IBM新型深度学习系统解析,当真能实现最优性能?
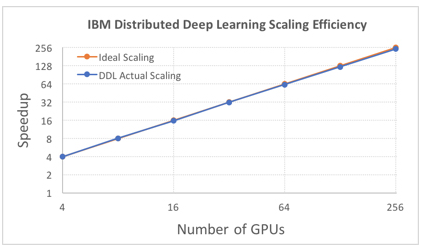
通过 256 块 GPU 扩展 IBM DDL 性能
为了从 ImageNet-22K 数据集中的 7.5M 图像上训练出更大的 ResNet-101 模型(每个图像批量大小为 5120),我们实现了 88% 的扩展效率。
我们也打破了记录,取得了 50 分钟的最快绝对训练时间,而 Facebook 之前的记录是 60 分钟。通过把 DDL 用到 256 块 GPU 上来扩展 Torch,我们借助 ImageNet-1K 模型训练 ResNet-50 模型。Facebook 使用 Caffe2 训练了一个相似的模型。
对于开发者和数据科学家来说,IBM DDL 软件展示的 API 每一个深度学习框架皆可使用,并可扩展到多个服务器。PowerAI 企业深度学习软件版本 4 中现已提供技术预览,使得这一集群扩展功能可用于任何使用深度学习训练 AI 模型的组织。我们期望,通过 DDL 在 AI 社区中的普及,我们将看到更多更高精度的运行,因为其他人在 AI 建模训练中利用了集群的力量。
论文:PowerAI DDL

论文链接:https://arxiv.org/abs/1708.02188
随着深度神经网络变得越来越复杂,输入数据集的规模变得越来越大,我们可能需要数天或数周的时间来训练一个深度神经网络以获得理想的效果。因此,大规模分布式深度学习就显得十分重要了,因为它有潜力将训练时间从数周减少到数小时。在本论文中,我们提出了一种软硬件联合优化的分布式深度学习系统,该系统一直到数百块 GPU 都能实现性能的近线性缩放。该系统的核心算法是多环通信模式(multi-ring communication pattern),它能提供在延迟和带宽上的优良权衡,并能适应多种系统配置。该通信算法以函数库的形式实现,因此它十分易于使用。该软件库已经集成到 TensorFlow、Caffe 和 Torch 中。我们在 Imagenet 22K 上使用 IBM Power8 S822LC 服务器(256 GPU)训练 Resnet-101 网络,最终在 7 小时内验证精度达到了 33.8%。相比之下,微软的 ADAM 和谷歌的 DistBelief 在 Imagenet 22K 数据集中的验证精度还不到 30%。相对于 Facebook AI Research 最近使用 256 块 GPU 训练 Imagenet 的论文,我们使用了不同的通信算法,并且结合了软硬件系统以为 Resnet-50 提供更低的通信成本。PowerAI DDL 能够令 Torch 训练 50 层残差网络,完成 90 个 epoch 而实现 1000 类别的识别任务,该训练过程使用 64 IBM Power8 S822LC 服务器(256 GPU)只需要 50 分钟。
- 全球IC代工版图生变 代工版图的基因分析(03-05)
- IBM芯片业务:GlobalFoundries愿买 美国愿卖么?(08-03)
- 采用铜锌锡研制光伏电池 IBM打破世界纪录(08-22)
- 自毁芯片可避免战场情资外泄(02-07)
- 传IBM欲出售芯片业务 将为20年来最大战略调整(02-10)
- Semico研究认为2010年全球IC业将强劲增长(09-26)