基于FPGA的微处理器内核设计与实现
时间:06-21
来源:互联网
点击:
2.4 算术逻辑运算单元(ALU)的设计
累加器在CPU发出的指令控制下,对来自ROM与REGS_CTR的数据完成相应的操作,包括算术运算(加减乘除)与逻辑运算(与或非)及BCD码调整。所有操作的结果在一个时钟周期内得出,在clkl上升沿到来后写入REGS_CTR。
2.5 串行模块及定时/计数器的设计
串行模块和定时/计数器的工作模式与传统的MCS-51系列单片机相同。定时/计数器一个时钟周期计数一次,与传统MCS-51单片机一个机器周期计数一次效果等同。在与外界用串行端口通信时机器周期有差别。
3 仿真、综合优化及实现
3.1 仿真
为了保证内核正确地工作,必须对电路做充分的仿真以保证设计的正确性。系统设计完成后用ModelSim Se PLUS 6.0D对电路进行了功能仿真,对组合逻辑模块(如ALU)采用了穷举测试向量的方法予以功能仿真,对于时序模块如CPU,先测试能否正确执行中断及每一条指令,再测试随机指令及随机中断。仿真结果表明,内核能满足设计的要求。ALU的仿真结果如同5所示。
其中rom_data、acc、regs_data为ALU的操作数,in-struction为指令的类别,alu_rslta、alu_rsltb为ALU的操作结果的高、低字节。由图5可见,在输入操作数和进位溢位标志位不变的情况下,不同的指令都能输出相对应的正确结果。ALU操作结果的数据予以锁存,直到下一个指令或数据到来时才改变。在保持指令不变的情况下改变输入数据和进位溢位标志位也能得到正确的结果。
3.2 综合优化
为了尽可能提高时钟频率,必须降低关键路径的延时。由于ALU所有的操作都要在一个周期内完成,因而操作所需的最长时间也是时钟周期的最小值。综合分析后发现操作时间最长的是除法运算,采用通移位相减除法器所需时间为39ns,如果采用并行除法器后则只需23ns,从而显著提高了时钟频率。内核综合后消耗的LUT为4500个。
3.3 实现
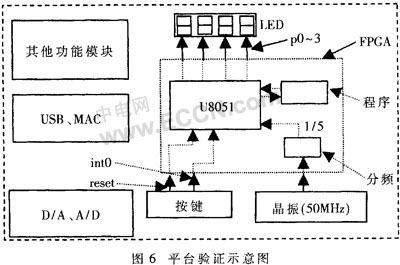
本内核的全部工作都在ISE7.1开发环境下完成。其中,仿真用的是ModelSim Se PLUS 6.0D,综合用的软件是Synplify Pro 8.0。验证采用的平台足CREAT-SOPC1000X试验箱,它的核心芯片即FPGA使用的是Xilinx公司的Virtex-Ⅱxc2v1000-6 fg456,等效为100万门电路,如图6所示。平台上集成了一些常用的功能模块,其中的晶振为50MHz,超过了本内核综合后的最高频率,因而设计了一个5分频模块使时钟为10MHz。内核运行的测试程序和数据以事先机器代码的形式“固化”在一个程序模块内替代ROM,系统可以像ROM一样对其读取数据和程序。P0-3输出观察数据,检验程序是否正确执行。验证结果表明,内核能正确执行加载的程序并稳定运行在10MHz的频率上。
为克服传统MCS-51单片机执行效率偏低的缺点,满足现在的FPGA对嵌入式软核速度较高的要求,重新设计了一个兼容MCS-51指令的嵌入式软核。该软核指令效率提高了12倍,同时增加了实用的功能:硬件看门狗和软件复位。内核通过FPGA验证具有一定的应用价值。
累加器在CPU发出的指令控制下,对来自ROM与REGS_CTR的数据完成相应的操作,包括算术运算(加减乘除)与逻辑运算(与或非)及BCD码调整。所有操作的结果在一个时钟周期内得出,在clkl上升沿到来后写入REGS_CTR。
2.5 串行模块及定时/计数器的设计
串行模块和定时/计数器的工作模式与传统的MCS-51系列单片机相同。定时/计数器一个时钟周期计数一次,与传统MCS-51单片机一个机器周期计数一次效果等同。在与外界用串行端口通信时机器周期有差别。
3 仿真、综合优化及实现
3.1 仿真
为了保证内核正确地工作,必须对电路做充分的仿真以保证设计的正确性。系统设计完成后用ModelSim Se PLUS 6.0D对电路进行了功能仿真,对组合逻辑模块(如ALU)采用了穷举测试向量的方法予以功能仿真,对于时序模块如CPU,先测试能否正确执行中断及每一条指令,再测试随机指令及随机中断。仿真结果表明,内核能满足设计的要求。ALU的仿真结果如同5所示。
|

其中rom_data、acc、regs_data为ALU的操作数,in-struction为指令的类别,alu_rslta、alu_rsltb为ALU的操作结果的高、低字节。由图5可见,在输入操作数和进位溢位标志位不变的情况下,不同的指令都能输出相对应的正确结果。ALU操作结果的数据予以锁存,直到下一个指令或数据到来时才改变。在保持指令不变的情况下改变输入数据和进位溢位标志位也能得到正确的结果。
3.2 综合优化
为了尽可能提高时钟频率,必须降低关键路径的延时。由于ALU所有的操作都要在一个周期内完成,因而操作所需的最长时间也是时钟周期的最小值。综合分析后发现操作时间最长的是除法运算,采用通移位相减除法器所需时间为39ns,如果采用并行除法器后则只需23ns,从而显著提高了时钟频率。内核综合后消耗的LUT为4500个。
3.3 实现
本内核的全部工作都在ISE7.1开发环境下完成。其中,仿真用的是ModelSim Se PLUS 6.0D,综合用的软件是Synplify Pro 8.0。验证采用的平台足CREAT-SOPC1000X试验箱,它的核心芯片即FPGA使用的是Xilinx公司的Virtex-Ⅱxc2v1000-6 fg456,等效为100万门电路,如图6所示。平台上集成了一些常用的功能模块,其中的晶振为50MHz,超过了本内核综合后的最高频率,因而设计了一个5分频模块使时钟为10MHz。内核运行的测试程序和数据以事先机器代码的形式“固化”在一个程序模块内替代ROM,系统可以像ROM一样对其读取数据和程序。P0-3输出观察数据,检验程序是否正确执行。验证结果表明,内核能正确执行加载的程序并稳定运行在10MHz的频率上。
|
为克服传统MCS-51单片机执行效率偏低的缺点,满足现在的FPGA对嵌入式软核速度较高的要求,重新设计了一个兼容MCS-51指令的嵌入式软核。该软核指令效率提高了12倍,同时增加了实用的功能:硬件看门狗和软件复位。内核通过FPGA验证具有一定的应用价值。
FPGA 单片机 VHDL 看门狗 总线 电路 51单片机 仿真 ModelSim Xilinx 嵌入式 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)