H.264/AVC中CAVLC编码器的硬件设计实现
时间:11-09
来源:互联网
点击:
H.264/AVC是ITU-T和ISO联合发布的国际视频压缩标准,比特压缩率分别是MPEG-4、H.263及MPEG-2的39%、49%及64%,是一种高压缩比的新标准。基于内容的自适应可变长编码(CAVLC)是H.264中关键技术之一,应用于H.264的基本档次和扩展档次对亮度和色度残差数据块进行编解码,编码效率高,抗误码和纠错能力强,但计算复杂度大,用软件编码难以满足高清视频实时性要求。H.264编码过程不涉及任何浮点数运算,特别适合硬件电路实现。文献提出的CAVLC编码可分成扫描和编码2部分,扫描部分对残差数据zig-zag逆序扫描后,提取出run-level标志以及相关信息提供给编码部分进行编码。文献对扫描模块进行了优化。编码模块中非零系数级(level)编码计算量最大,复杂度最高。本文充分利用FPGA高速实时特点,采用并行处理及流水线设计,通过优化CAVLC编码结构和level编码子模块,提高CAVLC编码器的性能。
1 CAVLC原理
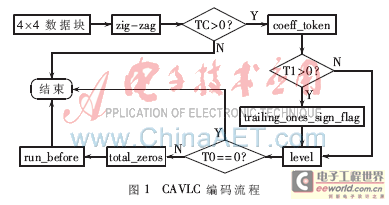
CAVLC是一种依据4×4块变换系数的zig-zag扫描顺序进行的编码算法。块系数的非零系数幅值较小,主要集中在低频段,经过zig-zag扫描后,连续零的个数较多,采用run-level游程编码,通过编码5个语义元素能够实现高效无损压缩,编码流程如图1所示。zig-zag扫描后,顺序编码系数标记(coeff_token)。尾1的符号(trailing_ones_sign_flag)、除尾1外非零系数的级(level),最后一个非零系数前零的个数(total_zeros)和零的游程(run_before)。其中TC、T1、T0分别表示非零系数个数、尾1个数以及最后一个非零系数前零的个数。由于CAVLC编码流程是串行的,软件容易实现,但执行速度慢且效率低。
2 CAVLC编码器硬件结构设计
2.1 并行化编码结构
为了提高运算速度和效率,将图1的CAVLC编码流程并行化处理,适合FPGA实现。根据文献提出的思路,将CAVLC编码分成扫描和编码2部分,见图2。由zig-zag逆序扫描、统计、编码、码流整合4个模块组成。zig-zag模块和统计模块构成扫描部分,编码模块和码流整合模块构成编码部分,系统采用状态机控制。由于trailing_ones_sign_flag、level和run_before都是从zig-zag扫描后序列的尾部开始编码,所以本设计中zig-zag采用逆序扫描。统计模块用计数器统计zig-zag逆序扫描输出序列的TC、T1和T0,将尾1符号(T1_sign)、除尾1外的非零系数(coeffs)和零的游程(runbefore)存入缓存器并输出。编码模块分成6个子模块:NC生成模块、coeff_token模块、trailing_ones_sign_flag模块、level模块、total_zeros模块以及run_before模块。统计模块给各编码子模块提供输入数据,保证各编码子模块并行工作,减少了CAVLC编码的时钟周期,提高了编码器执行效率。由于CAVLC编码是变长的,使得每个编码子模块的输出码流长度不确定,各编码子模块的码字寄存器宽度不同。为了保证各编码子模块生成的码字能够紧凑无缝链接和有效存储,在各编码子模块的码字输出中嵌入输出标志信号和码长信息,当输出标志信号为高电平时码字与码长有效,低电平时则无效,经码流整合模块整合后输出。

2.2 level编码的优化实现
非零系数级编码是CAVLC编码中复杂度最高、计算量最大、编码延时最长的部分也是CAVLC编码器高速、高效运行的瓶颈之一。根据H.264中CAVLC的level解码步骤可设计出相应的编码流程,如图3所示。
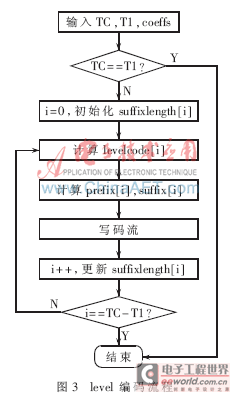
(1)初始化suffixlength为0,如果TC>10,并且T1<3,则初始化为1。
(2)计算中间变量levelcode[ i]:

(5)写码字。
非零系数级的码字为“前缀码字+后缀码字”,前缀码字为prefix个0后紧跟一个1(即前缀码字为1,码长为prefix+1),后缀码字值为suffix,码长为levelsuffixsize。
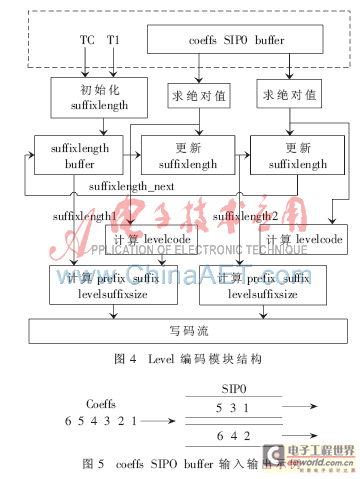
依据图3编码流程,level编码所需的时钟周期与TC和T1之差有关,不同的数据块所需的时钟周期不同,而编码前需经过扫描和统计。当非零系数较多时,level编码采用传统的串行方式所需的时钟周期可能比统计模块所耗要多,导致不稳定的吞吐量。另一方面,获得level的码字需知道该系数的prefix、suffix以及levelsuffixsize,而levelsuffixsize的大小是自适应变化的,与上一个已编码系数的绝对值大小有关,这给并行处理带来了一定困难。为此,采用并行处理和两级流水线相结合的结构并行处理2个非零系数,如图4所示。第一级初始化suffixlength,求coeffs的绝对值及中间变量levelcode;第二级更新suffixlength,计算prefix,suffix和levelsuffixlength。模块coeffs SIPO buffer实现串行输入并行输出,输入输出关系如图5所示。
3 实验验证分析
Level编码电路结构采用Verilog HDL语言描述,在ModelSim SE 6.0上进行仿真,使用Synplicity公司的Synplify Pro完成综合过程。最后采用Xilinx公司VirtexⅡ系列的xc2v250 FPGA进行实现和验证。
图6给出了ModelSim的仿真波形,其结果与JVT校验软件模型JM16.2的值一致。从图6可以看出,并行编码TC-T1个level值比串行方式节省(TC-T1)/2个时钟周期,当非零系数较多时,也能获得稳定的吞吐量。表1给出了Synplify Pro综合的硬件资源报告。系统允许的最高时钟频率为158.1 MHz,硬件资源消耗如表1所示。综上所述,本设计满足H.264实时高清视频编码的要求。


1 CAVLC原理
CAVLC是一种依据4×4块变换系数的zig-zag扫描顺序进行的编码算法。块系数的非零系数幅值较小,主要集中在低频段,经过zig-zag扫描后,连续零的个数较多,采用run-level游程编码,通过编码5个语义元素能够实现高效无损压缩,编码流程如图1所示。zig-zag扫描后,顺序编码系数标记(coeff_token)。尾1的符号(trailing_ones_sign_flag)、除尾1外非零系数的级(level),最后一个非零系数前零的个数(total_zeros)和零的游程(run_before)。其中TC、T1、T0分别表示非零系数个数、尾1个数以及最后一个非零系数前零的个数。由于CAVLC编码流程是串行的,软件容易实现,但执行速度慢且效率低。
2 CAVLC编码器硬件结构设计
2.1 并行化编码结构
为了提高运算速度和效率,将图1的CAVLC编码流程并行化处理,适合FPGA实现。根据文献提出的思路,将CAVLC编码分成扫描和编码2部分,见图2。由zig-zag逆序扫描、统计、编码、码流整合4个模块组成。zig-zag模块和统计模块构成扫描部分,编码模块和码流整合模块构成编码部分,系统采用状态机控制。由于trailing_ones_sign_flag、level和run_before都是从zig-zag扫描后序列的尾部开始编码,所以本设计中zig-zag采用逆序扫描。统计模块用计数器统计zig-zag逆序扫描输出序列的TC、T1和T0,将尾1符号(T1_sign)、除尾1外的非零系数(coeffs)和零的游程(runbefore)存入缓存器并输出。编码模块分成6个子模块:NC生成模块、coeff_token模块、trailing_ones_sign_flag模块、level模块、total_zeros模块以及run_before模块。统计模块给各编码子模块提供输入数据,保证各编码子模块并行工作,减少了CAVLC编码的时钟周期,提高了编码器执行效率。由于CAVLC编码是变长的,使得每个编码子模块的输出码流长度不确定,各编码子模块的码字寄存器宽度不同。为了保证各编码子模块生成的码字能够紧凑无缝链接和有效存储,在各编码子模块的码字输出中嵌入输出标志信号和码长信息,当输出标志信号为高电平时码字与码长有效,低电平时则无效,经码流整合模块整合后输出。
2.2 level编码的优化实现
非零系数级编码是CAVLC编码中复杂度最高、计算量最大、编码延时最长的部分也是CAVLC编码器高速、高效运行的瓶颈之一。根据H.264中CAVLC的level解码步骤可设计出相应的编码流程,如图3所示。
(1)初始化suffixlength为0,如果TC>10,并且T1<3,则初始化为1。
(2)计算中间变量levelcode[ i]:
(5)写码字。
非零系数级的码字为“前缀码字+后缀码字”,前缀码字为prefix个0后紧跟一个1(即前缀码字为1,码长为prefix+1),后缀码字值为suffix,码长为levelsuffixsize。
依据图3编码流程,level编码所需的时钟周期与TC和T1之差有关,不同的数据块所需的时钟周期不同,而编码前需经过扫描和统计。当非零系数较多时,level编码采用传统的串行方式所需的时钟周期可能比统计模块所耗要多,导致不稳定的吞吐量。另一方面,获得level的码字需知道该系数的prefix、suffix以及levelsuffixsize,而levelsuffixsize的大小是自适应变化的,与上一个已编码系数的绝对值大小有关,这给并行处理带来了一定困难。为此,采用并行处理和两级流水线相结合的结构并行处理2个非零系数,如图4所示。第一级初始化suffixlength,求coeffs的绝对值及中间变量levelcode;第二级更新suffixlength,计算prefix,suffix和levelsuffixlength。模块coeffs SIPO buffer实现串行输入并行输出,输入输出关系如图5所示。
3 实验验证分析
Level编码电路结构采用Verilog HDL语言描述,在ModelSim SE 6.0上进行仿真,使用Synplicity公司的Synplify Pro完成综合过程。最后采用Xilinx公司VirtexⅡ系列的xc2v250 FPGA进行实现和验证。
图6给出了ModelSim的仿真波形,其结果与JVT校验软件模型JM16.2的值一致。从图6可以看出,并行编码TC-T1个level值比串行方式节省(TC-T1)/2个时钟周期,当非零系数较多时,也能获得稳定的吞吐量。表1给出了Synplify Pro综合的硬件资源报告。系统允许的最高时钟频率为158.1 MHz,硬件资源消耗如表1所示。综上所述,本设计满足H.264实时高清视频编码的要求。
电路 FPGA 编码器 Verilog ModelSim 仿真 Xilinx 相关文章:
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 基于PLB总线的H.264整数变换量化软核的设计(03-20)
- FPGA按键模式的研究与设计(03-24)
- 周立功:如何兼顾学习ARM与FPGA(05-23)