使用Vivado高层次综合工具评估IQ压缩算法
时间:05-25
来源:互联网
点击:
向上扩展编解码架构
对于原型配置,我们计划将压缩算法向上扩展,以充分利用 9.8304 Gbps CPRI 链路(线路比特率选项 7)。ORI 压缩 E-UTRA 样本规范允许我们通过单个 9.8G CPRI 链路传输 16 条压缩 IQ 通道(32 条 I 与 Q 通道单独压缩)。目标吞吐量为每个 CPRI 时钟输出三个压缩样本,这已足够完全打包 32 位赛灵思 LogiCORE™ IP CPRI IQ 接口,提供所需的 737.28 Msps 的压缩 IP 输出。
以单个时钟域为目标,我们需要构建重采样滤波器以满足每个时钟周期三个样本的输出速率。用 0 的补码对输入样本流进行内插计算允许我们忽略无用的输入样本。输出流变为子滤波器内插速率的函数,每个子滤波器都使用 FIR 系数子集(系数 / 插值速率的总数)。共四个并行滤波器,每个都在一个通道子集上运行,使得整体吞吐量相当于每个时钟周期要求 3 个压缩样本。除高吞吐量以外,所建议的架构还能缩短重采样时延,因为每个子滤波器中仅使用一小部分系数。
对于压缩路径,我们使用累积分布函数 (CDF) 计算 NLQ 量化表。假设 IQ 分布是对称的,我们将 NLQ 查找表的大小缩减至 214 条 9 位量化值。由于我们的设计需要每时钟周期三个并行查找表,因此我们利用相同量化值实现三个并行查找表。可以
使用预期或观察的标准偏差值为 I 和 Q 样本单独计算量化等级。 或者,以实际的信号级测量值或更高层次的网络参数为依据,单独量化通道子集。解压缩时,我们使用分位函数(逆向 CDF)来计算逆向 NLQ 表。表的大小被限定在 29 个 14 位数值。
我们使用由 MATLAB® LTE 系统工具箱生成的 20 MHz LTE E-UTRA FDD 通道激励来测试已实现的编解码算法。然后,我们使用 Keysight VSA 来解调捕捉到的 IQ 数据,并通过测量输出波形误差矢量幅度 (EVM) 以量化压缩和解压缩阶段引起的信号失真。我们将已公布的输出 EVM 测量值(体现理想信号与测量信号的差异)与参考输入信号 EVM 进行比较。
高级建模与实现流程
我们使用GNU Octave 语言,并利用其信号处理和统计程序包开发单通道压缩及解压缩模型,启动实现过程。除提供有用的验证参考数据点以外,模型输出还生成了一组 FIR 滤波器系数和量化表。
Vivado HLS 工具从高级数学模型中提供明显的传输路径,从潜在的硬件性能和成本方面评估提议的架构。我们建立了 C++ 测试台,以利用压缩和解压缩函数对输入数据流进行运算。由于我们会将这些函数置于 CPRI 链路的相对端,因此便单独对其进行综合。利用 HLS 流及简单 C++ 循环管理下的交错通道数据流,我们实现了所有内、外部函数接口。
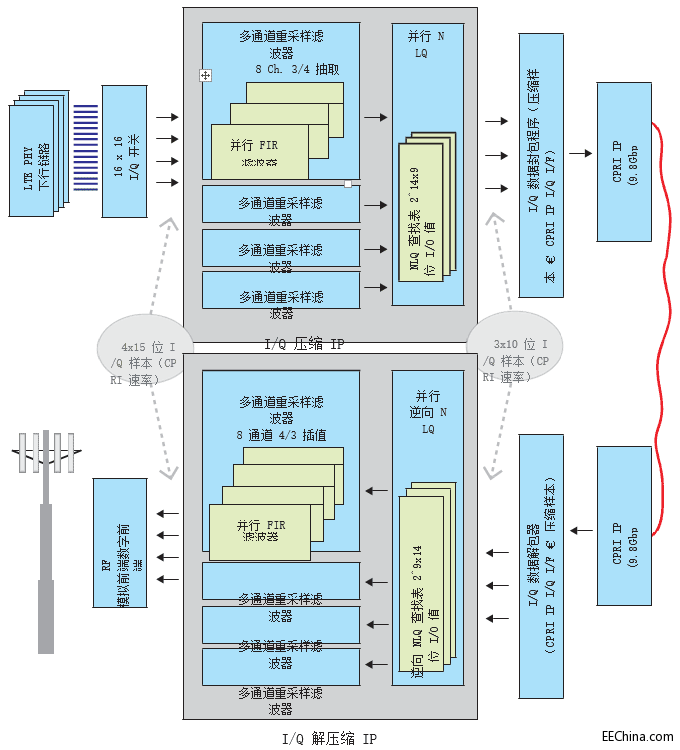
图 3–IQ 编解码架构所示为(仅下行链路中)编解码器 IP 接口处的样本处理速率
我们利用 Vivado HLS FIR IP 来开发重采样滤波器的原型设计。为满足设计的高吞吐量要求,我们实现并行单速率 FIR 滤波器,并采用基于循环的滤波器输出抽取功能。
通过实现多相重采样滤波器,可获得更高效的资源节约型重采样滤波器。多通道分级采样速率转换滤波器就是一种支持 ORI 重采样速率的开箱即用型选择;赛灵思应用指南 XAPP1236 “使用 Vivado 高层次综合以实现多通道分级采样速率转换滤波器设计。”对该滤波器进行了介绍。
当验证数据集较大时,快速 C 级仿真的优势就变得愈发明显。对 IQ 压缩算法进行评估时最能体现这一点,因为,至少需要有完整的无线电数据帧(307,200 个 IQ 样本 / 通道),才能利用 VSA 工具进行 EVM 测量。我们发现,C 仿真与 C/RTL 协同仿真相比,仿真速度可提升两个数量级;对于本压缩 IP 测试而言,相比于协同仿真运行时间的 9 小时,C 仿真仅需 5 分钟。
HLS 测试台还具备另一个重要优势,即利用文件和 HLS 流可方便地使用输入数据和捕捉输出数据。结果是可提供一个接口以利用 VSA 工具进行数据分析,或者在 C++ 测试台中直接与 Octave 模型输出进行比较。
性能测量
Keysight VSA 测量结果显示,具有 144 个 FIR 系数的编解码器配置具备 0.29% 的平均 EVM。与 EVM RMS 为 0.18% 的初始输入数据相比,因压缩-解压缩处理链而多出的 EVM 部分为 0.23%。相比之下,同等输入数据集下 Mu-Law 压缩算法实现的平均 EVM 为 1.07%。
根据 Mu-Law 压缩法所减少的时延和资源使用成本来看,当可以将整个 LTE 下行信号处理链的 8% EVM 预算中的 1% 分配给 IQ 压缩时,Mu-Law 压缩就会优于 ORI IQ 压缩方案。然而,任何附加信号失真都意味着要为剩余系统组件设定更严格的性能目标。数字前端器件及功率放大器等组件的成本增加可能会抵消潜在的 IQ 压缩成本优势。
Vivado 高层次综合依据启动间距确认了所需吞吐量——顶层任务准备好接受新输入数据之前的时钟周期数量。同时,经过我们的验证,导出的 Vivado IP Integrator 内核满足目标 Kintex® UltraScale™ 平台的时序要求。
我们将研究范围限定在少量的配置和输入数据向量。然而,一旦系统模型和对应的 C 语言模型就位,即可在几分钟内自定义、实现与评估备选配置。
对于原型配置,我们计划将压缩算法向上扩展,以充分利用 9.8304 Gbps CPRI 链路(线路比特率选项 7)。ORI 压缩 E-UTRA 样本规范允许我们通过单个 9.8G CPRI 链路传输 16 条压缩 IQ 通道(32 条 I 与 Q 通道单独压缩)。目标吞吐量为每个 CPRI 时钟输出三个压缩样本,这已足够完全打包 32 位赛灵思 LogiCORE™ IP CPRI IQ 接口,提供所需的 737.28 Msps 的压缩 IP 输出。
以单个时钟域为目标,我们需要构建重采样滤波器以满足每个时钟周期三个样本的输出速率。用 0 的补码对输入样本流进行内插计算允许我们忽略无用的输入样本。输出流变为子滤波器内插速率的函数,每个子滤波器都使用 FIR 系数子集(系数 / 插值速率的总数)。共四个并行滤波器,每个都在一个通道子集上运行,使得整体吞吐量相当于每个时钟周期要求 3 个压缩样本。除高吞吐量以外,所建议的架构还能缩短重采样时延,因为每个子滤波器中仅使用一小部分系数。
对于压缩路径,我们使用累积分布函数 (CDF) 计算 NLQ 量化表。假设 IQ 分布是对称的,我们将 NLQ 查找表的大小缩减至 214 条 9 位量化值。由于我们的设计需要每时钟周期三个并行查找表,因此我们利用相同量化值实现三个并行查找表。可以
使用预期或观察的标准偏差值为 I 和 Q 样本单独计算量化等级。 或者,以实际的信号级测量值或更高层次的网络参数为依据,单独量化通道子集。解压缩时,我们使用分位函数(逆向 CDF)来计算逆向 NLQ 表。表的大小被限定在 29 个 14 位数值。
我们使用由 MATLAB® LTE 系统工具箱生成的 20 MHz LTE E-UTRA FDD 通道激励来测试已实现的编解码算法。然后,我们使用 Keysight VSA 来解调捕捉到的 IQ 数据,并通过测量输出波形误差矢量幅度 (EVM) 以量化压缩和解压缩阶段引起的信号失真。我们将已公布的输出 EVM 测量值(体现理想信号与测量信号的差异)与参考输入信号 EVM 进行比较。
高级建模与实现流程
我们使用GNU Octave 语言,并利用其信号处理和统计程序包开发单通道压缩及解压缩模型,启动实现过程。除提供有用的验证参考数据点以外,模型输出还生成了一组 FIR 滤波器系数和量化表。
Vivado HLS 工具从高级数学模型中提供明显的传输路径,从潜在的硬件性能和成本方面评估提议的架构。我们建立了 C++ 测试台,以利用压缩和解压缩函数对输入数据流进行运算。由于我们会将这些函数置于 CPRI 链路的相对端,因此便单独对其进行综合。利用 HLS 流及简单 C++ 循环管理下的交错通道数据流,我们实现了所有内、外部函数接口。
图 3–IQ 编解码架构所示为(仅下行链路中)编解码器 IP 接口处的样本处理速率
我们利用 Vivado HLS FIR IP 来开发重采样滤波器的原型设计。为满足设计的高吞吐量要求,我们实现并行单速率 FIR 滤波器,并采用基于循环的滤波器输出抽取功能。
通过实现多相重采样滤波器,可获得更高效的资源节约型重采样滤波器。多通道分级采样速率转换滤波器就是一种支持 ORI 重采样速率的开箱即用型选择;赛灵思应用指南 XAPP1236 “使用 Vivado 高层次综合以实现多通道分级采样速率转换滤波器设计。”对该滤波器进行了介绍。
当验证数据集较大时,快速 C 级仿真的优势就变得愈发明显。对 IQ 压缩算法进行评估时最能体现这一点,因为,至少需要有完整的无线电数据帧(307,200 个 IQ 样本 / 通道),才能利用 VSA 工具进行 EVM 测量。我们发现,C 仿真与 C/RTL 协同仿真相比,仿真速度可提升两个数量级;对于本压缩 IP 测试而言,相比于协同仿真运行时间的 9 小时,C 仿真仅需 5 分钟。
HLS 测试台还具备另一个重要优势,即利用文件和 HLS 流可方便地使用输入数据和捕捉输出数据。结果是可提供一个接口以利用 VSA 工具进行数据分析,或者在 C++ 测试台中直接与 Octave 模型输出进行比较。
性能测量
Keysight VSA 测量结果显示,具有 144 个 FIR 系数的编解码器配置具备 0.29% 的平均 EVM。与 EVM RMS 为 0.18% 的初始输入数据相比,因压缩-解压缩处理链而多出的 EVM 部分为 0.23%。相比之下,同等输入数据集下 Mu-Law 压缩算法实现的平均 EVM 为 1.07%。
根据 Mu-Law 压缩法所减少的时延和资源使用成本来看,当可以将整个 LTE 下行信号处理链的 8% EVM 预算中的 1% 分配给 IQ 压缩时,Mu-Law 压缩就会优于 ORI IQ 压缩方案。然而,任何附加信号失真都意味着要为剩余系统组件设定更严格的性能目标。数字前端器件及功率放大器等组件的成本增加可能会抵消潜在的 IQ 压缩成本优势。
Vivado 高层次综合依据启动间距确认了所需吞吐量——顶层任务准备好接受新输入数据之前的时钟周期数量。同时,经过我们的验证,导出的 Vivado IP Integrator 内核满足目标 Kintex® UltraScale™ 平台的时序要求。
我们将研究范围限定在少量的配置和输入数据向量。然而,一旦系统模型和对应的 C 语言模型就位,即可在几分钟内自定义、实现与评估备选配置。
赛灵思 无线电 射频 滤波器 低通滤波器 编码器 LTE 解码器 仿真 放大器 相关文章:
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)
- FPGA可帮助搜索引擎降低功耗和碳排放(09-12)
- 基于Spartan-3A DSP的安全视频分析(05-01)
- 赛灵思新版视频入门套件加快视频开发速度(05-29)
- 赛灵思“授之以渔”理论:危机中如何巧降成本(06-04)
- 赛灵思详解新近推出的FPGA领域设计平台(12-16)