对FPGA设计进行编程并不困难
时间:01-12
来源:互联网
点击:
硬件设计者已经开始在高性能DSP的设计中采用FPGA技术,因为它可以提供比基于PC或者单片机的解决方法快上10-100倍的运算量。以前,对硬件设计不熟悉的软件开发者们很难发挥出FPGA的优势,而如今基于C语言的方法可以让软件开发者毫不费力的将FPGA的优势发挥得淋漓尽致。这些基于C语言的开发工具可以比基于HDL语言的硬件设计更节省设计时间,同时不需要太多的硬件知识。 由于具有这些优势,FPGA技术不仅可使这些器件作为I/O器件的前端,FPGA还可实现大量的高带宽和运算密集型应用的实时处理。此外,FPGA还可很紧密地与板上存储器结合,并在一块电路板上集成多个器件。更好的是,FPGA电路板可通过新兴的串口通讯标准进行通讯,如Rapid I/O或者PCIX。这些最新技术可让基于FPGA的系统比现有的多CPU和DSP系统的性价比高出一个数量级。 因此,在用CPU和DSP解决高带宽和算法密集问题的场合中,例如医疗成像、工业应用以及军用声纳和雷达等,经常使用FPGA。设计者利用这些新型的基于C语言的开发工具来开发DSP(在一块PCI板上安装单块或多块FPGA处理器),就可以实现前面提到的改进性能以及更短的面世时间。 这篇文章向设计者展示了如何利用C语言工具在基于FPGA的系统中实现信号处理,并一步一步向开发者说明在多FPGA系统中实现算法密集型信号处理程序的过程。利用C语言对FPGA计算解决方案进行编程,能将把程序的执行时间从12分钟减少到仅为2秒。
1 通过C语言与硬件进行接口
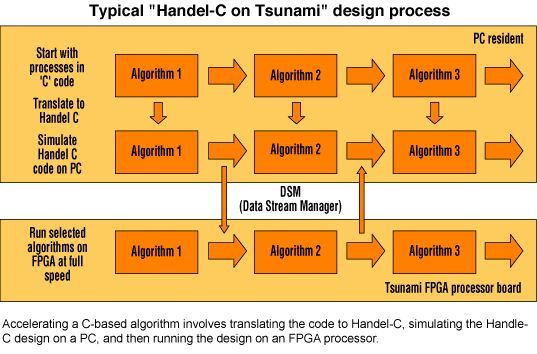
假设您在设计一个算法密集的信号处理程序,例如分析上千公里长公路的裂缝。这种应用需要用到正/逆向霍夫变换的算法,该算法还可对航拍图片中的河流和街道以及半导体表面的瑕疵进行定位。 如果你正使用基于奔腾4和Windows XP的PC、带有多个FPGA的PCI板(例如Tsunami板)、C语言开发环境和Handel-C(Celoxica开发环境)来进行设计,并假设你对HDL硬件语言所知甚少,却熟悉基于FPGA设计的一些基础知识。设计过程要从C语言代码的编写开始,然后将代码转化成Handel-C,并在PC上进行仿真,最终在多FPGA处理器上运行测试。
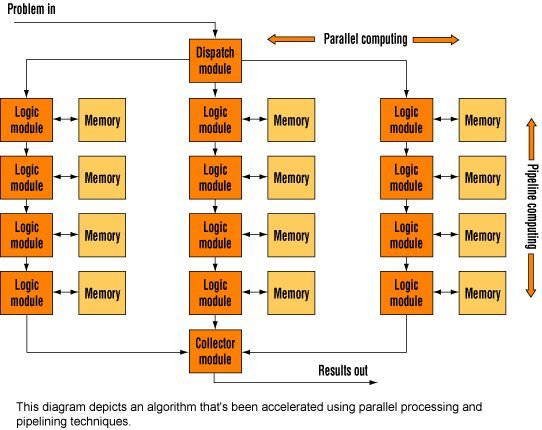
一开始,先要决定C语言代码对哪些算法进行加速。一个好的剖析工具,例如Intel的VTune Performance Analyzer,可以帮你发现消耗过多时钟周期的代码段。 在上述的信号处理应用中,完全由CPU完成算法要花费12分钟的时间,经过剖析发现时间几乎是消耗在各种嵌套的循环中,这清楚地显示了哪些代码是由FPGA加速器加速的。经过加速过的代码需要经过PC上的PCI总线输入和输出。由此可知I/O数据的速度在PCI总线的速度范围之内――从70到200Mbps。 接下来的挑战是创建FPGA设计以加速代码的功能。由于FPGA可以同时执行上千条指令,访问上百个内存块,所以“管道”和“并行处理”技术都可被用来加速功能。利用管道技术,指令路径是有顺序的,即当一些算法正在一部分数据“管道”中被执行时,另一些算法将在同一“管道”的后面部分被执行,这个过程与自动生产线很相似。具有长时钟的程序可以通过并行处理来显著降低运行时间(图2)。
最后,你还必须分析各个算法,将其按步分解成由数学运算(加、减、乘、除、积分)、延迟、保存到内存和查表等操作。无论多复杂的算法都可以分解成这些最基本的操作,而且这些操作在相互无关联的情况下可以并行处理。 我们的示例应用可以这样被加速:9个处理周期被充分地进行管道处理,在初始延迟后的每个时钟都输出一个结果,然后这些周期被嵌入到X、Y和Θ的三维循环中,因此总的周期数为9+(9*X*Y*Θ),即在每个处理块中只包括9个这样的周期:延迟+(9个周期*64个像素*64个像素*64位深度)。
尽管FPGA中可以实现浮点运算单元,但它们能迅速消耗FPGA的资源,所以如果可以,最好谨慎使用。主要依靠浮点运算的算法最好转换成定点运算,这样你既可利用用“模块浮点”方法,又可通过定点的方法设计整个系统。然后,通过对比实际输出与原始的全浮点运算的软件实现来确定转换精度。在霍尔算法的例子中,14b+7b的定点分辨率与全浮点的结果完全相同。
2 确定资源
在接下来的设计中,需要对每个处理部分的时钟周期计数。通常,每个时钟周期可以完成二到三个运算,然后确定所需的FPGA资源以适应代码。可以在多个FPGA中分段运行代码来获得更高的计算能力。这些解决方案的拓展非常容易,只要使用所需的多个FPGA(最多5个),系统将自动检测它们。 在该例子中,设计是基于处理块的。这些块按顺序被发送给每个FPGA,或者从每个FPGA收集起来(其逻辑是代码的一部分)。一个FPGA的加速比例可以达到37:1,而10个FPGA(每两个电路板上有5个)可以达到370:1。 对设计进行编码相对简单,因为设计主要由C语言完成,除了一些需要特殊Handel-C指令的新功能。这些新指令包括:增强位操作、并行处理、宏操作和公式、任意宽度的变量、FPGA存储器接口、RAM和ROM类型、信号(代表硬件中的信号线)以及通道(在代码并行分支或时钟域之间通信)。工具条中的“代码转换”可以完成C和Handel-C的样本转换。
1 通过C语言与硬件进行接口
假设您在设计一个算法密集的信号处理程序,例如分析上千公里长公路的裂缝。这种应用需要用到正/逆向霍夫变换的算法,该算法还可对航拍图片中的河流和街道以及半导体表面的瑕疵进行定位。 如果你正使用基于奔腾4和Windows XP的PC、带有多个FPGA的PCI板(例如Tsunami板)、C语言开发环境和Handel-C(Celoxica开发环境)来进行设计,并假设你对HDL硬件语言所知甚少,却熟悉基于FPGA设计的一些基础知识。设计过程要从C语言代码的编写开始,然后将代码转化成Handel-C,并在PC上进行仿真,最终在多FPGA处理器上运行测试。
 |
一开始,先要决定C语言代码对哪些算法进行加速。一个好的剖析工具,例如Intel的VTune Performance Analyzer,可以帮你发现消耗过多时钟周期的代码段。 在上述的信号处理应用中,完全由CPU完成算法要花费12分钟的时间,经过剖析发现时间几乎是消耗在各种嵌套的循环中,这清楚地显示了哪些代码是由FPGA加速器加速的。经过加速过的代码需要经过PC上的PCI总线输入和输出。由此可知I/O数据的速度在PCI总线的速度范围之内――从70到200Mbps。 接下来的挑战是创建FPGA设计以加速代码的功能。由于FPGA可以同时执行上千条指令,访问上百个内存块,所以“管道”和“并行处理”技术都可被用来加速功能。利用管道技术,指令路径是有顺序的,即当一些算法正在一部分数据“管道”中被执行时,另一些算法将在同一“管道”的后面部分被执行,这个过程与自动生产线很相似。具有长时钟的程序可以通过并行处理来显著降低运行时间(图2)。
 |
最后,你还必须分析各个算法,将其按步分解成由数学运算(加、减、乘、除、积分)、延迟、保存到内存和查表等操作。无论多复杂的算法都可以分解成这些最基本的操作,而且这些操作在相互无关联的情况下可以并行处理。 我们的示例应用可以这样被加速:9个处理周期被充分地进行管道处理,在初始延迟后的每个时钟都输出一个结果,然后这些周期被嵌入到X、Y和Θ的三维循环中,因此总的周期数为9+(9*X*Y*Θ),即在每个处理块中只包括9个这样的周期:延迟+(9个周期*64个像素*64个像素*64位深度)。
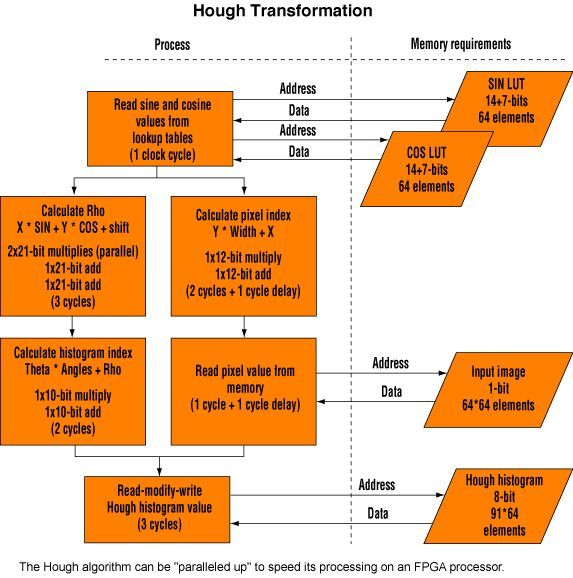 |
尽管FPGA中可以实现浮点运算单元,但它们能迅速消耗FPGA的资源,所以如果可以,最好谨慎使用。主要依靠浮点运算的算法最好转换成定点运算,这样你既可利用用“模块浮点”方法,又可通过定点的方法设计整个系统。然后,通过对比实际输出与原始的全浮点运算的软件实现来确定转换精度。在霍尔算法的例子中,14b+7b的定点分辨率与全浮点的结果完全相同。
2 确定资源
在接下来的设计中,需要对每个处理部分的时钟周期计数。通常,每个时钟周期可以完成二到三个运算,然后确定所需的FPGA资源以适应代码。可以在多个FPGA中分段运行代码来获得更高的计算能力。这些解决方案的拓展非常容易,只要使用所需的多个FPGA(最多5个),系统将自动检测它们。 在该例子中,设计是基于处理块的。这些块按顺序被发送给每个FPGA,或者从每个FPGA收集起来(其逻辑是代码的一部分)。一个FPGA的加速比例可以达到37:1,而10个FPGA(每两个电路板上有5个)可以达到370:1。 对设计进行编码相对简单,因为设计主要由C语言完成,除了一些需要特殊Handel-C指令的新功能。这些新指令包括:增强位操作、并行处理、宏操作和公式、任意宽度的变量、FPGA存储器接口、RAM和ROM类型、信号(代表硬件中的信号线)以及通道(在代码并行分支或时钟域之间通信)。工具条中的“代码转换”可以完成C和Handel-C的样本转换。
DSP FPGA 单片机 C语言 电路 半导体 仿真 总线 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- FPGA作为协处理器在实时系统中的应用(04-08)
- 学习FPGA绝佳网站推荐!!!(05-23)
- 我的FPGA学习历程(05-23)
- 基于Spartan-3A DSP的安全视频分析(05-01)