基于DSP的G.729语音编解码算法的优化和实现
时间:11-26
来源:互联网
点击:
随着多媒体信息技术和网络技术的飞速发展,信息量快速增长,使信道资源显得越来越宝贵。为了在有限的信道资源下传输尽可能多的信息,语音压缩成为必要手段。ITU组织(国际电信联盟)在l996年制定了G.729协议,即共轭结构码激励线性预测编码算法(CS-ACELP)。其编码速率为8kb/s,可以满足网络通信的要求,具有良好的语音质量,对不同的应用环境有较强的适应性,是一种性能较好的语音压缩国际标准,被广泛应用在个人移动通信、卫星通信等各个领域。
1 G.729编解码算法的原理
语音信号的波形编码力图使重建语音波形保持原始语音信号的波形形状。这类编码器通常将语音信号作为一般的波形信号来处理,它具有适应能力强、语音质量好等优点,但所需用的编码速率高。参数编码通过对语音信号特征参数的提取及编码来降低编码速率,力图使重建语音信号尽可能保持原语音的语意,而重建信号的波形同原语音信号的波形可能会有相当大的差别。二十世纪70年代中期,特别是80年代以来,语音编码技术有了突破性的进展,提出了一些非常有效的处理方法,如混合编码。这种算法克服了原有波形编码器与声码器的弱点,而结合了它们各自的长处,在4kb/s~16kb/s速率上能够得到高质量合成语音,而在本质上也具有波形编码的优点。G.729所描述的CS-ACELP(Conjugate-Structure Al2gebraic-Coder-Excited Linear Prediction)声码器采用的CELP声码器就属于这类编码器。
CELP编码基于合成分析(A-B-S)的搜索过程、感知加权矢量量化(VQ)和线性预测(LP)技术,采用这种编码方案使传输的比特率大大降低。CS-ACELP的思想是由共轭结构码线性预测(CS-CELP)和代数码本激励线性预测(ACELP)的思想整合而来的。在编码端,主要进行有线谱对(LSP)参数的量化、基音分析、固定码本搜索和增益量化四个步骤。编码器首先对输入信号(8kHz采样16bit PCM信号)进行预处理,然后对每帧语音信号进行线性预测,得到LPC系数,并把LPC参数转换成LSP参数,最后对LSP参数进行矢量量化。在接下来的基音分析中,每一帧先搜索到最佳基音时延T的一个候选时延,然后依据候选时延搜索每一帧的最佳基音时延。最后还要对自适应码本增益和固定码本增益进行量化。在解码端,首先由接收到的比特流得到各种参数标志进行解码,得到10ms语音帧编码参数。解码器在每一子帧内,对LSP系数进行内插,并把它们变换成LP滤波器系数后,依次进行激励生成、语音合成和后处理工作。
2 算法优化和DSP应用改进
G.729语音编解码系统要求实时性高,需在有限的时间内对外部输入的信号完成指定处理,即信号处理的速度必须大于等于输入信号更新的速度,因此需要进行算法的优化改进。对C语言编写的代码进行优化,同时使用内联指令,又在C程序中嵌入汇编语句,尽量提高信号处理的速度。
2.1 算法的优化改进
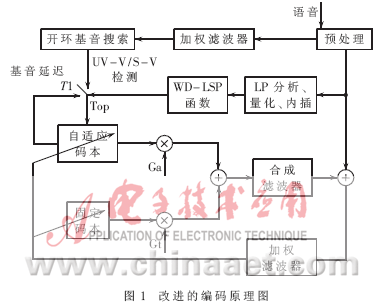
首先在算法上进行改进,如图1所示,采用一种结合WD-LSP(Weighted Delta-LSP)函数并结合次最优部分码本快速搜索的CS-ACELP语音编码算法,同时采用基于声学心理模型的知觉加权滤波器,使语音编码在不降低语音质量的情况下降低计算复杂度。WD-LSP函数主要用于区分UV-V(unvoice-voice)/S-V(silence-voice)的边界。其原理是:如果函数值大于给定的极限值η,则开环基音延迟Top重新估计,否则,开环基音延迟Top用前一帧自适应码本延迟来更新。在第i帧Fi的WD-LSP函数和用于确定开环基音延迟Top的算法如下:

其中LSPi(k)是在第i帧中的k阶LSP系数;wk是加权系数,它用于增强UV-V/S-V边界的WD-LSP函数。为了获取wk,一个包含23 014个UV-V边界和9 519个S-V边界的大型数据库用于估计delta-LSP在UV-V/S-V边界的平方根值(RMS)。因此,WD-LSP用于检测VU-V/S-V边界非常敏感。η是一个设为0.01的极限值。整个计算可节省21%的计算量,经过这种算法前后语音信号如图2所示。

2.2 进行C语言优化
基于G.729标准的声码器最终在定点TMS320C5416上实时实现。在定点TMS320C5416内,浮点数是通过将小数点固定在特定位置来表示的,这是定点TMS320C5416的局限之一。为了区分小数的不同值域,使用了Q-格式。不同的Q-格式在于小数点的位置不同,因此整数域也不同。当两个数相乘时,会产生一个特殊的符号位。如:两个Q4数相乘, 需要附加一个左移的操作以去除这个多余的符号位,乘积应该是一个Q9格式的。如果DSP中的FRST位被置位,这个去除多余符号位的移位操作能够自动完成。对于16位数的乘法运算,应该得到32 位的乘积。但是,由于只需要16位的积,该32位乘积中只有高16位被存储下来,积的低16位被丢弃。为了达到高准确性,在连续的乘法运算过程中(如卷积),应该一直保持32位的计算结果,只对最终的计算结果进行丢弃低16位的截短操作。为了达到更高的准确性,在这一操作过程中会使用到一种双重精度格式, 这种格式仅仅出现在使用单精度不够,而又不必要使用32位精度的时候。两个32位数相乘,只需要32位的乘积,而不是64位,不过注意到TMS320C5416是16位的,所以在双重精度格式中,32位整数分为高位字和低位字。高、低位字中都含有符号位,以进行快乘运算。其格式如下:
L_32=hi_word<<16+lo_word<<1
Hi_word=L_32>>16
Lo_word=L_32-hi_word>>1
当累加器中的数值超过一定范围时将会产生溢出。在G.729算法标准中, 累加器的值被限定在80000000~7FFFFFFF之内——即最小负数和最大正数。不过在TMS320C5416中,如果将PMST寄存器中的OVM置位,则溢出会得到自动处理。
1 G.729编解码算法的原理
语音信号的波形编码力图使重建语音波形保持原始语音信号的波形形状。这类编码器通常将语音信号作为一般的波形信号来处理,它具有适应能力强、语音质量好等优点,但所需用的编码速率高。参数编码通过对语音信号特征参数的提取及编码来降低编码速率,力图使重建语音信号尽可能保持原语音的语意,而重建信号的波形同原语音信号的波形可能会有相当大的差别。二十世纪70年代中期,特别是80年代以来,语音编码技术有了突破性的进展,提出了一些非常有效的处理方法,如混合编码。这种算法克服了原有波形编码器与声码器的弱点,而结合了它们各自的长处,在4kb/s~16kb/s速率上能够得到高质量合成语音,而在本质上也具有波形编码的优点。G.729所描述的CS-ACELP(Conjugate-Structure Al2gebraic-Coder-Excited Linear Prediction)声码器采用的CELP声码器就属于这类编码器。
CELP编码基于合成分析(A-B-S)的搜索过程、感知加权矢量量化(VQ)和线性预测(LP)技术,采用这种编码方案使传输的比特率大大降低。CS-ACELP的思想是由共轭结构码线性预测(CS-CELP)和代数码本激励线性预测(ACELP)的思想整合而来的。在编码端,主要进行有线谱对(LSP)参数的量化、基音分析、固定码本搜索和增益量化四个步骤。编码器首先对输入信号(8kHz采样16bit PCM信号)进行预处理,然后对每帧语音信号进行线性预测,得到LPC系数,并把LPC参数转换成LSP参数,最后对LSP参数进行矢量量化。在接下来的基音分析中,每一帧先搜索到最佳基音时延T的一个候选时延,然后依据候选时延搜索每一帧的最佳基音时延。最后还要对自适应码本增益和固定码本增益进行量化。在解码端,首先由接收到的比特流得到各种参数标志进行解码,得到10ms语音帧编码参数。解码器在每一子帧内,对LSP系数进行内插,并把它们变换成LP滤波器系数后,依次进行激励生成、语音合成和后处理工作。
2 算法优化和DSP应用改进
G.729语音编解码系统要求实时性高,需在有限的时间内对外部输入的信号完成指定处理,即信号处理的速度必须大于等于输入信号更新的速度,因此需要进行算法的优化改进。对C语言编写的代码进行优化,同时使用内联指令,又在C程序中嵌入汇编语句,尽量提高信号处理的速度。
2.1 算法的优化改进
首先在算法上进行改进,如图1所示,采用一种结合WD-LSP(Weighted Delta-LSP)函数并结合次最优部分码本快速搜索的CS-ACELP语音编码算法,同时采用基于声学心理模型的知觉加权滤波器,使语音编码在不降低语音质量的情况下降低计算复杂度。WD-LSP函数主要用于区分UV-V(unvoice-voice)/S-V(silence-voice)的边界。其原理是:如果函数值大于给定的极限值η,则开环基音延迟Top重新估计,否则,开环基音延迟Top用前一帧自适应码本延迟来更新。在第i帧Fi的WD-LSP函数和用于确定开环基音延迟Top的算法如下:
其中LSPi(k)是在第i帧中的k阶LSP系数;wk是加权系数,它用于增强UV-V/S-V边界的WD-LSP函数。为了获取wk,一个包含23 014个UV-V边界和9 519个S-V边界的大型数据库用于估计delta-LSP在UV-V/S-V边界的平方根值(RMS)。因此,WD-LSP用于检测VU-V/S-V边界非常敏感。η是一个设为0.01的极限值。整个计算可节省21%的计算量,经过这种算法前后语音信号如图2所示。
2.2 进行C语言优化
基于G.729标准的声码器最终在定点TMS320C5416上实时实现。在定点TMS320C5416内,浮点数是通过将小数点固定在特定位置来表示的,这是定点TMS320C5416的局限之一。为了区分小数的不同值域,使用了Q-格式。不同的Q-格式在于小数点的位置不同,因此整数域也不同。当两个数相乘时,会产生一个特殊的符号位。如:两个Q4数相乘, 需要附加一个左移的操作以去除这个多余的符号位,乘积应该是一个Q9格式的。如果DSP中的FRST位被置位,这个去除多余符号位的移位操作能够自动完成。对于16位数的乘法运算,应该得到32 位的乘积。但是,由于只需要16位的积,该32位乘积中只有高16位被存储下来,积的低16位被丢弃。为了达到高准确性,在连续的乘法运算过程中(如卷积),应该一直保持32位的计算结果,只对最终的计算结果进行丢弃低16位的截短操作。为了达到更高的准确性,在这一操作过程中会使用到一种双重精度格式, 这种格式仅仅出现在使用单精度不够,而又不必要使用32位精度的时候。两个32位数相乘,只需要32位的乘积,而不是64位,不过注意到TMS320C5416是16位的,所以在双重精度格式中,32位整数分为高位字和低位字。高、低位字中都含有符号位,以进行快乘运算。其格式如下:
L_32=hi_word<<16+lo_word<<1
Hi_word=L_32>>16
Lo_word=L_32-hi_word>>1
当累加器中的数值超过一定范围时将会产生溢出。在G.729算法标准中, 累加器的值被限定在80000000~7FFFFFFF之内——即最小负数和最大正数。不过在TMS320C5416中,如果将PMST寄存器中的OVM置位,则溢出会得到自动处理。
编码器 Linear 解码器 滤波器 DSP C语言 总线 仿真 相关文章:
- 基于红外超声光电编码器的室内移动小车定位系统(06-30)
- CRC算法及工作原理(10-10)
- 基于uC/OS-II的低速率语音编码器系统设计(06-06)
- 基于ARM的旋转编码器采集模块设计(02-27)
- ARM体系结构的发展(05-08)
- 应用处理器连接汽车和消费电子两大领域(02-26)