ARM big.LITTLE系统技术应用
摘要:详述了ARM首款big.LITTLE系统。利用完全一致的系统结合Cortex-A15以及Cortex-A7,因而在现有的高性能移动平台以外开启了全新的可能。
对于未来任何一种处理器,处理速度都将因为受限于散热问题而无法大幅跃进。设备一旦达到热障(thermal barrier)就会熔化,如果是移动电话,便会使设备的温度上升造成用户不适。除了物理层面的散热问题外,能源效率也相当差。若调校处理器使其速度加快,则所需耗能便会呈指数数增长,而为了增加最后一丁点的性能需要付出的成本非常高。过去,尺寸倍增代表着速度翻倍,但如今,面积倍增,速度却只增加几个百分点,因此复杂度并不代表有效率,而这就是单一核心系统有所限制的原因之一。
如果无法加快单一核心的速度,那么就必须增加独立核心的数量。这也有助于每个核心去应对其被分配到的任务需求,而这也就是ARM big.LITTLE(大小核)处理器技术的贡献所在。
big.LITTLE处理器技术要解决业界目前最严峻的挑战:通过提升性能和延长电池续航时间来拓展消费者“始终在线、始终连接”的互联移动体验。这种技术之所以能达成上述目标,是通过结合一个大(big)的多核心处理器与一个小(LITTLE)的多核心处理器,然后根据性能需求,以无缝的方式针对不同任务选择合适的处理器。更重要的是这种动态选择的动作,对于上层应用软件或中间件在处理器上的执行丝毫没有任何影响。
目前已应用于市面上移动设备的 的big.LITTLE设计,结合了高性能Cortex-A15多处理器集群与具有节能特色的Cortex-A7多处理器集群。这些处理器在架构上是百分之百兼容且具有相同功能(均支持LPAE、虚拟化扩充及NEON、VFP之类的运作单元),无须另外调整即可让针对其中一种处理器类型所编译的软件应用程序顺畅地应用于另一款处理器上。

big.LITTLE 系统结构
就高速缓存一致性(cache coherency)的维护而言,无论是同一处理器集群中的高速缓存、或是跨不同处理器集的高速缓存,皆保持了高速缓存数据的一致性。这种跨集群的一致性来自ARM CoreLink高速缓存一致性互连(CCI-400,也能提供ARM Mali-T604之类的图形处理器﹝GPU﹞系统等组件的I/O一致性)。两种集群的中央处理器,还可通过CoreLink GIC-400之类的共享中断控制器互传信号。
big.LITTLE 系统执行模式
由于同一应用程序不需要任何修改就可以同时在Cortex-A7和Cortex-A15上运行,因此可以在随机的情况下也能为某个应用程序选择正确的处理器。下列执行模式便以此理论为基础:
● big.LITTLE转移模式;
● big.LITTLE MP模式。
顾名思义,转移模式支持不同类型处理器之间的内容获取和恢复。以中央处理器转移来说,集群中每个中央处理器在另一个集群中都有对应的中央处理器,而软件内容则以每个中央处理器为单位,随机在不同的集群间转移。如果集群中没有正在运转中的中央处理器,便可关闭整个集群以及相关的二级缓存(L2 cache)电源。MP模式则将软件堆栈分配到两个集群中各个处理器上。所有的中央处理器可同时运作,将系统性能提升到最高点。
big.LITTLE 转移模式
转移模式是动态电压频率调整(DVFS)等功耗/性能管理技术的延伸。转移操作类似DVFS操作点的转换。处理器上DVFS曲线的操作点,会随负载变化不同而来回移动。在当前的处理器(或集群)已达到最高操作点时,如果软件堆栈仍需要更高的性能,处理器(或集群)转移就会发生。此时就会由另一个处理器(或集群)来执行工作,这个处理器(或集群)的操作点也会随着负载变化不同而来回变动。当性能需求不再,可以再切换回之前的处理器(或集群)。
一致性是实现快速转移的重要因素,它允许监视并将保存在离埠处理器(outbound processor)的状态,在入埠处理器(inbound processor)上检测与恢复,而不必通过主存储器的存取。此外,由于离埠处理器的L2有高速缓存一致性(cache coherency)的功能,当任务转移时,可以透过检测数据值的方式,改善入埠处理器的高速缓存预热时间,此时L2高速缓存仍然可以维持供电状态。不过,因为离埠处理器的L2高速缓存无法提供新数据的配置, 最后还必须清除并关闭电源以节省耗电。
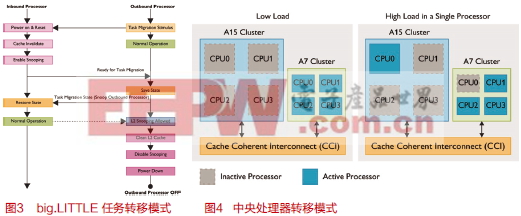
big.LITTLE中央处理器转移模式
至于中央处理器转移,小核的处理器集群中每个处理器都对应了一个大核集群的处理器。中央处理器为成对配置(Cortex-A15及Cortex-A7处理器上同时配置CPU0、CPU1……依此类推)。使用中央处理器转移时,每个处理器配对中在同一时间只有一个中央处理器能够运转。
系统会主动检测各处理器的负载。高负载时内容执行会转移到大的
ARM 处理器 移动平台 转移模式 big LITTLE 201308 相关文章:
- Linux嵌入式系统开发平台选型探讨(11-09)
- 基于ARM体系的嵌入式系统BSP的程序设计方案(04-11)
- 在Ubuntu上建立Arm Linux 开发环境(04-23)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- SQLite嵌入式数据库系统的研究与实现(02-20)
- 革新2410D开发板试用手记(04-21)