TMS320C55x DSP并行处理技术分析与应用
时间:11-22
来源:作者:周渝陇 申敏 赵春雨
点击:
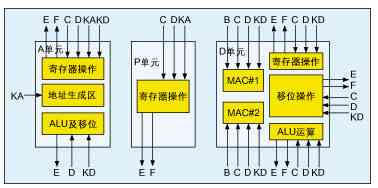
采用双重AR间接寻址方式,可以通过使用2个不同的辅助寄存器(AR0~AR7)同时访问数据存储区中两个不同的数据。在这种寻址方式下,我们可以通过两条不同的数据总线,在同一时钟周期内寻址两个不同数据,并将其输入不同的运算模块进行计算。
常用并行处理应用
在编程实现过程中,对每一个并行处理都进行仔细分析将能达到事半功倍的效果。下面是我们总结出的几种典型并行处理应用:
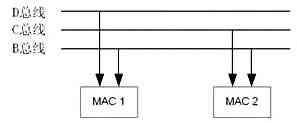
1. D单元双MAC结构的并行处理
在C55x DSP的D单元中采用了双MAC的结构,其结构如图4所示。这里有3条数据总线(B、C、D数据总线)与两个MAC模块相连。在同一时钟周期里,可以同时通过3条数据总线将三个不同地址的数据传入两个MAC模块中进行并行计算。[next]
通常情况下,两个MAC模块的运算总共需要4个数据,而这里的总线数却只有3条,所以在并行使用双MAC结构时,两个MAC模块必须共用一组数据,而另外两组数据分别分配给两个MAC模块。这使得双MAC结构的并行应用受到一定的限制。
C55x的双MAC结构比较典型的应用如不同数据的相同算法处理和同一数据的不同算法处理。下面是对不同数据进行相同FIR滤波的实例:
MAC *AR0+,*CDP+,AC0
::MAC *AR1+,*CDP+,AC1
其中AR0和AR1寄存器分别指向输入的两组数据,CDP寄存器指向FIR滤波器的抽头系数。C55x DSP的指令集中还含有其它与双MAC模块并行处理的专用指令,在此就不再仔细分析。
2. 存储区数据装载指令与存储指令的并行
A单元、P单元和D单元均可以对存储器中数据实现装载及存储。数据的装载与存储使用的是不同总线,不会发生硬件冲突,易于实现并行处理。以下是在D单元内实现两个数据装载与存储的实例:
MOV AC0,*AR1
||MOV *AR2,AC1
此例是在D单元内对AC0进行存储并装载数据到AC1。程序执行时,将数据通过D总线读入AC1寄存器,同时将AC0数据通过E总线写入存储器,这样就避免了硬件冲突,满足并行规则1。两条指令总长度为4字节,小于IBQ6个字节的限制,满足了并行规则2。两条指令均采用双重间接寻址,满足了并行规则3。通过上机调试,这条并行指令确实能够正确编译并执行。
3. A单元中ALU运算与D单元中ALU、MAC和移位运算的并行
下面我们以一个实例来进行说明:
ADD T0,AR1
||MOV HI(AC0<<#18),*AR2
这是一个A单元ALU模块与D单元移位操作模块的并行处理实例。它在A单元完成16位加法运算,并将结果存放于AR1,同时在D单元完成对寄存器AC0的移位存储操作。这两条指令之间不存在硬件冲突,满足并行规则1。两条指令总共长度为5个字节,小于IBQ6个字节的限制,满足了并行规则 2。这里只使用了一个储器中的数据,不需要满足并行规则3的规定。通过上机调试,这条并行指令能够正确编译并执行。
4. 累加器的移位、饱和及存储操作与D单元ALU或MAC的并行处理
下面我们以一个实例来进行说明:
MOV HI(AC0<<#18),*AR2
||ADD AC0,AC1
这是一个D单元移位操作模块与D单元ALU模块的并行处理实例。它在移位操作模块中完成寄存器AC0的移位,然后将移位后的值通过E总线存储到存储器中,同时在ALU模块中完成寄存器AC0与AC1的加法运算,然后将结果存放于AC1。这两条指令不存在硬件冲突,满足并行规则1。两条指令总长度为5个字节,小于IBQ6字节的限制,满足并行规则2。这里只需使用一个存储器中的数据,不需满足并行规则3。通过上机调试,这条并行指令能够正确编译并执行。
5. 程序控制操作与运算操作的并行
P单元程序控制模块与其他的算术运算模块相对较独立,不易发生硬件冲突,便于进行并行处理。下面是一个程序控制指令与算术运算指令的并行:
ADD *AR2,AC0
||RPTBLOCAL JUMP1 这是一个D单元ALU模块与P单元程序控制模块的并行实例。它在D单元ALU中将D总线送来的数据与AC0相加并存入AC0,同时完成程序循环控制。程序执行中不存在硬件模块和总线的冲突,满足并行规则1;两条指令总长度为5字节,满足并行规则2;此例只使用一个存储器中的数据,不需要满足并行规则3。通过上机调试,这条并行指令能够正确编译并执行。
6. 使用常量对存储器进行初始化
D单元拥有两条写总线(E、F总线),在通常情况下我们只使用了其中的一条写总线造成资源浪费。假如我们需要对某块数据存储区清零,通常的做法如下:
RPT #9
MOV #0,*AR1+
这段程序对存储区数据逐一清零,每次只使用了D单元的E总线,总共需要10个时钟周期才能完成。在这种情况下,如果我们充分利用E、F总线,将有效地降低这段程序的运算量。具体实现如下:
MOV #0,AC0
||RPT #4
MOV AC0,DBL(*AR1+)
这段程序与上一段的最大不同点在于,一个时钟周期内通过E、F总线将两个初始数据同时传送到指定的数据区,同时初始化两个字的存储空间。这段程序只需要5个时钟周期就可以完成10个字的初始化,比普通做法节约一半的运算量,提高了使用效率。
- TI基于低功耗TMS320C5515 DSP的解决方案(02-15)
- 基于TMS320C5515设计的心电图(ECG)MDK开发技术(08-23)
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)