从技术到产品,苹果Siri深度学习语音合成技术揭秘
Siri 是一个使用语音合成技术与人类进行交流的个人助手。从 iOS 10 开始,苹果已经在 Siri 的语音中用到了深度学习,iOS 11 中的 Siri 依然延续这一技术。使用深度学习使得 Siri 的语音变的更自然、流畅,更人性化。机器之心对苹果期刊的该技术博客进行了介绍,更详细的技术请查看原文。
介绍
语音合成,也就是人类声音的人工产品,被广泛应用于从助手到游戏、娱乐等各种领域。最近,配合语音识别,语音合成已经成为了 Siri 这样的语音助手不可或缺的一部分。
如今,业内主要使用两种语音合成技术:单元选择 [1] 和参数合成 [2]。单元选择语音合成技术在拥有足够高质量录音时能够合成最高质量的语音,也因此成为商业产品中最常用的语音合成技术。另外,参数合成能够提供高度可理解的、流畅的语音,但整体质量略低。因此,在语料库较小、低占用的情况下,通常使用参数合成技术。现代的单元选择系统结合这两种技术的优势,因此被称为混合系统。混合单元选择方法类似于传统的单元选择技术,但其中使用了参数合成技术来预测选择的单元。
近期,深度学习对语音领域冲击巨大,极大的超越了传统的技术,例如隐马尔可夫模型。参数合成技术也从深度学习技术中有所收益。深度学习也使得一种全新的语音合成技术成为了可能,也就是直接音波建模技术(例如 WaveNet)。该技术极有潜力,既能提供单元选择技术的高质量,又能提供参数选择技术的灵活性。然而,这种技术计算成本极高,对产品而言还不成熟。为了让所有平台的 Siri 语音提供最佳质量,苹果迈出了这一步,在设备中的混合单元选择系统上使用了深度学习。
苹果深度语音合成技术工作原理
为个人助手建立高质量的文本转语音(TTS)系统并非简单的任务。首先,第一个阶段是找到专业的播音人才,她/他的声音既要悦耳、易于理解,又要符合 Siri 的个性。为了覆盖各种人类语音,我们首先在录音棚中记录了 10-20 小时的语音。录制的脚本从音频簿到导航指导,从提示答案到笑话,不一而足。通常来说,这种天然的语音不能像录制的那样使用,因为不可能录制助手会说的每一句话。因此,单元选择 TTS 系统把记录的语音切片成基础元件,比如半音素,然后根据输入文本把它们重新结合,创造全新的语音。在实践中,选择合适的音素并组合起来并非易事,因为每个音素的声学特征由相邻的音素、语音的韵律所决定,这通常使得语音单元之间不相容。图 1 展示了如何使用被分割为半音素的数据库合成语音。
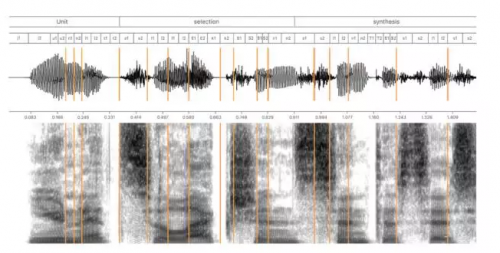
图 1:展示了使用半音素进行单元选择语音合成。合成的发音是「Unit selection synthesis」,图的顶部是使用半音素的标音法。相应的合成波形与光谱图在图下部分。竖线划分的语音段是来自数据集的持续语音段,数据集可能包含一个或多个半音素。
单元选择 TTS 技术的基本难题是找到一系列单元(例如,半音素),既要满足输入文本、预测目标音韵,又要能够在没有明显错误的情况下组合在一起。传统方式上,该流程包含两部分:前端和后端(见图 2),尽管现代系统中其界限可能会很模糊。前端的目的是基于原始文本输入提供语音转录和音韵信息。这包括将包含数字、缩写等在内的原始文本规范化写成单词,并向每个单词分配语音转录,解析来自文本的句法、音节、单词、重音、分句。要注意,前端高度依赖语言。
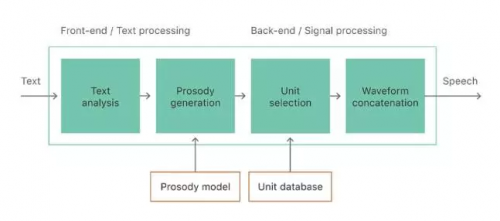
图 2:文本转语音合成流程。
使用由文本分析模块创建的符号语言学表征,音韵生成模块预测音调、音长等声学特征的值。这些值被用于选择合适的单元。单元选择的任务极其复杂,所以现代的合成器使用机器学习方法学习文本与语音之间的一致性,然后根据未知文本的特征值预测其语音特征值。这一模块必须要在合成器的训练阶段使用大量的文本和语音数据进行学习。音韵模型输入的是数值语言学特征,例如音素特性、音素语境、音节、词、短语级别的位置特征转换为适当的数值形式。音韵模型的输出由语音的数值声学特征组成,例如频谱、基频、音素时长。在合成阶段,训练的统计模型用于把输入文本特征映射到语音特征,然后用来指导单元选择后端流程,该流程中声调与音长的合适度极其重要。
与前端不同,后端通常是语言独立的。它包括单元选择和波形拼接部分。当系统接受训练时,使用强制对齐将录制的语音和脚本对齐(使用语音识别声学模型)以使录制的语音数据被分割成单独的语音段。然后使用语音段创建单元数据库。使用重要的信息,如每个单元的语言环境(linguistic context)和声学特征,将该数据库进一步增强。我们将该数据叫作单
- 调查显示苹果为最具影响力消费品牌(03-02)
- 手机巨头与苹果iPhone差距何在?在软件而非硬件(05-21)
- 苹果发布会iPhone 3Gs 新功能简单整理(05-09)
- 苹果3G版iPad 2通过3C产品认证 (04-19)
- 明年平板电脑销量将增63% 苹果仍将领先(04-18)
- 苹果打造“浸入式”智能眼镜 (06-09)