linux UART串口驱动开发文档
= 0) {
for (i = 0; i UART_NR; i++)
uart_add_one_port(amba_reg, amba_ports[i].port);
}
return ret;
}
二. Linux的中断机制及中断共享机制.
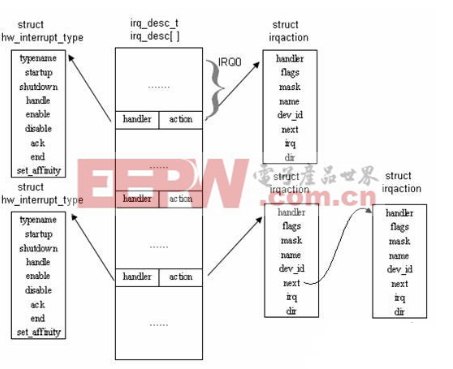
前面讲到了有6个串口,除了w83697中的前三个串使用的是独立的系统外部中断之外,其它的在个串口是共享一个系统中断向量的,现在我们来看看多个中断是如何挂在一个系统中断向量表当中的,共享中断到底是什么样的一种机制?
进行分析代码可知,linux下的中断采用的是中断向量的方式,每一个中断对应一个中断描述数组当中的一项, 结构为struct irqdesc,其当中对应一成员结构为struct irqactionr 的成员action, 这个即表示此中断向量对应的中断处理动作,这里引用从网上下载的一幅图讲明中断向量表与中断动作之间的关系:
struct irqaction {
void (*handler)(int, void *, struct pt_regs *);
unsigned long flags;
unsigned long mask;
const char *name;
void *dev_id;
struct irqaction *next;
};
从上面的结构体与图当中,我们就可以很清楚的看到,一个中断向量表可以对应一个irqaction,也可能对应多个由链表链在一起的一个链表irqaction, 这当中主要在安装中断的时候通过中断的标志位来决定:
安装中断处理,不可共享:
retval = request_irq(port->irq, w83697uart_int, 0, w83697_uart3, port);
安装中断处理,可共享:
retval = request_irq(port->irq, w83697uart_int2, SA_SHIRQ, w83977_uart5, port);
由上即可知,安装共享中断时,只须指定安装的中断标志位flag为SA_SHIRQ, 进入分析安装中断的处理可知,在安装时,会检测已经安装的中断是否支持共享中断,如果不支持,则新的中断安装动作失败;如果已经安装的中断支持共享中断,则还必须检测将要安装的新中断是否支持中断共享,如果不支持则安装还是会失败,如果支持则将此新的中断处理链接到此中断向量对应的中断动作处理链表当中.
在产生中断时,共享中断向量中对应的中断处理程序链表中的每一个都会被调用,依据链表的次序来,这样处理虽然会有影响到效率,但是一般情况下中断传到用户的中断处理服务程序中时,由用户根据硬件的状态来决定是否处理中断,所以能常情况下都是立即就返回了,效率的影响不会是大的问题.
三. Linux的软中断机制.
前面已经简单讲过了LINUX下的硬中断处理机制,其实硬中断的处理都由LINUX底层代码具体完成了,使用者一般在处理硬中断时是相当简单的,只须要用request_irq()简单的挂上中断即可,这里我们进一步介绍一下LINUX下的软中断机制,软中断机制相比起硬中断机制稍微复杂一些,而且在LINUX内核本身应用非常的广, 它作为一种软性的异步执行机制,只有深入理解了它才能灵活的运用.
之所以提到内核的softirq机制,主要是因为在串口中断也使用了这些机制,理解了这些机制就能更加明白串口驱动一些问题, 现在先提出几个问题如下:
前面提供到中断接收后数据,先放到flip缓冲区当中,这样让人很容易进一步想知道,中断处理的缓冲区的数据,用户进程读取串口时如何读到的?很明显中断处于内核空间,用户读取串口输入进程是在用户空间,中断缓冲区中的数据如何被处理到终端缓冲区中,供用户读取的?
另外写串口时,是向终端缓冲区当中写入,那么上层的写操作如何知道下层缓冲区中的的数据是否传送完成?用户空间的写串口进程处于什么样的状态?如果是写完缓冲区就睡眠以保证高效的CPU使用率,那么何时才应该醒过来? 由谁负责醒过来?
1. 往tq_timer任务队列中添加一项任务.
根据以上这两个问题,我们来深入代码分析,首先看接收缓冲区中的数据如何上传, 前面已经提到过,接收中断处理完成后,会调用tty_flip_buffer_push(),这个函数完成的功能就是往一系统定义的任务队列当中加入一个任务,下面我们将详细的分析加入的任务最终是如何执行起来的.[任务:这里所讲的任务可以直接理解成为一个相应的回调函数,LINUX下术语称作tasklet]
void tty_flip_buffer_push(struct tty_struct *tty)
{
if (tty->low_latency)
flush_to_ldisc((void *) tty);
else
queue_task(tty->flip.tqueue, tq_timer);
}
2. tq_timer的执行路径分析.
tq_timer是一个双链表结构任务队列,每项任务包含一个函数指针成员, 它通过run_task_queue每次将当中的所有任务(其实是一些函数指针)全部调用一次,然后清空队列, 最终的执行tq_timer的是在中断底半的tqueue_bh 中执行,如下:
void tqueue_bh(void)
{
run_task_queue(tq_timer);
}
在void __init sched_init(void)当中初始化底半的向量如, tqueue_bh初始化
- 嵌入式软件设计中查找缺陷的几个技巧(03-06)
- 基于算法的DSP硬件结构分析(04-02)
- Windows CE下驱动程序开发基础(04-10)
- DSP+FPGA在高速高精运动控制器中的应用(05-17)
- 基于USB接口和DSP的飞机防滑刹车测试系统设计(05-19)
- 一种基于DSP平台的快速H.264编码算法的设计(05-19)