基于DSP的宽带雷达多片流水分段脉压处理平台设计
时间:08-02
来源:作者:王国庆,申俊杰,张旭峰
点击:

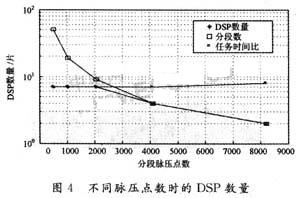
为了评价基于DSP的多片流水分段脉压设计的并行程度,在这里引用加速比(Accelerate Ratio)和并行效率的概念。可以定义NDSP个DSP处理器的加速比为:

可以看出,并行效率与加速比是密切相关的,Sp越接近于NDSP,Ep越接近于1。实际上,影响多片流水分段脉压设计并行效率的因素是多方面的,我们应该综合考虑流水操作时总的脉压时间、参与多片流水的DSP数量、加速比以及并行效率等各项指标,以尽可能达到多片流水分段脉压的最优设计。
根据式(2)~式(5),结合某宽带雷达参数,给出不同分段脉压点数d时的流水操作时总的脉压时间Tpip、参与多片流水的ADSP-TS101数量NDSP,加速比Sp以及并行效率Ep等指标,详见表1。
4 硬件平台设计实现
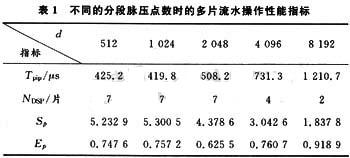
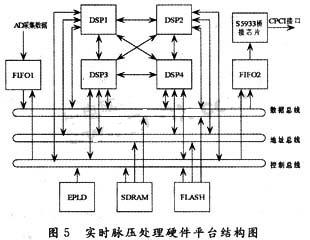
本文设计的实时脉压处理硬件平台是一块由4片ADSP-Ts101构成的6U CPCI前面板,结构如图5所示。DSP1,DSP2,DSP3,DSP4采用共享总线结构和MeshSP结构相结合的方式,构成板上的多片流水分段脉压并行运算模块。4片DSP在通过集成于芯片内部的发布式总线仲裁逻辑共享总线的同时,还通过Link口构成了两两互连的网格结构,这样充分发挥ADSP-TS101芯片的并行处理能力的优势。两种并行计算结构的结合,既减少了处理器对总线的竞争,又大大增强了处理器问的数据交换能力。数据总线和地址总线上连接存放程序代码的FLASH芯片和作为外部存储的SDRAM芯片,能够满足系统对大批量数据的处理需求。


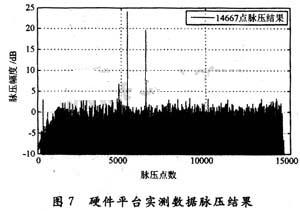
雷达回波数据经过脉压处理之后,由CPCI总线接口传输给计算机,通过Matlab软件将脉压结果显示如图7所示。经过实测,整个脉压处理过程从数据输入到脉压结果输出共耗时约780μs。完全满足脉冲重复周期(PRT)1 ms的要求。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)