基于FPGA的快速并行FFT及其在空间太阳望远镜图像锁定系统中的应用
空间太阳望远镜项目是我国太阳物理学家为了实现对太阳的高分辨率观测而提出的科学计划。它可以得到空间分辨率为0.1"的向量磁图和0.5"的X射线图像,实现这样高的观测精度的前提就是采用高精度的姿态控制系统和高精度的相关跟踪系统。从整个系统来看,相关运算所需的时间成为限制系统性能能否提高的一个重要环节。
目前,国际国内相关计算比较通用的实现方法有两种:用高速DSP或者专用(FFT)处理芯片。用DSP完成相关计算(关键是FFT)受到航天级DSP性能的限制,现有的航天级DSP(如ADSP21020)计算一个32×32点8bit的二维FFT所用时间需要1.5ms以上,远远不能满足系统设计要求;而现有的FFT处理芯片在处理速度、系统兼容性、抗辐射能力等方面不能满足空间太阳望远镜所提出的要求。
为克服这一矛盾,本文利用FPGA资源丰富、易于实现并行流水的特点设计专用的FFT处理芯片来完成复杂的、大量的数据处理;并通过在运算中作溢出监测来保证定点运算的精度,从而大大缩短系统的响应时间,将极大地提高空间太阳望远镜的在轨实时图像处理能力;同时由于FPGA具有抗辐射能力,可以提高系统的可靠性,其在航天遥测遥感和星载高速数据处理等方面将有广泛的应用前景。
1 算法构成
1.1 FFT算法选择
提高FFT速度的两个主要途径是采用流水结构和并行运算[1]。采用高基数结构也可以提高速度,只是用FPGA实现时必须综合考虑系统要求、结构特点及片内资源。针对本系统自身特点,这里按时间抽选算法进行分析。由于32不满足N=4m,所以32点FFT算法不能采用基-4 FFT运算。当详细分析基-2蝶形图时,有些蝶形运算并不需要做乘法,例如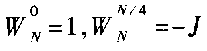 等[2];对于32点DIT-FFT,一共80个蝶形运算,这种结构就有46个,极大地降低了运算复杂度。在一维FFT计算效率提高的基础上对二维FFT采用最常用的行列算法[3],综合各项指标本系统采用基-2 DIT行列算法。
等[2];对于32点DIT-FFT,一共80个蝶形运算,这种结构就有46个,极大地降低了运算复杂度。在一维FFT计算效率提高的基础上对二维FFT采用最常用的行列算法[3],综合各项指标本系统采用基-2 DIT行列算法。
1.2 算术运算方案
本系统是针对32×32点16bit的二维图像进行快速傅里叶变换(FFT),设计要求运算在0.5ms之内完成,所以采用定点运算更符合系统对时间的要求。对于定点运算,必须用定比例的方法防止溢出,即必须解决动态范围问题。下面对其进行理论分析:
若{x(n)}是-N点序列,其DFT为{X(K)},由Parseval定理得[4]:
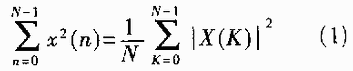
由式(1)可知变换结果的均方值是输入序列均方值的N倍。考虑基-2算法的第m级蝶形运算,用Xm(i)、Xm(j)表示原来的复数,则新的一对复数Xm+1(i)、Xm+1(j)为:
Xm+1(i)=Xm(i)+Xm(j)×W (2)
Xm+1(j)=Xm(i)-Xm(j)×W
其中,W为旋转因子。首先,考虑复数的均方程根值。由(2)式可得:
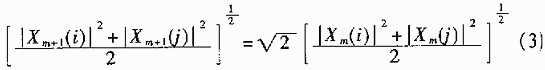
因此,从均方根意义上看,数据(实数或复数)复级都增加(2的平方根)倍。其次,再考虑复数的最大模。由(2)式可以证明[5]。
max{"Xm(i)|,|Xm(j)|}≤max{|Xm+1(i)|,|Xm+1(j)|}≤2max{|Xm(i)|,|Xm(j)|}
因此,复数数组的最大模是非减的。所以,对于DITFFT,其每一级的蝶形运算之后数值都会增加1+(2的平方根)≈2.414倍。在每一次运算完成之后,须将结果右移2bits以满足要求。
2 系统实现
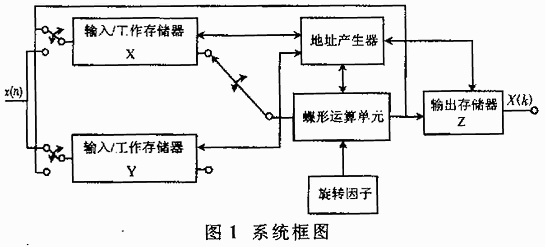
系统原理如图1所示,整个FFT运算处理单元分为三部分:存储单元(两个输入/运算存储器、一个输出存储器及旋转因子存储器)、蝶形运算单元、地址产生器。
2.1 存储器
本系统实时接收前端CCD相机的图像。为保证CCD相机采集图像的准确率,图像的每一行、每一帧之间都必须有一定的时间间隔,故采用两个存储单元作为输入数据和中间数据的暂存单元(如图1所示),以节省时间实现实时处理。当系统工作时,将图像存入存储器、计算上一次采集的图像、将存储器中的结果输出,这三个工作同时进行,用简单的流水方式减少存储数据所需的时间。旋转因子则预先存储在器件的内置ROM中。根据级数不同选用不同的因子。
2.2 蝶形运算单元
一个基-2蝶形运算由一个复乘和两个复加(减)组成,采用完全并行运算,进一步分解为四个实数乘法,六个实数加(减)法,分三级并行完成,加上前后输入输出的数据锁存,共需要6个时钟周期。32点的FFT需要16×5=80个基-2的蝶形运算,一幅图像一共是32行32列,不考虑不需要做乘法的蝶形运算,一路串行共需要6×80×32×2=30720个时钟周期,采用频率为10MHz的时钟,即为3ms。对于蝶形运算的第一、第二级都可以由不带乘法器的蝶形结构来实现同步并行运算,每一个蝶形运算加上前后的数据锁存仅需4个时钟周期即可完成;对于第三、第四、第五级,由于带乘法器不带乘法器的两种蝶形运算结构同时存在,必须加入等待时间才可以实现严格同步。同时由于各级计算时间不同,所以不能实现深
- 用FPGA实现FFT算法(06-21)
- 基于DSP的FFT算法在无功补偿控制器上的应用(09-27)
- DSP滤波器用于扩展数字化仪器的性能(01-25)
- 基于VxWorks平台的快速交流信号采样及计算(03-26)
- 基于TMS32OLF24O7的FFT算法的实现及应用 (05-19)
- 基于TMS320LF2407的FFT算法的实现及应用 (06-15)