基于可编程渲染管线的雷达图像分层模型设计与实现
GPU负责纹理的合成。渲染雷达显示器时,这3层纹理在像素着色器中进行混合,产生最终的雷达图像。混合代码如下: 3 雷达回波图像更新与直接像素存取 4 余辉效果与渲染到纹理 要形成随时间变化的动态效果,模拟程序需要在帧间隔内根据顶点坐标和当前扫描线的位置,重新设置每个顶点的颜色。Direct3D重新渲染便产生了亮度渐变且动态变化的圆。 5 ARPA符号绘制与GDI绘图 6 结 语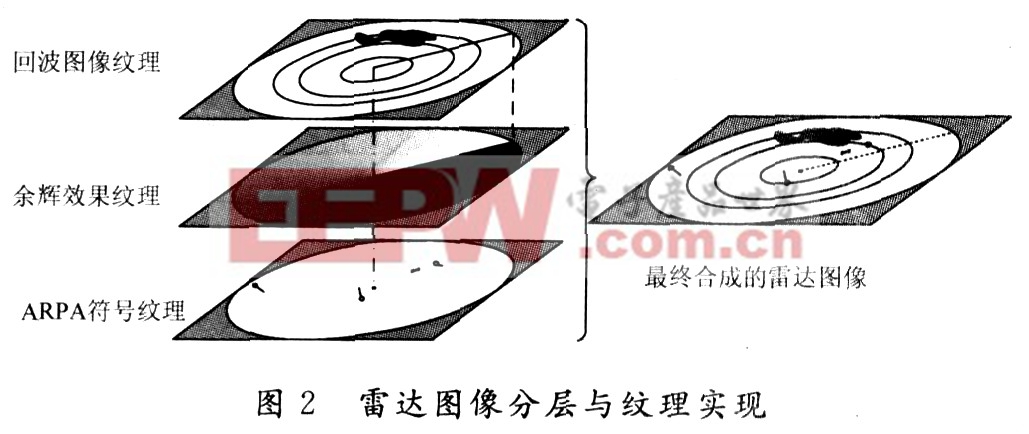

此外利用像素着色器,还非常容易实现亮度控制、颜色反转等特殊显示效果。由于CPU和GPU可并行处理,代码的执行效率非常高。
帧间隔内更新回波图像,就是利用接收机输出的脉冲序列来更新回波图像纹理中的扫描扇面区。脉冲序列存放在回波缓存区数组内。由于脉冲幅值与像素颜色数据格式不同、缓存区数组与像素矩阵维度不同,不能用直接位块传送(Blt)来绘制回波图像。需要绘制单个像素来更新。Direct3D通过IDirect3DTexture9::LockRect()方法锁定纹理上的一块矩形区域,该矩形区域被映射成类似于DIB/DDB的像素数组。利用函数返回的指针,可以对数组中的像素进行直接存取。通过纹理锁定来存取显存,能够达到GDI函数无法达到的高性能。
锁定的矩形区越大,则存取的次数就越多。在锁定前根据扫描区域首先计算需要锁定的矩形范围,便可大幅减少存取像素的数量。这也正是雷达图像分层所带来的好处。如图3所示,A中需要对全屏像素进行存取,而B中只需要访问扫描扇面包围矩形中的像素。在进行像素存取时,采用查表法实现直角坐标与极坐标的转换,还能进一步提高存取的效率。
在绘制余辉效果图层时,采用渲染到纹理技术(RTT),将纹理设置成渲染目标,用D3D绘图函数直接在纹理上绘图,形成颜色渐变且动态变化的余辉效果。要实现渲染到纹理,在创建纹理时,用参数D3DUSAGE RENDERTARGET指定纹理的用途,并调用GetSurfaceLevel()方法获取纹理的表面接口指针。在渲染时,用SetRenderTarget()方法将该表面设置成渲染目标。
为了绘制出图4中的余辉效果纹理,可用N条射线来组成余辉效果纹理中的圆,N等于天线方位刻线的数量,每条射线的颜色由其端点颜色决定。N条射线需要用2N个顶点来描述,顶点除含有坐标外,还包括颜色值。创建了这些顶点后,Direct3D在渲染管线中自动将其绘制成图像。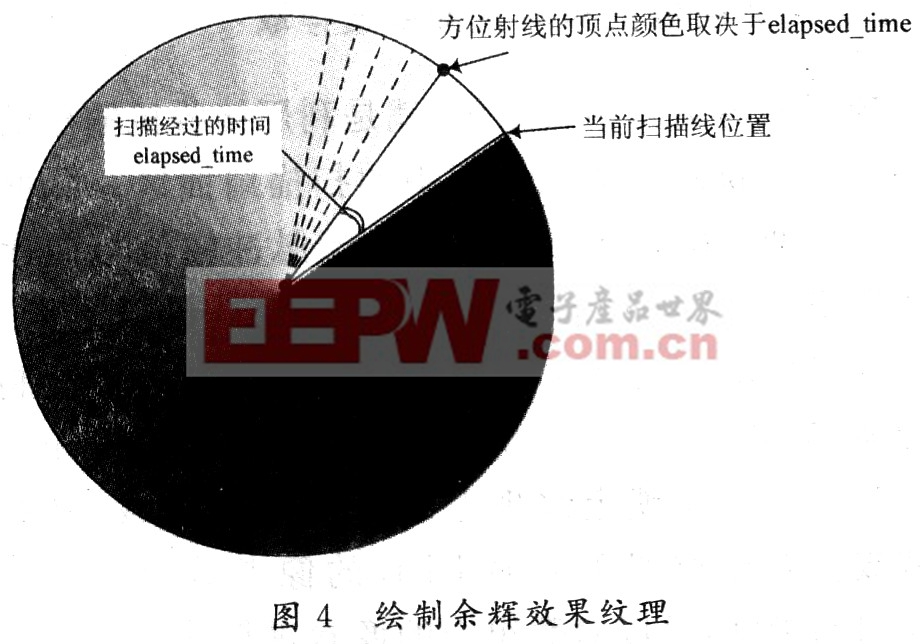
采用这种方法,帧间隔内CPU仅需要存取2N个顶点的颜色。在前面的例子中,雷达扫描一周形成4 096个方位,需要绘制4 096条射线,即设置8 192个顶点颜色。在大幅减少了像素存取次数的情况下,增加的这部分顶点颜色存取时间并不会影响整体性能的改善。
ARPA信息与符号的绘制不随扫描变化,而与雷达信息处理机的状态有关,即由描述雷达信息处理机的状态数据表以及点目标跟踪表等数据表生成,比较适合用GDI函数绘制。为了能够在纹理上采用GDI函数绘图,需要获取纹理的表面(Surface)接口指针,然后利用表面的GetDC()方法得到该表面设备上下文(DC)。这样就可以调用win32的GDI函数进行符号文字等输出了。由于这部分绘图代码内容少且更新率低,因此其CPU占用率几乎可以不计。
在某型舰载导航搜索雷达中,采用上述方法对雷达模拟器的显示部分进行了改进。模拟器的计算机平台配置为:PentiumXXXXXXXXXⅣ2.8 GHz,ASUS Extreme AX550显卡。模拟程序运行的帧速率从15 f/s提高到50 f/s以上,效果明显。结果表明,采用可编程渲染管线技术,可以实现回波图像更新与余辉效果计算的分离,充分发挥显卡的渲染能力,能够满足大分辨率雷达显示系统仿真的需求。
实际上,雷达显示器余辉效果纹理的绘制基本上独立于雷达的脉冲数据处理等过程,如果能够把描述余辉效果的4 096个亮度数值完全置于可编程渲染管线的顶点着色器中,由顶点着色器来完成亮度衰减及更新计算,将进一步降低CPU的计算负担。但由于余辉仿真是一个迭代过程,当前帧亮度是前一帧亮度的衰减,这需要对每次迭代后的结果进行保存。然而在目前的Direct3D版本中,还不支持渲染到顶点(RTV),顶点着色器也难以支持大容量的数组变量,迭代运算的结果难以保存。目前,模拟余辉效果顶点颜色动画仍然由CPU来完成。随着显卡技术和Direct3D技术的发展,这部分代码还能得到进一步的优化。
- 改善可编程增益放大器性能的一个技巧(05-21)
- 一种可编程宽带放大器的设计(01-17)
- 基于FPGA的可编程电压源系统设计(03-03)
- 为便携式消费应用优化的可编程低功耗计时器件(03-04)
- 过程控制和PLC设计指南(06-28)
- 基于VCA822的可编程增益放大器(08-01)