DSP接口效率的分析与提高
1多个外设的情况
当DSP与低速器件接口时,可以通过设置DSP片内的等待状态产生控制寄存器(WSGR),在相应的程序空间、数据空间或I/O空间产生1~7个等待周期,以使DSP的访问速度能和低速器件相匹配。当在同一空间内既有低速器件又有高速器件时,通常WSGR的延时值被设置成与速度最慢的器件相一致,以保证DSP对所有的器件都能进行正确的访问。若对高速器件的操作很频繁,则这种对整个空间的延时将极不合理地降低系统速度。例如,有些系统在数据空间同时扩展有RAM和ROM。而ROM的速度一般远远低于RAM,其访问周期一般为100~200ns,即使DSP和RAM的访问速度均可达到25ns,但对整个数据空间进行延时后,DSP也只能以ROM的访问速度(100~200ns)对RAM进行访问。在这种情况下,首先应考虑使用软件方法提高效率。其方法是在默认的情况下将WSGR设置成与高速器件一致,当要访问低速器件时再修改WSGR的值。DSP常常对外部器件进行连续操作,在这种情况下,软件方法还是比较有效的。但最大问题在于增加了软件负担和不稳定因素。显然,效率最高的情况是,既不需要修改WSGR,DSP又能以外部器件本身的速度对它们进行访问。事实上,只要能够产生适当的信号控制DSP的READY端,就可以达到这个目的。DSP在开始一个外部总线的操作后,会在每一个CLKOUT信号(DSP的时钟输出)的上升沿时刻对READY端进行查询,若READY为低,则保持总线的状态不变,然后在下一个CLKOUT上升沿时刻再次查询,直至查询到READY为高时结束本次总线访问。下面的设计实例中介绍的硬件等待电路(见图1)能够实现这个功能。它针对不同的外部器件产生相应的等待信号送到DSP的READY端,实现硬等待。其核心器件采用了广泛应用的通用逻辑阵列(GAL),GAL的引脚定义与图1相对应。使用GAL器件使硬件设计变得简单而灵活,可以完成比较复杂的逻辑关系。
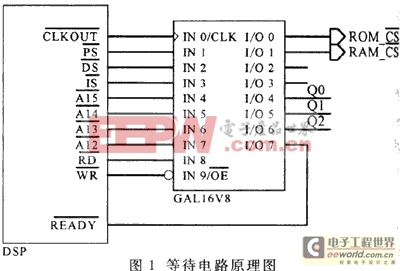
例如,频率为50MHz的DSP在数据空间外扩有RAM和ROM各一片,访问周期分别为70ns和150ns,地址空间分别为0x8000~0x8fff和0x9000~0x9fff。由DSP的主频可知,对RAM和ROM的访问各需插入3个和7个等待周期。下面给出GAL源文件的关键部分(它们使用汇编程序FM的格式编写):Q0:=/Q0*/RD+/Q0*/WR
Q1:=/Q0*Q1*/RD+Q0*/Q1*/RD+/Q0*Q1*/WR
+Q0*/Q1*/WR
Q2:=/Q1*Q2*/RD+/Q0*Q1*Q2*/RD+Q0*Q1*/Q2*/RD
+/Q1*Q2*/WR+/Q0*Q1*Q2*/WR+Q0*Q1*/Q2*/WR
;构成一个三位的二进制计数器
;Q2为最高位、Q0为最低位
;对读信号或写信号的宽度进行计数
GAL_READY.OE=VCC
/GAL_READY=/DS*A15*/A14*/A13*/A12*/Q1
+/DS*A15*/A14*/A13*/A12*Q1*/Q0
;为RAM的访问插入3个周期
+/DS*A15*/A14*/A13*A12*/Q0
+/DS*A15*/A14*/A13*A12*/Q1
+/DS*A15*/A14*/A13*A12*/Q2
;为ROM的访问插入7个周期
图2是一个与写时序对应的时序图,其中在下三角符号标出的时刻,DSP对READY端进行查询。
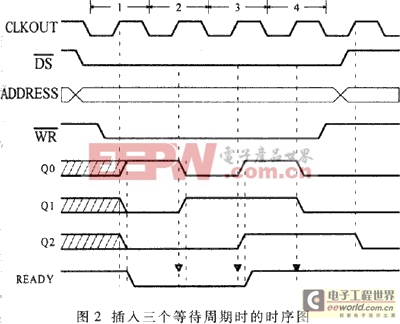
这种方法能够充分使用硬件的速度,并且对软件是透明的,不会增加编程人员的负担。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)