深入浅出学人工智能神经网络:GAN原理与应用入门介绍
生成对抗网络(GAN)是一类在无监督学习中使用的神经网络,其有助于解决按文本生成图像、提高图片分辨率、药物匹配、检索特定模式的图片等任务。Statsbot 小组邀请数据科学家 Anton Karazeev 通过日常生活实例深入浅出地介绍 GAN 原理及其应用。

生成对抗网络由 Ian Goodfellow 于 2014 年提出。GAN 不是神经网络应用在无监督学习中的唯一途径,还有玻尔兹曼机(Geoffrey Hinton 和 Terry Sejnowski,1985)和自动解码器(Dana H. Ballard,1987)。三者皆致力于通过学习恒等函数 f(x)= x 从数据中提取特征,且都依赖马尔可夫链来训练或生成样本。
GAN 设计之初衷就是避免使用马尔可夫链,因为后者的计算成本很高。相对于玻尔兹曼机的另一个优点是 GAN 的限制要少得多(只有几个概率分布适用于马尔可夫链抽样)。
在本文中,我们将讲述 GAN 的基本原理及最流行的现实应用。
GAN 原理
让我们用一个比喻解释 GAN 的原理吧。

假设你想买块好表。但是从未买过表的你很可能难辨真假;买表的经验可以免被奸商欺骗。当你开始将大多数手表标记为假表(当然是被骗之后),卖家将开始「生产」更逼真的山寨表。这个例子形象地解释了 GAN 的基本原理:判别器网络(手表买家)和生成器网络(生产假表的卖家)。
两个网络相互博弈。GAN 允许生成逼真的物体(例如图像)。生成器出于压力被迫生成看似真实的样本,判别器学习分辨生成样本和真实样本。

判别算法和生成算法有何不同?简单地说:判别算法学习类之间的边界(如判别器做的那样),而生成算法学习类的分布(如生成器做的那样)。
如果你准备深入了解 GAN
想要学习生成器的分布,应该定义数据 x 的参数 p_g,以及输入噪声变量 p_z(z)的分布。然后 G(z,θ_g)将 z 从潜在空间 Z 映射到数据空间,D(x,θ_d)输出单个标量——一个 x 来自真实数据而不是 p_g 的概率。
训练判别器以最大化正确标注实际数据和生成样本的概率。训练生成器用于最小化 log(1-D(G(z)))。换句话说,尽量减少判别器得出正确答案的概率。
可以将这样的训练任务看作具有值函数 V(G,D)的极大极小博弈:

换句话说,生成器努力生成判别器难以辨认的图像,判别器也愈加聪明,以免被生成器欺骗。
「对抗训练是继切片面包之后最酷的事情。」- Yann LeCun
当判别器不能区分 p_g 和 p_data,即 D(x,θ_d)= 1/2 时,训练过程停止。达成生成器与判别器之间判定误差的平衡。
历史档案图像检索
一个有趣的 GAN 应用实例是在「Prize Papers」中检索相似标记,Prize Papers 是海洋史上最具价值的档案之一。对抗网络使得处理这些具有历史意义的文件更加容易,这些文件还包括海上扣留船只是否合法的信息。

每个查询到的记录都包含商家标记的样例——商家属性的唯一标识,类似于象形文字的草图样符号。
我们应该获得每个标记的特征表示,但是应用常规机器学习和深度学习方法(包括卷积神经网络)存在一些问题:
-
它们需要大量标注图像;
-
商标没有标注;
-
标记无法从数据集分割出去。
这种新方法显示了如何使用 GAN 从商标的图像中提取和学习特征。在学习每个标记的表征之后,就可以在扫描文档上按图形搜索。
将文本翻译成图像
其他研究人员表明,使用自然语言的描述属性生成相应的图像是可行的。文本转换成图像的方法可以说明生成模型模拟真实数据样本的性能。
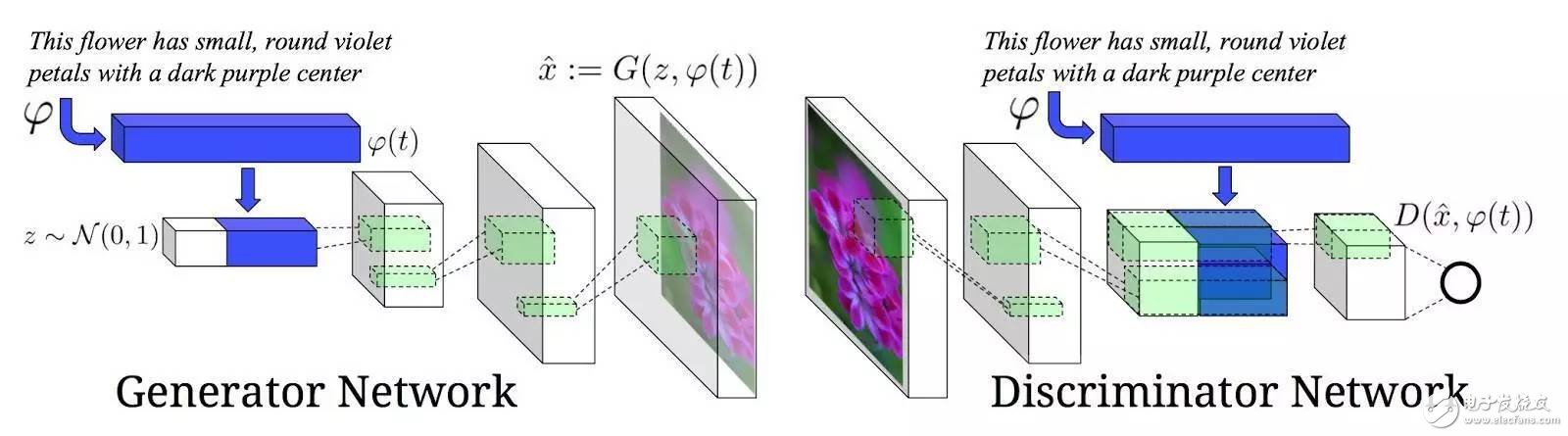
图片生成的主要问题在于图像分布是多模态的。例如,有太多的例子完美契合文本描述的内容。GAN 有助于解决这一问题。
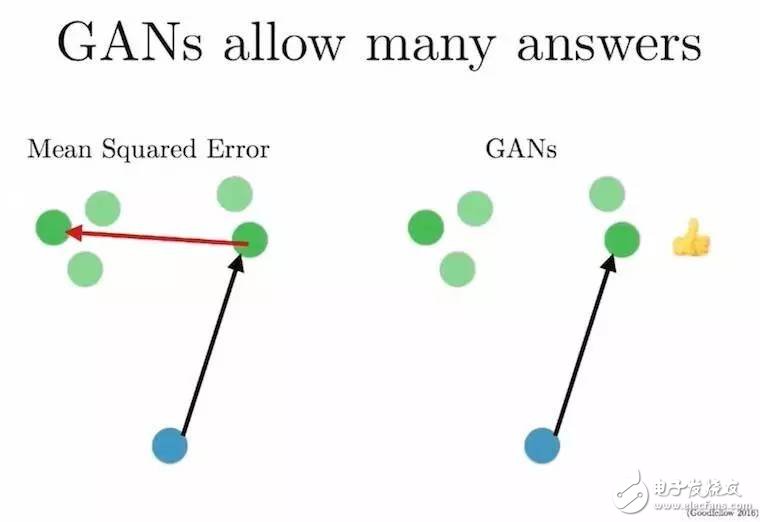
我们来考虑以下任务:将蓝色输入点映射到绿色输出点(绿点可能是蓝点的输出)。这个红色箭头表示预测的误差,也意味着经过一段时间后,蓝点将被映射到绿点的平均值——这一精确映射将会模糊我们试图预测的图像。
GAN 不直接使用输入和输出对。相反,它们学习如何给输入和输出配对。
下面是从文本描述中生成图像的示
- 用ARM和FPGA搭建神经网络处理器通信方案(07-19)
- 机器学习算法盘点:人工神经网络、深度学习(07-02)
- 基于模糊神经网络的机器人位置控制系统设计(08-18)
- 基于模糊行为和神经网络的机器人视觉伺服控制方案(08-19)
- 分析机器人避障技术:从传感器到算法原理(10-25)
- 人工智能全新突破:神经网络可自主识别图片中的对象(11-09)