从技术到产品,苹果Siri深度学习语音合成技术揭秘
元索引(unit index)。使用构建好的单元数据库和指导选择过程的预测音韵特征,即可在语音空间内执行 Viterbi 搜索,以找到单元合成的最佳路径(见图 3)。
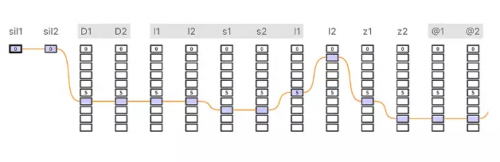
图 3. 使用 Viterbi 搜索在栅格中寻找单元合成最佳路径。图上方是合成的目标半音素,下面的每个框对应一个单独的单元。Viterbi 搜索找到的最佳路径为连接被选中单元的线。
该选择基于两个标准:(1)单元必须遵循目标音韵;(2)在任何可能的情况下,单元应该在单元边界不产生听觉故障的情况下完成拼接。这两个标准分别叫作目标成本和拼接成本。目标成本是已预测的目标声学特征和从每个单元抽取出的声学特征(存储在单元索引中)的区别,而拼接成本是后项单元之间的声学区别(见图 4)。总成本按照如下公式计算:
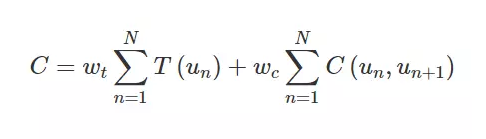
其中 u_n 代表第 n 个单元,N 代表单元的数量,w_t 和 w_c 分别代表目标成本和拼接成本的权重。确定单元的最优顺序之后,每个单元波形被拼接,以创建连续的合成语音。
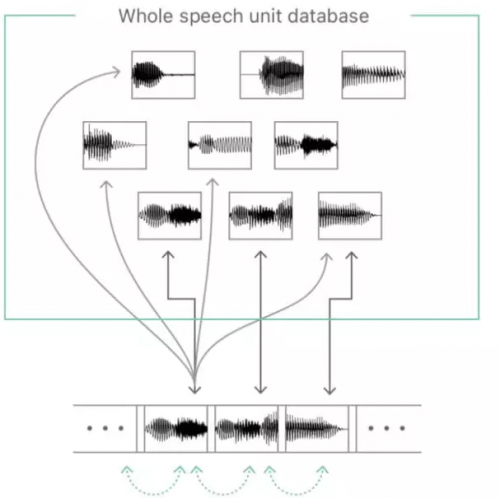

图 4. 基于目标成本和拼接成本的单元选择方法。
Siri 新声音背后的技术
因为隐马尔可夫模型对声学参数的分布直接建模,所以该模型通常用于对目标预测 [5][6] 的统计建模,因此我们可以利用如 KL 散度那样的函数非常简单地计算目标成本。然而,基于深度学习的方法通常在参数化的语音合成中更加出色,因此我们也希望深度学习的优势能转换到混合单元选择合成(hybrid unit selection synthesis)中。
Siri 的 TTS 系统的目标是训练一个基于深度学习的统一模型,该模型能自动并准确地预测数据库中单元的目标成本和拼接成本(concatenation costs)。因此该方法不使用隐马尔可夫模型,而是使用深度混合密度模型(deep mixture density network /MDN)[7][8] 来预测特征值的分布。MDS 结合了常规的深度神经网络和高斯混合模型(GMM)。
常规 DNN 是一种在输入层和输出层之间有多个隐藏层的人工神经网络。因此这样的深度神经网络才能对输入特征与输出特征之间的复杂和非线性关系建模。通常深度神经网络使用反向传播算法通过误差的传播而更新整个 DNN 的权重。相比之下,GMM 在使用一系列高斯分布给定输入数据的情况下,再对输出数据的分布进行建模。GMM 通常使用期望最大化(expectation maximization /EM)算法执行训练。MDN 结合了 DNN 和 GMM 模型的优点,即通过 DNN 对输入和输出之间的复杂关系进行建模,但是却提高概率分布作为输出(如下图 5)。
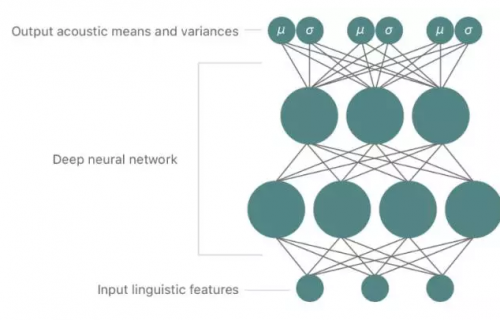
图 5:用于对声音特征的均值和方差建模的深度混合密度网络,输出的声学均值和方差可用于引导单元选择合成
对于 Siri 来说,我们使用了基于 MDN 统一的目标和拼接模型,该模型能预测语音目标特征(频谱、音高和音长)和拼接成本分布,并引导单元的搜索。因为 MDN 的分布是一种高斯概率表分布形式,所以我们能使用似然度函数作为目标和拼接成本的损失函数:
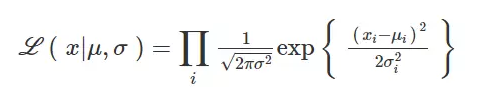
其中 x_i 是第 i 个目标特征,μ_i 为预测均值,而 (σ_i)^2 为预测方差。在实际的成本计算中,使用负对数似然函数和移除常数项将变得更加方便,经过以上处理将简化为以下简单的损失函数:
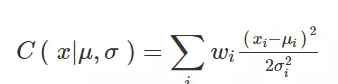
其中 w_i 为特征权重。
当我们考虑自然语言时,这种方法的优势将变得非常明显。像元音那样,有时候语音特征(如话音素)相当稳定,演变也非常缓慢。而有时候又如有声语音和无声语音的转换那样变化非常迅速。考虑到这种变化性,模型需要能够根据这种变化性对参数作出调整,深度 MDN 的做法是在模型中使用嵌入方差(variances embedded)。因为预测的方差是依赖于上下文的(context-dependent),所以我们将它们视为成本的自动上下文依赖权重。这对提升合成质量是极为重要的,因为我们希望在当前上下文下计算目标成本和拼接成本:
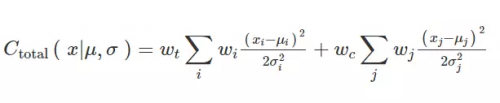
其中 w_t 和 w_c 分别为目标和拼接成本权重。在最后的公式中,目标成本旨在确保合成语音(语调和音长)中再现音韵。而拼接成本确保了流畅的音韵和平滑的拼接。
在使用深度 MDN 对单元的总成本进行评分后,我们执行了一种传统的维特比搜索(Viterbi search)以寻找单元的最佳路径。然后,我们使用波形相似重叠相加算法(waveform similarity overlap-add/WSOLA)找出最佳拼接时刻,因此生成平滑且连续合成语音。
结论
我们为 Siri 的新声音搭建了一整套基于深度 MDN 的混合单元选择 TTS 系统。训练语音数据包括在 48KHz 的频率下采样的最少 15 小时高质量语音。我们采取了强制对齐的方式将这些语音数据分割为半音素(half-phones)
- 调查显示苹果为最具影响力消费品牌(03-02)
- 手机巨头与苹果iPhone差距何在?在软件而非硬件(05-21)
- 苹果发布会iPhone 3Gs 新功能简单整理(05-09)
- 苹果3G版iPad 2通过3C产品认证 (04-19)
- 明年平板电脑销量将增63% 苹果仍将领先(04-18)
- 苹果打造“浸入式”智能眼镜 (06-09)