榨干FPGA片上存储资源
时间:08-23
来源:互联网
点击:
记得Long long time ago,特权同学写过一篇简短的博文《M4K使用率》,文章中提到了Cyclone器件的内嵌存储块M4K的配置问题。文中提到了这个M4K块除了存储大小是有限的4Kbit,它的可配置的Port数量也是有限的,通常为最大36个可用port。
当时只是简单的提到有这么回事,提醒使用者注意,也没有具体的谈到如何解决或者确切的说应该是避免这样的状况出现。因此,本文将结合特权同学近期在使用FPGA时,配置片内存储器遇到的一些片内资源无法得到充分利用的问题,更深入的探讨如何在既有的基础上优化我们的配置,也就是标题所言,我们的目标是“榨干FPGA的片上存储资源”。
关于如何在综合或布局布线后查看FPGA的片上存储资源的使用情况,就Quartus II软件,这里要先教大家几招,让大家在系统设计完后对自己的存储资源情况做到明明白白、心中有数,这对将来的产品维护、升级乃至完全推到重来都是有助益的。很好,想必您已经等不及了,那么就ReadyàGo!
在一个工程完全编译后,Quartus II会弹出一个全新的Compilation Report,首先映入设计者眼帘的是Flow Summary页面。当然设计者也可以如图1所示,直接找到菜单栏点击ProcessingàCompilation Report选项查看。

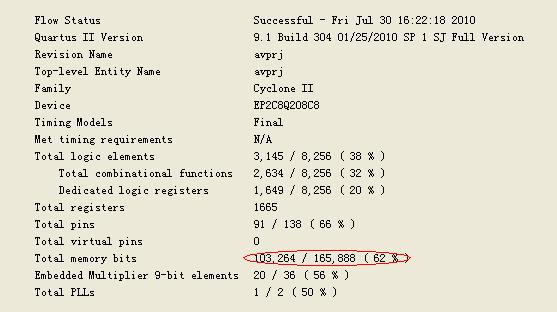
再看Flow Summary页面,如图2所示,其他选项这里不说了,就看Total memory bits后圈出来的部分:103,264/165,888(62%)。这里意思也很明白,特权使用的器件EP2C8Q208C8的片内存储器总大小是 165,888bit,而在该工程中使用了103,264bit,使用率是62%。
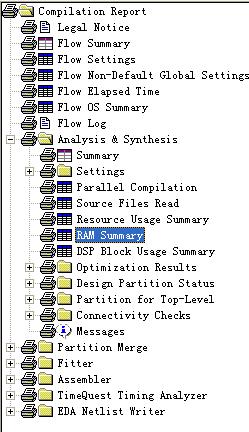
OK,那么我们再来看看详细的存储资源都用在哪里了。如图3所示,点开编译报告的Analysis&SynthesisàRAM Summary。
同时在页面右侧就弹出如图4所示的详细的存储资源分配情况。在这个页面的报告中,我们只能简单的看到存储资源的详细使用位置、存储资源类型(即是使用了专用的片内存储资源还是用逻辑资源构造的,显然用逻辑资源是很浪费甚至说不现实的)、存储器类型(即RAM/ROM/FIFO等)、存储器的位宽和深度信息以及存储量大小,还有就是是否有初始化文件映射。

因为是综合报告的一部分,所以不针对特定的器件给出一些信息,如这里我们可能还会关心文章开头就提到的M4K块使用数量甚至是我们所例化的存储器具体都使用了哪些M4K块。不用担心,咱的这点好奇心开发商还是能够满足的。下面我们就接着打开编译报告里的FitteràResource SectionàRAM Summary选项(方法同图3)。我们可以看到如图5所示的,哦,很抱歉由于页宽有限,所以name一栏没有完全显示,Location一栏也只是“小荷才露尖尖角”,但是不要紧,只要你领会精神。先说这个Location一栏,它就是前面提到设计者可能关心的具体的M4K块都是哪些,而M4Ks一栏就是使用的M4K块的数量,其他选项类同,读者可以自己分析。看到这些,估计已经是一目了然了,设计者对自己例化的每一个片内存储器的具体的使用情况都应该有所了解。

但是,估计细心的读者会问,我知道了我所例化的每个存储器的M4K块使用数量,那么我怎么知道是否超出了器件所有的数量,难道非要等到编译出 error才行吗?或者自己在这个页面掐指算算再找来handbook比对一下吗?非也,其实用户只要点开FitteràResource SectionàResource Usage Summary,如图6所示,里面罗列了非常详细的FPGA所有片上资源的使用情况,圈出来的部分也是这里我们需要重点关注的地方。M4Ks里指明器件的 36个M4K块使用了26个,占用率72%;而Total block memory bits和前面综合报告里是一样的,严格的说,这个数据应该算是片内存储资源的绝对使用情况;最后说Total block memory implementation bits选项,它是最终实现到FPGA器件上的片上资源占用情况(注意这里只能是占用而非使用,汉语文字真是博大精深,也许有些时候两个词怎么用都差不多,但是这里特权同学想区分这个概念,所以刻意要提醒大家注意,因为,它还涉及本文的主题,哈哈,不好意思,有点班门弄斧了),它的占用率和M4Ks是一致的,并且必须是一致的。

那么好,“工欲善其事,必先利其器”,我们利完器,就来说正事。特权同学提出一个概念,就是FPGA片上资源的利用率,他的公式为:(Total block memory bits/Total block memory implementation bits),对于该设计就是(62% / 72%) = 86.11%,应该说是个不错的数据(呵呵,悄悄的告诉你,这个实例可是被特权同学优化过了)。
说完这些概念,我们可以真刀真枪的玩一玩了,理论永远只是理论,要提高必须靠实践。其实可以把这个工程打回原形,退回优化前的情况。由于篇幅关系,这里只讨论它优化过程中的一个最显著的例子。
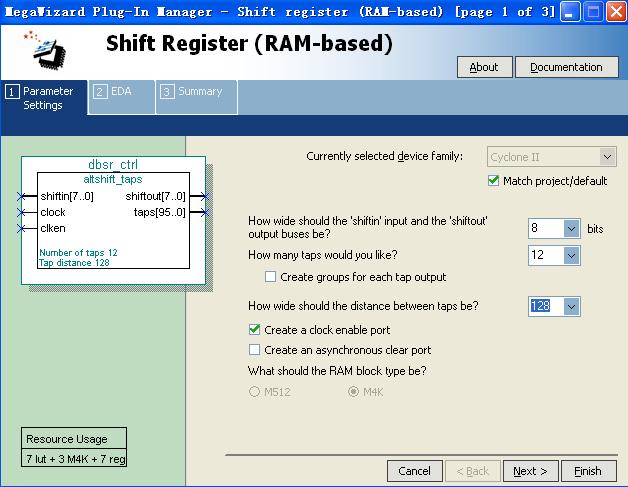
在这个工程中,有一连串的8bit数据流,第1个数据要和第1280个数据做一些处理。因此,最简单的想法就是例化一个1280*8bit的移位寄存器。并且这个移位寄存器在第一个移入的数据移出时,要和此时要正要移入的数据做一些处理。但是,在配置移位寄存器的时候遇到了一些麻烦,如图8所示,移位寄存器的深度一般是用配置的taps数量乘以distance值(建议对移位寄存器配置的相关知识还不熟悉的朋友参考特权同学的另一篇博文《Cyclone M4K移位寄存器使用》)。而这里distance值最大只能配置为256,需要1280个寄存器,并且只用一个taps的想法破灭了,于是思考了下:发现256*5/128*10/64*20都是可行的办法。
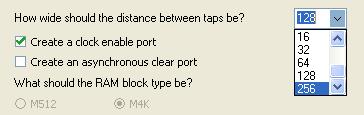
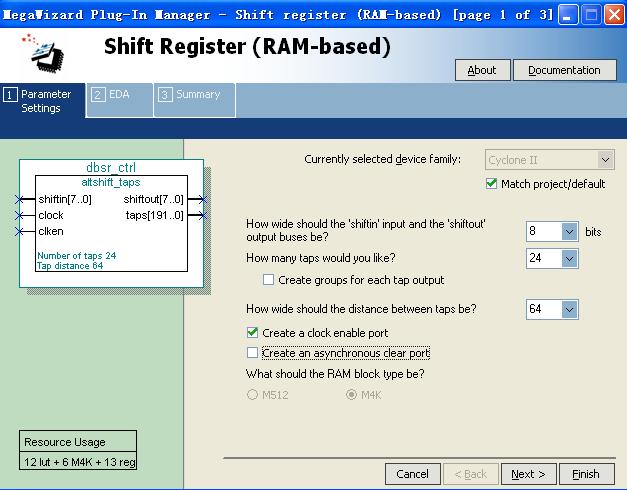
刚开始配置的时候没有太多考虑,就选择了64*20的方案,即配置taps = 24(因为taps值只能为可选的1/2/3/4/5/6/7/8/12/16/24/32/48/64/96/128,这里配置为24个taps,而使用的时候取taps输出的bit159-152,实际综合的时候其实会把4个不用的taps优化掉),distance = 64。
如图8所示。如果你够细心,你应该发现了左下角的Resource Usage是6 M4K。
然后就着这样的配置,在编译后可以使用前面提到的方法查看一下存储器资源的使用情况。因为我们重点要算FPGA片上资源的利用率,所以还是查看 FitteràResource SectionàResource Usage Summary这个报告吧。如图9所示,这个报告中的Total block memory bits和之前没有变,都是62%,而M4Ks占用多了2个,相应的M4Ks占用率和Total block memory implementation bits占用率增加到了78%。计算一下,(62% / 78%) = 79.5%,下降了近7个百分点。也许这个参数说明不了问题,但是在资源紧张的时候,这个问题就是最挠人的问题。

再提特权同学发现问题后,如何处置优化提高了这里的利用率(实际上,如果真用EP2C8Q完成这个工程,也不是非得做这个优化的工作,只不过最终的设计是要实现在向下兼容的EP2C5Q上,所以,就诞生了这篇文章的故事……)?很简单,前面其实都已经给了大家暗示,移位寄存器的存储资源利用率不高不是因为本身存储量大(只有1280*8bit=10Kbit,需要3个M4K足够),而是因为生成的taps占用的port过多,前面配置24个taps就占用了6个M4K块,那么如果配置成12个taps,distance值为128会怎样呢?6个taps,distance值为256会怎样呢?答案马上揭晓,如图10所示。其实两者都是占用了3个M4K。这里做的变化就是最终优化成功的玄机。
如图11所示,其实这个工程最终实现到EP2C5Q上是没有问题的,但是如果没有类似移位寄存器例子中的一些优化,存储器资源还是很紧张的。

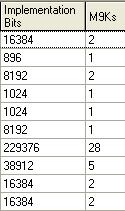
说到这里,虽然已经洋洋洒洒图文并茂好长一篇文章了。但是,还是很想再提一些和FPGA片上存储资源相关的问题。关于Cyclone/Cyclone II的M4K到Cyclone III的M9K,可能还有一些M512,将来不知道会不会有什么M32K/M128K/M1M云云的概念出来。但是就特权同学对目前器件使用的一点经验上来看,这个MXX的块存储量越大,虽然总的存储量也会越来越大(不能否定它能够满足片内大存储量应用的需求),但是相应的在工程需要的很多小存储应用中对存储块的利用率也会越来越低。因为,对于用户例化的任何一个存储器,如果使用M4K块实现一个8bit的512B/256B/128B/64B甚至哪怕只有1B的应用,其实他们都需要占用1个M4K块。打一个更形象更极端的例子,我的设计中需要两个1*8bit的FIFO(当然实际应用中没有人这么傻,^o^),那么例化完编译后,我的M4K资源别占用了2个,这就是问题。这也是制约着极大多数的应用中,特权同学提到的FPGA片内存储资源利用率无法100%的原因。其实,这也是最近特权同学的另一个项目中搭建的NIOS2平台,如图12所示,各种简单的外设都分别要占用一点片内存储器(没有充分的利用M9K的资源),直接导致整个利用率很低的原因。针对与这种情况,不知道器件厂商是否有所考虑,也许对他们而言,也是处在一种鱼和熊掌不可兼得的矛盾之中。
当时只是简单的提到有这么回事,提醒使用者注意,也没有具体的谈到如何解决或者确切的说应该是避免这样的状况出现。因此,本文将结合特权同学近期在使用FPGA时,配置片内存储器遇到的一些片内资源无法得到充分利用的问题,更深入的探讨如何在既有的基础上优化我们的配置,也就是标题所言,我们的目标是“榨干FPGA的片上存储资源”。
关于如何在综合或布局布线后查看FPGA的片上存储资源的使用情况,就Quartus II软件,这里要先教大家几招,让大家在系统设计完后对自己的存储资源情况做到明明白白、心中有数,这对将来的产品维护、升级乃至完全推到重来都是有助益的。很好,想必您已经等不及了,那么就ReadyàGo!
在一个工程完全编译后,Quartus II会弹出一个全新的Compilation Report,首先映入设计者眼帘的是Flow Summary页面。当然设计者也可以如图1所示,直接找到菜单栏点击ProcessingàCompilation Report选项查看。
再看Flow Summary页面,如图2所示,其他选项这里不说了,就看Total memory bits后圈出来的部分:103,264/165,888(62%)。这里意思也很明白,特权使用的器件EP2C8Q208C8的片内存储器总大小是 165,888bit,而在该工程中使用了103,264bit,使用率是62%。
OK,那么我们再来看看详细的存储资源都用在哪里了。如图3所示,点开编译报告的Analysis&SynthesisàRAM Summary。
同时在页面右侧就弹出如图4所示的详细的存储资源分配情况。在这个页面的报告中,我们只能简单的看到存储资源的详细使用位置、存储资源类型(即是使用了专用的片内存储资源还是用逻辑资源构造的,显然用逻辑资源是很浪费甚至说不现实的)、存储器类型(即RAM/ROM/FIFO等)、存储器的位宽和深度信息以及存储量大小,还有就是是否有初始化文件映射。
因为是综合报告的一部分,所以不针对特定的器件给出一些信息,如这里我们可能还会关心文章开头就提到的M4K块使用数量甚至是我们所例化的存储器具体都使用了哪些M4K块。不用担心,咱的这点好奇心开发商还是能够满足的。下面我们就接着打开编译报告里的FitteràResource SectionàRAM Summary选项(方法同图3)。我们可以看到如图5所示的,哦,很抱歉由于页宽有限,所以name一栏没有完全显示,Location一栏也只是“小荷才露尖尖角”,但是不要紧,只要你领会精神。先说这个Location一栏,它就是前面提到设计者可能关心的具体的M4K块都是哪些,而M4Ks一栏就是使用的M4K块的数量,其他选项类同,读者可以自己分析。看到这些,估计已经是一目了然了,设计者对自己例化的每一个片内存储器的具体的使用情况都应该有所了解。
但是,估计细心的读者会问,我知道了我所例化的每个存储器的M4K块使用数量,那么我怎么知道是否超出了器件所有的数量,难道非要等到编译出 error才行吗?或者自己在这个页面掐指算算再找来handbook比对一下吗?非也,其实用户只要点开FitteràResource SectionàResource Usage Summary,如图6所示,里面罗列了非常详细的FPGA所有片上资源的使用情况,圈出来的部分也是这里我们需要重点关注的地方。M4Ks里指明器件的 36个M4K块使用了26个,占用率72%;而Total block memory bits和前面综合报告里是一样的,严格的说,这个数据应该算是片内存储资源的绝对使用情况;最后说Total block memory implementation bits选项,它是最终实现到FPGA器件上的片上资源占用情况(注意这里只能是占用而非使用,汉语文字真是博大精深,也许有些时候两个词怎么用都差不多,但是这里特权同学想区分这个概念,所以刻意要提醒大家注意,因为,它还涉及本文的主题,哈哈,不好意思,有点班门弄斧了),它的占用率和M4Ks是一致的,并且必须是一致的。
那么好,“工欲善其事,必先利其器”,我们利完器,就来说正事。特权同学提出一个概念,就是FPGA片上资源的利用率,他的公式为:(Total block memory bits/Total block memory implementation bits),对于该设计就是(62% / 72%) = 86.11%,应该说是个不错的数据(呵呵,悄悄的告诉你,这个实例可是被特权同学优化过了)。
说完这些概念,我们可以真刀真枪的玩一玩了,理论永远只是理论,要提高必须靠实践。其实可以把这个工程打回原形,退回优化前的情况。由于篇幅关系,这里只讨论它优化过程中的一个最显著的例子。
在这个工程中,有一连串的8bit数据流,第1个数据要和第1280个数据做一些处理。因此,最简单的想法就是例化一个1280*8bit的移位寄存器。并且这个移位寄存器在第一个移入的数据移出时,要和此时要正要移入的数据做一些处理。但是,在配置移位寄存器的时候遇到了一些麻烦,如图8所示,移位寄存器的深度一般是用配置的taps数量乘以distance值(建议对移位寄存器配置的相关知识还不熟悉的朋友参考特权同学的另一篇博文《Cyclone M4K移位寄存器使用》)。而这里distance值最大只能配置为256,需要1280个寄存器,并且只用一个taps的想法破灭了,于是思考了下:发现256*5/128*10/64*20都是可行的办法。
刚开始配置的时候没有太多考虑,就选择了64*20的方案,即配置taps = 24(因为taps值只能为可选的1/2/3/4/5/6/7/8/12/16/24/32/48/64/96/128,这里配置为24个taps,而使用的时候取taps输出的bit159-152,实际综合的时候其实会把4个不用的taps优化掉),distance = 64。
如图8所示。如果你够细心,你应该发现了左下角的Resource Usage是6 M4K。
然后就着这样的配置,在编译后可以使用前面提到的方法查看一下存储器资源的使用情况。因为我们重点要算FPGA片上资源的利用率,所以还是查看 FitteràResource SectionàResource Usage Summary这个报告吧。如图9所示,这个报告中的Total block memory bits和之前没有变,都是62%,而M4Ks占用多了2个,相应的M4Ks占用率和Total block memory implementation bits占用率增加到了78%。计算一下,(62% / 78%) = 79.5%,下降了近7个百分点。也许这个参数说明不了问题,但是在资源紧张的时候,这个问题就是最挠人的问题。
再提特权同学发现问题后,如何处置优化提高了这里的利用率(实际上,如果真用EP2C8Q完成这个工程,也不是非得做这个优化的工作,只不过最终的设计是要实现在向下兼容的EP2C5Q上,所以,就诞生了这篇文章的故事……)?很简单,前面其实都已经给了大家暗示,移位寄存器的存储资源利用率不高不是因为本身存储量大(只有1280*8bit=10Kbit,需要3个M4K足够),而是因为生成的taps占用的port过多,前面配置24个taps就占用了6个M4K块,那么如果配置成12个taps,distance值为128会怎样呢?6个taps,distance值为256会怎样呢?答案马上揭晓,如图10所示。其实两者都是占用了3个M4K。这里做的变化就是最终优化成功的玄机。
如图11所示,其实这个工程最终实现到EP2C5Q上是没有问题的,但是如果没有类似移位寄存器例子中的一些优化,存储器资源还是很紧张的。
说到这里,虽然已经洋洋洒洒图文并茂好长一篇文章了。但是,还是很想再提一些和FPGA片上存储资源相关的问题。关于Cyclone/Cyclone II的M4K到Cyclone III的M9K,可能还有一些M512,将来不知道会不会有什么M32K/M128K/M1M云云的概念出来。但是就特权同学对目前器件使用的一点经验上来看,这个MXX的块存储量越大,虽然总的存储量也会越来越大(不能否定它能够满足片内大存储量应用的需求),但是相应的在工程需要的很多小存储应用中对存储块的利用率也会越来越低。因为,对于用户例化的任何一个存储器,如果使用M4K块实现一个8bit的512B/256B/128B/64B甚至哪怕只有1B的应用,其实他们都需要占用1个M4K块。打一个更形象更极端的例子,我的设计中需要两个1*8bit的FIFO(当然实际应用中没有人这么傻,^o^),那么例化完编译后,我的M4K资源别占用了2个,这就是问题。这也是制约着极大多数的应用中,特权同学提到的FPGA片内存储资源利用率无法100%的原因。其实,这也是最近特权同学的另一个项目中搭建的NIOS2平台,如图12所示,各种简单的外设都分别要占用一点片内存储器(没有充分的利用M9K的资源),直接导致整个利用率很低的原因。针对与这种情况,不知道器件厂商是否有所考虑,也许对他们而言,也是处在一种鱼和熊掌不可兼得的矛盾之中。
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)