一种基于DSP平台的快速H.264编码算法的设计
视频压缩编码标准H.264/AVC是由ISO/IEC和ITU-T组成的联合视频专家组(JVT)制定的,他引进了一系列先进的视频编码技术,如4×4整数变换、空域内的帧内预测,多参考帧与多种大小块的帧间预测技术等,标准一经推出,就以其高效的压缩性能和友好的网络特性受到业界的广泛推崇。特别是在2004年7月JVT组织做了重要的保真度范围扩展的补充后,更加扩大了标准的应用范围,但同时巨大的运算量却成为其广泛应用的瓶颈。考虑到H.264协议实现的复杂度,本文的思路是:一方面提高硬件处理速度和能力,采用TI公司最新的数字媒体处理器Davinci TMS320DM6446 DSP芯片作为H.264编码器实现的硬件开发平台,另一方面提高算法效率。最后提出一个基于这个芯片的嵌入式H.264编码器的设计方案。
1 硬件平台
1.1 Davinci DM6446芯片介绍
DM6446采用DSP+ARM的双内核结构(内核图见图1),其中的DSP芯片的CPU时钟频率可达594 MHz,ARM的引入可以释放DSP在控制方面的部分功能,使DSP专门进行数据处理的工作。芯片采用增强型的哈佛结构总线,其CPU内部有2个数据通道,8个32 b的功能单元,2个通用寄存器组(A和B),可同时执行8条32 b长指令。如果能充分利用这8个功能单元,总字长为256 b的指令包同时分配到8个并行处理单元,在完全流水的情况下,该芯片的指令吞吐量将达到594×8=4 752 MIPS。处理器具有双16 b扩充功能,芯片能在一个周期内完成双16 b的乘法、加减法、比较、移位等操作。该芯片内部支持两级Cache,其中第一级32 kB的程序缓存器L1P,80 kB的数据缓存器L1D,而第二级的Cache大小是可配置的64 kB,芯片自动完成这两级Cache之间数据一致性的维护。有了这两级Cache的支持将使CPU的执行速度大大加快。 
Davinci DM6446具有专用的视频图像处理子系统。视频处理子系统包括1个视频前端和1个视频末端,视频前端的输入接口用于接受外部传感器或视频译码器输出的BT.656等图像输入信息;视频末端输出接口输出图像,实现图像本地重现。
视频前端输入(VPFE)接口由1个CCD控制器(CCDC),1个预处理器,柱状模块,自动曝光/白平衡/聚焦模块(H3A)和寄存器组成。CCD控制器可以与视频解码器CMOS传感器或电荷耦合装置连接。预处理器是一个实时的图形处理器。
1.2 H.264编码器硬件平台
本系统的平台核心处理芯片为Davinci DM6446,如图2所示,片外RAM选取两片DDR并联成32位的数据宽度,空间为256 MB。模拟视频信号在"VIDEO IN"引入后经过解码芯片TVP5146变换为数字信号后输入TMS320DM6446芯片中进行处理,H.264编码处理后的码流可以通过视频末端输出保存在本地硬盘上,以方便调试检查。或者可以通过10/100 M以太网物理层接口输出,进行网络传输。同时,本地的重构图像可以通过TMS320DM6446芯片内部OSD模块和编码模块D/A变换后直接显示输出。 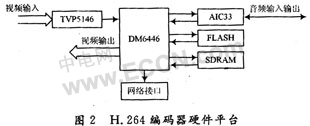
2 H.264编码器结构与编码流程
2.1 H.264编码器结构
如图3所示输入的图像以宏块为单位进入编码器中,根据图像变化的快慢选择帧内或帧间预测编码。如果选择帧内预测编码,首先判断当前待编码块中是否包含很多的细节,再决定是否要把帧进行再分割。接着以重建帧μF′n中的块为参考,结合当前块周围块的预测模式,选择当前块的最佳预测模式。最后由重建帧μF′n中相应块和当前块选定的预测模式得到当前块的预测值。按照上述方法,对图像中的每一宏块作出帧内预测,进而得到一帧图像的预测值P。如果选择帧间预测编码,当前输入帧Fn和前一帧(参考帧)Fn-1被送到运动估计器(ME),通过块搜索,匹配可以得到当前帧中的各宏块相对于参考帧中对应宏块的偏移量,也就是常说的运动矢量。接着,参考帧Fn-1和刚得到的运动矢量MV被送到运动补偿器(MC),通过计算得到帧间预测值P;当前帧Fn和帧预测值P相减,得到残差Dn,经过变换,量化后产生一组量化后的变换系数X,再经过熵编码,与解码所需的一些边信息(如预测模式量化参数,运动矢量等)一起组成一个压缩后的码流,经NAL(网络自适应层)供传输和存储。 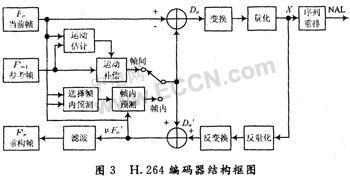
2.2 编码器编码流程
如图4所示为H.264编码器主流程。对输入的一帧图像首先进行单元划分:以宏块为基本单元进行划分,再由若干宏块在组合成Slice,由Slice再组合成Slice Group,这样每个宏块所属的Slice和Slice Group也就确定了。再判断输入的一帧图像是I-Frame还是P-Frame。在以上工作完成后,也就可以对每个宏块进行编码了。在对每个宏块都编码完成后,还需要对重构图像进行1/4象素精度插值处理、参考帧缓冲区插入处理等工作。至此,编码一帧的工作才算完成。 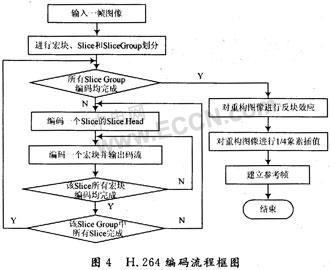
3 运动估计模式快速率失真决策
为了减少图像序列的时间冗余,达到更好压缩效果的目的,H.264/AVC编码方案采用运动补偿技术和预测。即由先前已编码的一个或多个帧产生当前编码帧的一种预测模式,然后再进行预测编码。且采用了一种可变块尺寸的运动预测模式,亮度块尺寸的范围从16×16变化到4×4,其中包含很多可选模式,形成了一种树形结构的运动预测。对于I帧(包含帧内4×4、帧内16×16),对P帧(包含帧内4×4、帧内16×16、SKIP模式、帧间16×16、帧间16×8、帧间8×16、帧间8×8、帧间8×4、帧间4×8)同时还为P帧和B帧提供了特殊的SKIP模式,总共11种模式。这些可选模式的存在使得编码方式更加灵活,编码精度相对于固定尺寸块预测要高很多。然而,可选的帧问预测模式增加了,必然会使得运算复杂度增加,因此有必要采用一种高效的决策方法来选取块尺寸组合方式,使得编码效率和编码质量均佳。
3.1 拉各朗日代价函数
引入拉各朗日代价函数如下:
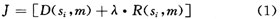
其中D表示重构恢复图像相对于原始图像间的失真;R(si,m)表示对宏块编码后数据及相关参数在码流中所占用的比特数,一般由编码统计得到,但对于SKIP模式,比特数默认为1比特;λ表示模式选择时所使用的拉各朗日乘积因子。
对于运动估计,可使用拉各朗日代价函数作为选择运动矢量的判决标准。根据式(1)得到对一个采样块si进行ME判决的代价函数为下:
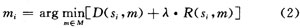
该式返回产生最小代价值的最佳匹配运动矢量mi,其中M指各种可能编码模式的集合,m为当前选定模式,式(2)中R(si,m)是运动矢量(mx,my)所要传输(按熵编码)的比特数。D(si,m)表示对图像宏块的预测误差,对于该预测误差的计算有两种方案:当预测误差选择是绝对误差时用(SAD)表示,如式(3);当预测误差选择是平方差时,则用SSD表示,如式(4)中:
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)