从技术到产品,苹果Siri深度学习语音合成技术揭秘
,即通过自动语音识别将输入音素序列和从语音信号抽取出的声学特征相匹配。这个分割的过程根据语音数据量产生 1~2 百万的半音素单元。
为了引导单元的选择过程,我们使用 MDN 架构训练了统一的目标和拼接模型。深度 MDN 的输入由带有一些额外 continuously-valued 特征的二值组成。该特征表示一系列语句中的多元音素(quinphones)信息(2 个过去的、现在的和对后的音素),音节、短语和句子级的信息,还有额外的突出和重读特征。
输出向量包含以下声学特征:梅尔倒频谱系数(MFCC)、delta-MFCC、基频(fundamental frequency - f0)和 delta-f0(包含每个单元的开始和结束的值),以及每个单元的音长时间。因为我们使用 MDN 作为声学模型,所以输出同样包含每一个特征的方差,并作为自动上下文依赖权重。
此外,语音区的基本频率整体上高度依赖发音,为了创建语调自然生动的合成语音,我们部署了一个循环深度 MDN 模型以建模 f0 特征。
训练的深度 MDN 的架构包括 3 个隐藏层,每一层有 512 个修正线性单元(ReLU)作为非线性激活函数。输入特征和输出特征在训练前接受均值和方差归一化处理。最终的单元选择声音包括单元数据库(含有每个单元的特征和语音数据)和训练的深度 MDN 模型。新的 TTS 系统的质量优于之前的 Siri 系统。在一个 AB 成对主观听力测试中,被试者明确地选择基于深度 MDN 的新声音,而不是之前的声音。结果如图 6 所示。质量的改善与 TTS 系统中的多个改进有关,如基于深度 MDN 的后端使得单元选择和拼接变得更好,采样率更高(22 kHz vs 48 kHz),音频压缩更好。
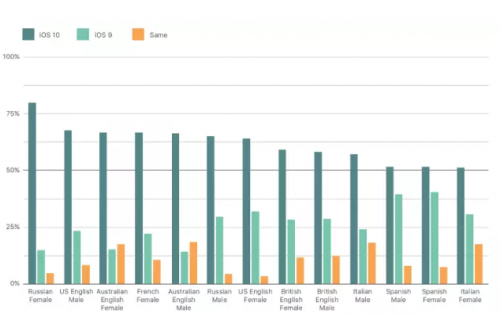
图 6:AB 成对主观听力测试的结果。新声音要显著地优于以前版本的声音。
因为 TTS 系统需要在移动设备上运行,我们在速度、内存使用和占用上使用快速预选机制、单元剪枝和计算并行化优化了它的运行时(Runtime)性能。
新声音
对于 IOS 11,我们选择了一位新的女性声优来提升 Siri 声音的自然度、个性度及表达能力。在选出最佳声优之前,我们评估了成百上千的后选人。在选定之后,我们录制了 20 多小时的语音并使用新的深度学习 TTS 技术构建了一个新的 TTS 声音。最后,新的美式英语 Siri 听起来要比以前好。下表包含一些语音的对比(微信无法展示,请查看原文)。
更多技术详情请查看论文:Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System[9]
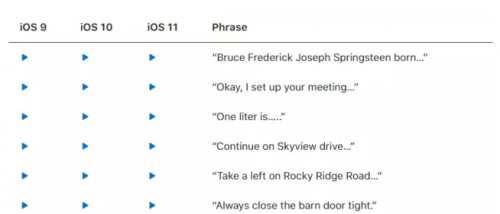
表 1. iOS 11 中的 Siri 新声音示例
References
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[3] S. King, Measuring a decade of progress in Text-to-Speech, Loquens, vol. 1, no. 1, 2006.
[4] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. W. Senior, K. Kavukcuoglu. Wavenet: A generative model for raw audio, arXiv preprint arXiv:1609.03499, 2016.
[5] Y. Qian, F. K. Soong, Z. J. Yan. A Unified Trajectory Tiling Approach to High Quality Speech Rendering, IEEE Transactions on Audio, Speech, and Language Processingv, Vol. 21, no. 2, pp. 280-290, Feb. 2013.
[6] X. Gonzalvo, S. Tazari, C. Chan, M. Becker, A. Gutkin, H. Silen, Recent Advances in Google Real-time HMM-driven Unit Selection Synthesizer, Interspeech, 2016.
[7] C. Bishop. Mixture density networks, Tech. Rep. NCRG/94/004, Neural Computing Research Group. Aston University, 1994.
[8] H. Zen, A. Senior. Deep mixture density networks for acoustic modeling in statistical parametric speech synthesis, ICASSP, 2014.
[9] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
- 调查显示苹果为最具影响力消费品牌(03-02)
- 手机巨头与苹果iPhone差距何在?在软件而非硬件(05-21)
- 苹果发布会iPhone 3Gs 新功能简单整理(05-09)
- 苹果3G版iPad 2通过3C产品认证 (04-19)
- 明年平板电脑销量将增63% 苹果仍将领先(04-18)
- 苹果打造“浸入式”智能眼镜 (06-09)