采用赛灵思FPGA 实现可扩展的MIMO预编码内核
时间:05-25
来源:互联网
点击:
设计验证
我们分两步执行 IP 验证。首先,我们将 FPGA_HLP_Core 的输出与 Simulink 中的参考双精度多分支 FIR 内核进行比较。我们发现,在 16 位分辨率版本中,我们已成功实现小于 0.04% 的相对幅值误差。较大的数据宽度能提供更好的性能,但代价是消耗更多资源。
功能验证完成后,就需要验证芯片性能。因此,我们的第二个步骤是在 Vivado 设计套件 2015.1 中针对 Zynq®-7000 All Programmable SoC 的 FPGA 架构(相当于一个 Kintex® xc7k325tffg900-2)对所创建的 IP 进行综合与实现。凭借工具的综合与默认实现设置中具备的完整层级,我们创建了一个具有清晰注册层级的完全管线化设计,因而在 491.52 MHz 的内部处理时钟速率下不难实现所要求的时序。
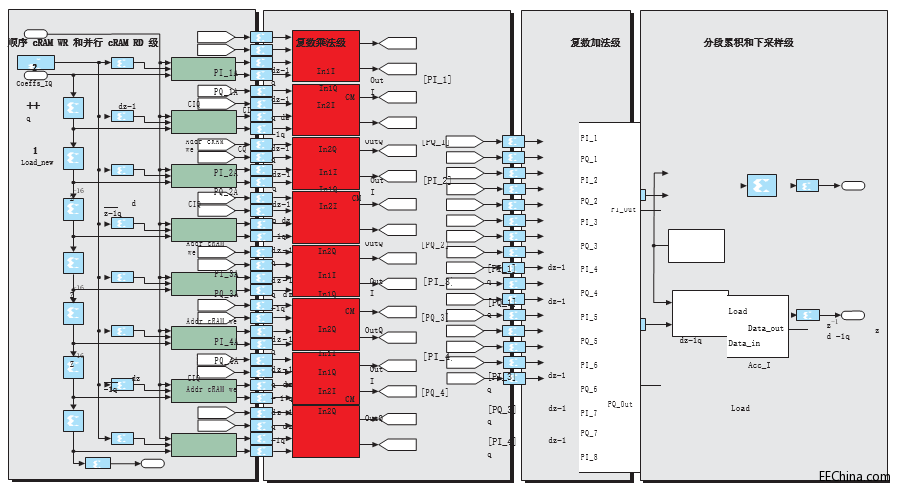
图 3 - 部分并行复数 FIR 模块
可扩展性演示
我们设计的 HLP IP 便于用来创建更大的大规模 MIMO 预编码内核。表 2 列出了一些应用方案以及重要资源的使用情况。您需要一个额外的聚合级以提交最后的预编码结果。
例如图 4 所示,通过插入四个 HLP 内核以及一个额外管线化数据聚合级,很容易构建一个 4x4 预编码内核。
高效和可扩展
我们已经介绍了如何利用赛灵思 System Generator 和 Vivado 设计工具快速构建 大规模 MIMO 预编码内核形式的高效、可扩展的DSP 线性卷积应用。您既可以在部分并行架构中使用更多顺序级,也可以合理地增大处理时钟速率以更快速地实现任务操作,从而对该内核进行扩展,以便支持更长抽头的 FIR 应用。对于第二种情况,针对实际的实现架构找到目标器件的瓶颈和关键路径应该会有所帮助。然后,更好的方法将会是对硬件和算法进行协同优化以调节系统性能,例如针对硬件的使用开发出更小型预编码算法。
首先,我们着重开发具有最低时延的预编码解决方案。下一步,我们将探索一种替代解决方案以获得优化的资源使用与功耗。如需了解更多信息,请通过邮件联系作者,邮件地址:lei.guan@ieee.org。
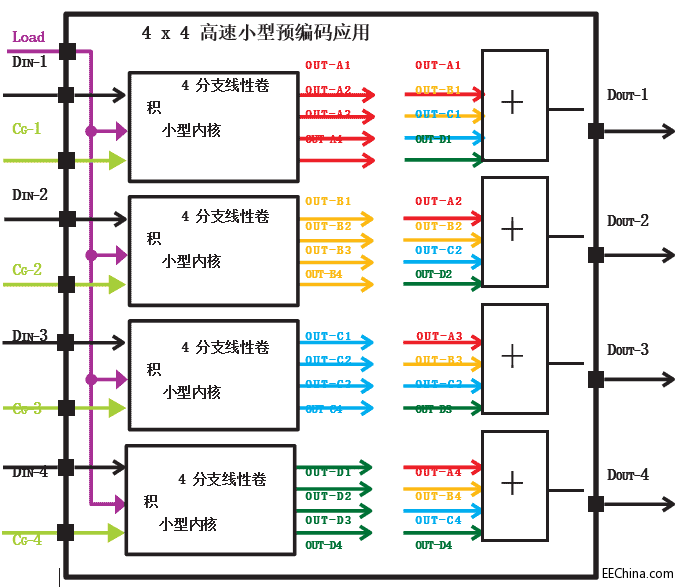
图 4:基于 4B-LC 内核的扩展的预编码应用实例
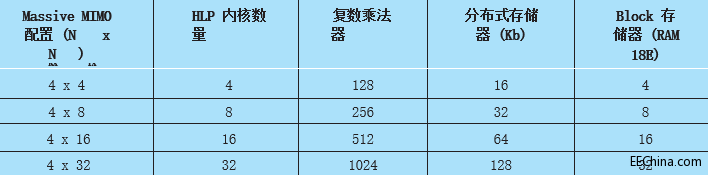
表 2 - 以推荐的 HLP 内核为基础,在不同应用场景下的资源使用实例
我们分两步执行 IP 验证。首先,我们将 FPGA_HLP_Core 的输出与 Simulink 中的参考双精度多分支 FIR 内核进行比较。我们发现,在 16 位分辨率版本中,我们已成功实现小于 0.04% 的相对幅值误差。较大的数据宽度能提供更好的性能,但代价是消耗更多资源。
功能验证完成后,就需要验证芯片性能。因此,我们的第二个步骤是在 Vivado 设计套件 2015.1 中针对 Zynq®-7000 All Programmable SoC 的 FPGA 架构(相当于一个 Kintex® xc7k325tffg900-2)对所创建的 IP 进行综合与实现。凭借工具的综合与默认实现设置中具备的完整层级,我们创建了一个具有清晰注册层级的完全管线化设计,因而在 491.52 MHz 的内部处理时钟速率下不难实现所要求的时序。
图 3 - 部分并行复数 FIR 模块
可扩展性演示
我们设计的 HLP IP 便于用来创建更大的大规模 MIMO 预编码内核。表 2 列出了一些应用方案以及重要资源的使用情况。您需要一个额外的聚合级以提交最后的预编码结果。
例如图 4 所示,通过插入四个 HLP 内核以及一个额外管线化数据聚合级,很容易构建一个 4x4 预编码内核。
高效和可扩展
我们已经介绍了如何利用赛灵思 System Generator 和 Vivado 设计工具快速构建 大规模 MIMO 预编码内核形式的高效、可扩展的DSP 线性卷积应用。您既可以在部分并行架构中使用更多顺序级,也可以合理地增大处理时钟速率以更快速地实现任务操作,从而对该内核进行扩展,以便支持更长抽头的 FIR 应用。对于第二种情况,针对实际的实现架构找到目标器件的瓶颈和关键路径应该会有所帮助。然后,更好的方法将会是对硬件和算法进行协同优化以调节系统性能,例如针对硬件的使用开发出更小型预编码算法。
首先,我们着重开发具有最低时延的预编码解决方案。下一步,我们将探索一种替代解决方案以获得优化的资源使用与功耗。如需了解更多信息,请通过邮件联系作者,邮件地址:lei.guan@ieee.org。
图 4:基于 4B-LC 内核的扩展的预编码应用实例
表 2 - 以推荐的 HLP 内核为基础,在不同应用场景下的资源使用实例
FPGA 赛灵思 收发器 DSP 滤波器 LTE SoC 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)