使用基于图形的物理综合加快FPGA设计时序收敛
时间:09-03
来源:互联网
点击:
布局优化
随着底层规划在 ASIC 领域的作用逐渐弱化,在上世纪 90 年代中期, IPO 技术对其进行了强化 / 或者替代。这再次地涉及到时序分析和估计是基于连接线负载模型的综合。
在这种情况下,所产生的网表被传递到下游的布局布线引擎。在布局布线和寄生提取之后,实际的延时被背注到综合引擎。这些新值触发器在综合引擎中的递增优化,例如逻辑重构和复制。其结果是得到一个被部分修改的新网表。然后,这个网表被递交到递增布局布线引擎,产生一个改进的设计拓扑。
基于 IPO 流程所得到的最后结果比那些采用底层规划方法获得的通常更好。然而,这种方法同样可能需要在前端和后端工具之间进行很多次设计反复。而且基于 IPO 方法的一个重要的问题是对布局布线的修改可能导致新的关键路径,这个路径在前一次反复中是看不到的,即修正一个问题可能会激起其它的问题,这可能导致收敛的问题。
对于 FPGA 设计,基于 IPO 的设计流程大约在 2003 年开始受到主流关注。然而,尽管这样的流程已经可用,但那时这些流程并没有以一种有意义的方式得到采用,因为单个地优化时序路径的 IPO 技术通常导致其它路径时序的劣化和时序收敛不完全。设计师需要可使他们在不牺牲之前设计版本获得的成果的基础上对设计进行改变的可靠结果。但是基于 IPO 的方法并不能在多次设计反复之上产生稳定的结果,因为在一次反复中优化关键路径会在下一次反复中产生新的关键路径。类似地,增加约束以改进一个区域的时序可能使其它的区域的时序恶化。
具有物理意识的综合
当前先进的 ASIC 综合技术是具有物理意识的综合,这种综合技术在大约 2000 年开始受到主流关注。不考虑实际的技术 ( 有几种不同的算法 ) ,具有物理意识的综合的基本概念是在一次性完成的过程中结合布局和综合。
这在 ASIC 领域中的实践效果很好,因为了解布局的综合引擎能根据已布局的单元的周边和 Steiner 以及 Manhattan 布线估计进行时序的预估。这种综合方法在 ASIC 中效果很好的原因是连接线有序地布置。这意味着与最后的布局和布线设计相关的延时与综合引擎所估计的结果具有非常好的相关性。
从 2002 年到 2003 年期间开始,很多的 EDA 供应商开始考虑将从 ASIC 中得到的具有物理意识的综合技术应用到 FPGA 设计中,但是他们并没有进一步将这种思路深入下去,而 Synplicity 公司新的基于图形的综合方法是一个例外,现在没有供应商能提供具有布局意识的 RTL 综合工具用于 FPGA 设计。问题是,与 ASIC 中的连线 “ 按序构建 ” 不同的是, FPGA 具有固定数量的预先确定的布线资源,并不是所有的布线都设置成一样 ( 某些连线短且快,某些长而快,某些短而慢,某些长而慢 ) 。
对于实际的情况而言,基于 ASIC 的具有物理意识的综合可以根据形成设计的已布局单元的附近来进行布线和时序估计。而对于 FPGA 来说,将两个逻辑功能放在相邻的区域并不一定能实现它们之间的快速连接。 - 取决于可用的布线资源,将相连接的逻辑功能布局位置更远可能反而能获得更好的布线和时序结果,尽管这有一点违背常理。这就是为什么从 ASIC 设计中得来的具有物理意识的综合技术用于 FPGA 架构时并不能得到最佳结果的原因。同样,使用这些技术的设计流程需要大量耗时的前端 ( 综合 ) 与后端 ( 布局与布线 ) 引擎之间的设计反复,以获得相关性和时序收敛。
与 FPGA 架构相关的一些考量
在详细介绍基于图形的物理综合概念之前,先了解设计任务的复杂性很重要。正如前面谈到的, FPGA 具有固定的连接资源,所有连线已经构建好,但并不是所有的路径都是一样的 ( 有短的、中等的和长的连线,而每个连线都可能具有快、中等或者慢的特性 ) 。
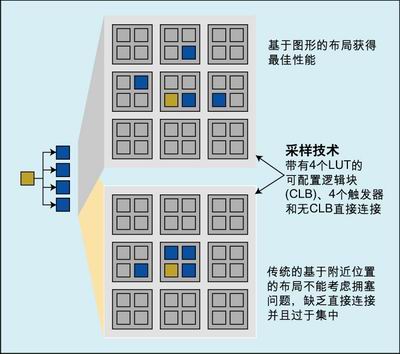
图 2 :比较传统和基于图形的布局。
每个路径都可能具有多个 “ 抽头点 ”( 就像高速路的出口道 ) 。这里的问题是,你可能具有一个能迅速地将一个信号从源点函数 ( 高速路的最初的入口道 ) 快速地传递到一个目的函数 ( 高速路的最后出口道 ) 的快速路径。然而,如果我们对一个内部抽头点增加第二个目的函数,这可能大大地减慢信号速度。
而且,当今 FPGA 的主流架构基于一个查找表 (LUT) 具有几个输入和单个输出的概念。一些 FPGA 架构具有通过与查找表相关的每个输入输出路径的不同延时。然而,更重要的事实是,到 LUT 的每个输入可能只能使用一部分的不同连线类型。如果来自一个 LUT 的输出驱动另外一个 LUT ,它们之间可能同时存在慢速和快速的路径,这取决于我们在接收 LUT 上所使用的特定输入 。
总的情形被 FPGA 架构的分层特性进一步复杂化。例如,一个小的逻辑模块可能有几个 LUT ;在一个较大的逻辑模块中有几个这样的小模块;在整个的 FPGA 中具有大量的这种大逻辑模块。在这些大逻辑模块中的某个逻辑块中,一个 LUT 的输出与另外一个 LUT 的输入直接相连接的概率很小;为了实现额外的连接,可能必须绕道逻辑模块的外部,然后再绕回到模块内部来实现。这一点再次地说明所处理问题的复杂性:如果你知道将它们放置在什么地方以及使用哪个引脚,将两个对象 / 实例放在不同的逻辑模块将获得比放在采用非最佳互连资源的同一模块中会得到更短的延时。
另外,任何被提出的综合方案必须解决围绕固定的硬宏资源,例如 RAM 、乘法器等相关的连线延时。同样的,方案必须解决增加的布线拥塞,这种拥塞常出现在靠近这些硬宏的地方。所有这些硬宏都属于特定器件具有的,因此任何被提出的方案必须能用于每个 FPGA 系列的每个器件。
随着底层规划在 ASIC 领域的作用逐渐弱化,在上世纪 90 年代中期, IPO 技术对其进行了强化 / 或者替代。这再次地涉及到时序分析和估计是基于连接线负载模型的综合。
在这种情况下,所产生的网表被传递到下游的布局布线引擎。在布局布线和寄生提取之后,实际的延时被背注到综合引擎。这些新值触发器在综合引擎中的递增优化,例如逻辑重构和复制。其结果是得到一个被部分修改的新网表。然后,这个网表被递交到递增布局布线引擎,产生一个改进的设计拓扑。
基于 IPO 流程所得到的最后结果比那些采用底层规划方法获得的通常更好。然而,这种方法同样可能需要在前端和后端工具之间进行很多次设计反复。而且基于 IPO 方法的一个重要的问题是对布局布线的修改可能导致新的关键路径,这个路径在前一次反复中是看不到的,即修正一个问题可能会激起其它的问题,这可能导致收敛的问题。
对于 FPGA 设计,基于 IPO 的设计流程大约在 2003 年开始受到主流关注。然而,尽管这样的流程已经可用,但那时这些流程并没有以一种有意义的方式得到采用,因为单个地优化时序路径的 IPO 技术通常导致其它路径时序的劣化和时序收敛不完全。设计师需要可使他们在不牺牲之前设计版本获得的成果的基础上对设计进行改变的可靠结果。但是基于 IPO 的方法并不能在多次设计反复之上产生稳定的结果,因为在一次反复中优化关键路径会在下一次反复中产生新的关键路径。类似地,增加约束以改进一个区域的时序可能使其它的区域的时序恶化。
具有物理意识的综合
当前先进的 ASIC 综合技术是具有物理意识的综合,这种综合技术在大约 2000 年开始受到主流关注。不考虑实际的技术 ( 有几种不同的算法 ) ,具有物理意识的综合的基本概念是在一次性完成的过程中结合布局和综合。
这在 ASIC 领域中的实践效果很好,因为了解布局的综合引擎能根据已布局的单元的周边和 Steiner 以及 Manhattan 布线估计进行时序的预估。这种综合方法在 ASIC 中效果很好的原因是连接线有序地布置。这意味着与最后的布局和布线设计相关的延时与综合引擎所估计的结果具有非常好的相关性。
从 2002 年到 2003 年期间开始,很多的 EDA 供应商开始考虑将从 ASIC 中得到的具有物理意识的综合技术应用到 FPGA 设计中,但是他们并没有进一步将这种思路深入下去,而 Synplicity 公司新的基于图形的综合方法是一个例外,现在没有供应商能提供具有布局意识的 RTL 综合工具用于 FPGA 设计。问题是,与 ASIC 中的连线 “ 按序构建 ” 不同的是, FPGA 具有固定数量的预先确定的布线资源,并不是所有的布线都设置成一样 ( 某些连线短且快,某些长而快,某些短而慢,某些长而慢 ) 。
对于实际的情况而言,基于 ASIC 的具有物理意识的综合可以根据形成设计的已布局单元的附近来进行布线和时序估计。而对于 FPGA 来说,将两个逻辑功能放在相邻的区域并不一定能实现它们之间的快速连接。 - 取决于可用的布线资源,将相连接的逻辑功能布局位置更远可能反而能获得更好的布线和时序结果,尽管这有一点违背常理。这就是为什么从 ASIC 设计中得来的具有物理意识的综合技术用于 FPGA 架构时并不能得到最佳结果的原因。同样,使用这些技术的设计流程需要大量耗时的前端 ( 综合 ) 与后端 ( 布局与布线 ) 引擎之间的设计反复,以获得相关性和时序收敛。
与 FPGA 架构相关的一些考量
在详细介绍基于图形的物理综合概念之前,先了解设计任务的复杂性很重要。正如前面谈到的, FPGA 具有固定的连接资源,所有连线已经构建好,但并不是所有的路径都是一样的 ( 有短的、中等的和长的连线,而每个连线都可能具有快、中等或者慢的特性 ) 。
图 2 :比较传统和基于图形的布局。
每个路径都可能具有多个 “ 抽头点 ”( 就像高速路的出口道 ) 。这里的问题是,你可能具有一个能迅速地将一个信号从源点函数 ( 高速路的最初的入口道 ) 快速地传递到一个目的函数 ( 高速路的最后出口道 ) 的快速路径。然而,如果我们对一个内部抽头点增加第二个目的函数,这可能大大地减慢信号速度。
而且,当今 FPGA 的主流架构基于一个查找表 (LUT) 具有几个输入和单个输出的概念。一些 FPGA 架构具有通过与查找表相关的每个输入输出路径的不同延时。然而,更重要的事实是,到 LUT 的每个输入可能只能使用一部分的不同连线类型。如果来自一个 LUT 的输出驱动另外一个 LUT ,它们之间可能同时存在慢速和快速的路径,这取决于我们在接收 LUT 上所使用的特定输入 。
总的情形被 FPGA 架构的分层特性进一步复杂化。例如,一个小的逻辑模块可能有几个 LUT ;在一个较大的逻辑模块中有几个这样的小模块;在整个的 FPGA 中具有大量的这种大逻辑模块。在这些大逻辑模块中的某个逻辑块中,一个 LUT 的输出与另外一个 LUT 的输入直接相连接的概率很小;为了实现额外的连接,可能必须绕道逻辑模块的外部,然后再绕回到模块内部来实现。这一点再次地说明所处理问题的复杂性:如果你知道将它们放置在什么地方以及使用哪个引脚,将两个对象 / 实例放在不同的逻辑模块将获得比放在采用非最佳互连资源的同一模块中会得到更短的延时。
另外,任何被提出的综合方案必须解决围绕固定的硬宏资源,例如 RAM 、乘法器等相关的连线延时。同样的,方案必须解决增加的布线拥塞,这种拥塞常出现在靠近这些硬宏的地方。所有这些硬宏都属于特定器件具有的,因此任何被提出的方案必须能用于每个 FPGA 系列的每个器件。
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)