一种改进Turbo码译码器的FPGA设计与实现
。
4 硬件实现方案
分量译码器(DEC)内部结构图如图3所示。首先从存储器中顺序读出系统信息序列Xk,校验序列Yk和先验信息Lak,进行正向分支度量γk计算和前向递归αk计算并存储,如图3中上半部分所示。同时,从存储器中逆序读出系统信息序列Xj,校验序列Yj和先验信息Laj,进行反向分支度量γj计算和后向递归βj计算并存储,如图3中下半部分所示。另外还设置正向计算器和反向计算器,计数器对并行运算长度进行计数,并将计数结果作为地址来存储计算结果。等计数值达帧长的一半时,对数似然比计算1模块根据已经计算出并存储的后向递归βj,当前计算出的分支度量γk和前向递归αk进行对数似然比计算,并存储计算结果。同时对数似然比计算2模块根据已经计算出并存储的前向递归αk、当前计算出的分支度量γj和前向递归βj进行对数似然比计算,并存储计算结果。这里采用双口RAM实现对数似然比的存储,双口RAM的两个口可以在地址不冲突的情况下,进行同时写操作。在硬件实现的过程中,不用对分支度量进行存储,从而节省了存储单元。当然由于多加了分支度量计算单元和对数似然比计算,增加了资源,但是从减小译码延时并且译码性能不损失角度考虑,这是非常值得的。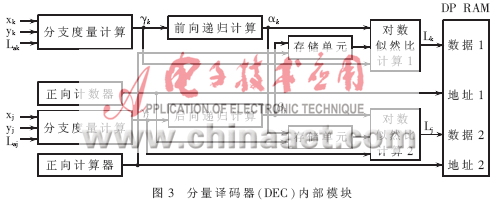
为了进一步节省硬件资源,考虑到两个分量译码器是分时工作的,这样可以进行分量译码器的复用。整个译码器实现结构图如图4所示。当然译码器的实现还需要对应的控制子系统,用于使各个子模块协调有序地工作。这样系统实现的硬件资源就大大减小,译码延时也大大缩小。从而达到高速数据通信的目的。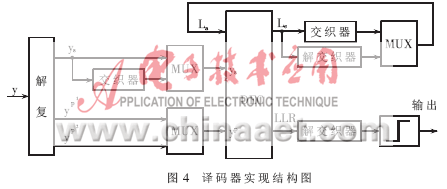
5 硬件实现
基于以上介绍的硬件实现结构,对Xilinx公司的Virtex2pro系列的FPGA芯片进行了配置,采用的是帧长为2 060、1/2码率的Turbo码;译码部分采用MAX-Log-MAP译码算法,其中输入数据流采用8bit(其中1bit符号位,4bit整数位,3bit小数位4)量化;内部计算采用12bit(其中1bit符号位,8bit整数位,3bit小数位4)量化;迭代6次译码。运用XilinxISE8.2i对2vp30ff896-7进行了综合实现,资源消耗如图5的综合报告所示,最大时钟可达到112.331MHz。仿真工具采用Modelsim SE 6.0进行仿真,布局布线后仿真波形图如图6。

为了在不损失译码性能的前提下减小译码延时,本文提出了改进的Turbo码译码方法,通过前向递归和后向递归并行计算,等计算到帧长一半时,开始同时进行前向对数似然比计算和后向对数似然比计算的译码方法。该方案可以将译码延时缩短一半,译码性能没有损失,能节省硬件实现所需的存储单元,时序控制比较简单,更易于硬件实现。仿真结果表明:这种译码方法在性能上优于分块译码算法和双滑窗译码算法。在减小译码延时上优于双滑窗译码算法。这个方案在中短帧长、对译码延时、译码性能要求高的通信系统中有较高的实用价值。
- 3G系统中Turbo译码改进及DSP实现(01-26)
- TPC码译码器硬件仿真的优化设计(06-05)
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 基于FPGA的快速并行FFT及其在空间太阳望远镜图像锁定系统中的应用(06-21)
- 3DES算法的FPGA高速实现(06-21)