高速流水线浮点加法器的FPGA实现
时间:11-09
来源:互联网
点击:
(3)sum模块
本模块可根据加减选择(sft_addsub(信号完成两输入浮点数尾数(已加入隐含1)的加减,若sft_bexp、sft_sma、sft_bma、sft_csgn、sft_addsub为输入信号(其含义见shift模块),则可输出如下运算结果(在一个时钟周期内完成):
◇大数指数(sum_bexp),将sft_bexp信号用寄存器延迟一个周期,以实现时序同步;
◇尾数和(sum_ma),为大数尾数与移位后小数尾数的和,差(两尾数已加入隐含1);
◇和符号(sum_csgn),将sft_csgn信号用寄存器延迟一个周期,以实现时序同步;
(4)normalize模块
normalize模块的作用主要是将前三个模块的运算结果规范为IEEE 754单精度浮点数标准,若sum_bexp、sum_ma、sum_csgn为输入信号(其含义见sum模块),则其输出的运算结果(在一个时钟周期内完成)只有一个和输出(data_out),也就是符合IEEE754浮点数标准的两个输入浮点数的和。
4 系统综合与仿真
由于本工程是由compare、shift、sum、normalize四个模块组成的,而这四个模块通过串行方式进行连接,每个模块的操作都在一个时钟周期内完成,因此,整个浮点数加法运算可在四个时钟周期内完成。这使得工程不仅有确定的数据运算时延(latency),便于流水线实现,而且方便占用的时钟周期尽可能减少,从而极大地提高了运算的实时性。
4.1 工程综合结果
经过Quartus II综合可知,本设计使用的StratixⅡEP2S15F484C3芯片共使用了641个ALUT(高级查找表)、188个寄存器、0位内存和可达到80 MHz的时钟频率,因此可证明,本系统利用合理的资源实现了高速浮点数加法运算。
4.2 工程仿真结果
本工程仿真可使用Quartus II 8.0内嵌式仿真工具来编写Matlab程序,以生成大量随机单精度浮点数(以便于提高仿真代码覆盖率,提高仿真的精确度),然后计算它们相加的结果,并以文本形式存放在磁盘文件中。编写Matlab程序可产生作为仿真输入的*.vec文件,然后通过时序仿真后生成*.tbl文件,再编写Matlab程序提取其中有用的结果数据,并与先前磁盘文件中的结果相比较,以验证设计的正确性。
图3所示是其仿真的波形图。
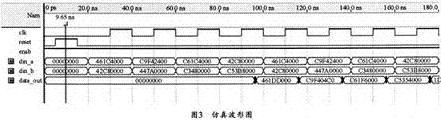
从图3可以看出表1所列的各种运算关系。表2所列为其实际的测试数据。
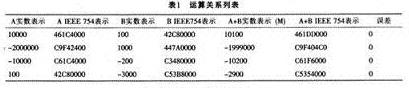
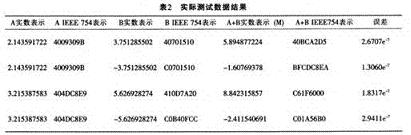
表中“A+B实数表示(M)”指Matlab计算的结果;“误差”指浮点处理器计算结果与Matlab计算结果之差。
综上所述,本工程设计的浮点加法器所得到的运算结果与Matlab结果的误差在10-7左右,可见其精度完全能够符合要求。
5 结束语
本工程设计完全符合IP核设计的规范流程,而且完成了Verilog HDL建模、功能仿真、综合、时序仿真等IP核设计的整个过程,电路功能正确。实际上,本系统在布局布线后,其系统的最高时钟频率可达80MHz。虽然使用浮点数会导致舍入误差,但这种误差很小,可以忽略。实践证明,本工程利用流水线结构,方便地实现了高速、连续、大数据量浮点数的加法运算,而且设计结构合理,性能优异,可以应用在高速信号处理系统中。
本模块可根据加减选择(sft_addsub(信号完成两输入浮点数尾数(已加入隐含1)的加减,若sft_bexp、sft_sma、sft_bma、sft_csgn、sft_addsub为输入信号(其含义见shift模块),则可输出如下运算结果(在一个时钟周期内完成):
◇大数指数(sum_bexp),将sft_bexp信号用寄存器延迟一个周期,以实现时序同步;
◇尾数和(sum_ma),为大数尾数与移位后小数尾数的和,差(两尾数已加入隐含1);
◇和符号(sum_csgn),将sft_csgn信号用寄存器延迟一个周期,以实现时序同步;
(4)normalize模块
normalize模块的作用主要是将前三个模块的运算结果规范为IEEE 754单精度浮点数标准,若sum_bexp、sum_ma、sum_csgn为输入信号(其含义见sum模块),则其输出的运算结果(在一个时钟周期内完成)只有一个和输出(data_out),也就是符合IEEE754浮点数标准的两个输入浮点数的和。
4 系统综合与仿真
由于本工程是由compare、shift、sum、normalize四个模块组成的,而这四个模块通过串行方式进行连接,每个模块的操作都在一个时钟周期内完成,因此,整个浮点数加法运算可在四个时钟周期内完成。这使得工程不仅有确定的数据运算时延(latency),便于流水线实现,而且方便占用的时钟周期尽可能减少,从而极大地提高了运算的实时性。
4.1 工程综合结果
经过Quartus II综合可知,本设计使用的StratixⅡEP2S15F484C3芯片共使用了641个ALUT(高级查找表)、188个寄存器、0位内存和可达到80 MHz的时钟频率,因此可证明,本系统利用合理的资源实现了高速浮点数加法运算。
4.2 工程仿真结果
本工程仿真可使用Quartus II 8.0内嵌式仿真工具来编写Matlab程序,以生成大量随机单精度浮点数(以便于提高仿真代码覆盖率,提高仿真的精确度),然后计算它们相加的结果,并以文本形式存放在磁盘文件中。编写Matlab程序可产生作为仿真输入的*.vec文件,然后通过时序仿真后生成*.tbl文件,再编写Matlab程序提取其中有用的结果数据,并与先前磁盘文件中的结果相比较,以验证设计的正确性。
图3所示是其仿真的波形图。
从图3可以看出表1所列的各种运算关系。表2所列为其实际的测试数据。
表中“A+B实数表示(M)”指Matlab计算的结果;“误差”指浮点处理器计算结果与Matlab计算结果之差。
综上所述,本工程设计的浮点加法器所得到的运算结果与Matlab结果的误差在10-7左右,可见其精度完全能够符合要求。
5 结束语
本工程设计完全符合IP核设计的规范流程,而且完成了Verilog HDL建模、功能仿真、综合、时序仿真等IP核设计的整个过程,电路功能正确。实际上,本系统在布局布线后,其系统的最高时钟频率可达80MHz。虽然使用浮点数会导致舍入误差,但这种误差很小,可以忽略。实践证明,本工程利用流水线结构,方便地实现了高速、连续、大数据量浮点数的加法运算,而且设计结构合理,性能优异,可以应用在高速信号处理系统中。
FPGA 电路 Quartus Altera 仿真 Verilog 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)