数据在ALU中组合,再将结果写回寄
- 流水线处理技术在数据集成中的应用(03-11)
- DSP设计中的流水线数据相关问题及解决办法(06-11)
- 流水线技术在编程器中的提速应用(06-30)
- FPGA系统设计原则和技巧之:FPGA系统设计的3种常用技巧(06-05)
- 基于FPGA的Canny算法的硬件加速设计(06-05)
- 基于FPGA的流水线结构DDS多功能信号发生器的设计与实现(06-05)