全面解读AMD Zen构架,风光无两背后到底靠的啥优势?
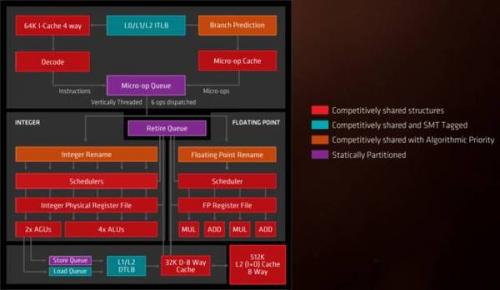
更高速的前端
支撑那些指令单元的是指令解码器和故障处理器。AMD在这些方面同样较推土机做出了长足的改进。就像x86处理器常做的那样,Zen先把x86指令拆解至微指令(μop)然后再安排与执行。在推土机里,重复指令(比如循环)必须被重复地读取和解码。Zen添加了一个能存储2000 μop的微指令缓存,如此,循环中的重复指令就可以跳过解码部分。英特尔在2011年初发布的Sandy Bridge架构中首次提出了同等的数据结构。
这个架构还结合了高效的分支预测器。在处理器确切知道某个分支完成后应该执行哪个指令集之前,分支预测器会进行预先猜测。如果分支预测器预测正确,处理器的管线就可以满负荷工作;如果错误,那么就得清空管线,浪费一小部分工作量。
然而Zen的分支预测器更加机智--它大部分时候都能猜对--而且成本更低--猜错时浪费的工作量被降低了三个时钟周期。AMD现在把分支预测器称作神经网络,因为它的运作基于感知机。感知机的原理就是将一组不同权重的输入值相加,如果和大于零,感知机输出值为1,否则输出值为0.
感知机在分支预测器上起到的作用很有意思,因为它会追踪大量的输入状态然后判断某一分支是否已被占用,所以就算是长循环也很适用。推土机可能也用到了感知机,但一直到Zen的出现AMD才恍然大悟这其实是个神经网络--所以他们开始设想人工智能和施瓦辛格的愿景--让这事儿听起来无比先进。
支撑这一切的是一个更大更强的缓存系统。一级缓存是回写式缓存(而不是推土机的透写式),所以速度更快,存储的传输负载更小。一级和二级缓存都可以带来两倍于推土机的带宽,而三级缓存可以带来五倍,但也更加复杂。CCX内的每个核都有2MB的三级缓存 ,所以每CCX共有8MB,整个处理器共16MB。缓存是共享的,但读取速度不尽相同。离缓存最近的核自然读取速度最快,另外三个会稍慢一些。
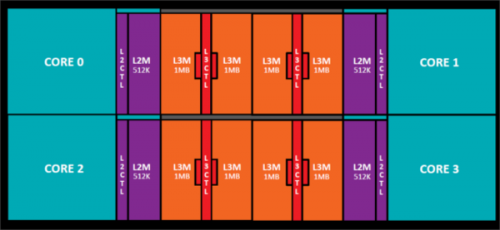
AMD把CCX之间互相沟通用到的技术叫做Infinity Fabric。AMD对此做出的描述不甚清晰,但基本原理就是它是CCX之间一个原本可用在CCX内的高速缓存一致性的接口和总线--电源管理微控制器、安全微控制器、扩展插口标准控制器和存储控制器都与它相接。它甚至可以被用在母板插口之间。
至少在多插口的情况中,AMD把Infinity Fabric称为"改良版的相关性超传输(Coherent HyperTransport),"但有时候AMD又说这不是基于超传输。
比上面这些都更加重要的是,Zen支持同时多线程(SMT)。几乎核内所有资源都可被"竞争性共享",也就是说在没有第二个线程的时候,第一个线程通常可以占用全部的运行资源。指令发送遵循循环制,所有周期轮流在轮流的线程上运行。
SMT带来的收益因情况而异。Cinebench显示启用SMT带来了良好的提升,跑分高出40%多。然而这大大取决于工作量,多线程Geekbench启用SMT后只提高了不到10%。虽然一般来说SMT是绝对赢家--拉高了多线程程序的速度又不损失单线程的性能--但我们也注意到,游戏杀手47(Hitman)因为启用SMT流失了10%的帧速率。
除了运行资源分配大不相同外,总体规律就是Zen上运行的所有工作都还是要比基于单个周期的英特尔设计慢一些。(我们估计落后于Broadwell 5%,落后于Skylake 15%。)但Zen的更高时钟速度加上可靠的同时多线程设计意味着它可以比肩Broadwell-E。比如在Cinebench R15中,1800X和6900X在单线程测试中持平,在多线程测试中比英特尔芯片高出6%。在单线程Geekbench 4中,AMD处理器依然与英特尔持平,虽然多线程上落后英特尔20%。这是在不同测试中由不同混合指令集和不同带宽依赖度带来的反馈。
据此,AMD达成了它的IPC指标,水平与英特尔耗时两年半的芯片设计已经相当靠近。多亏了时钟速度与核数,这意味着Zen在各种不同运行量量级上都能够与英特尔势均力敌。
高效的引擎
相比于挖掘机,Zen的能耗也有大幅降低。
如果说把IPC拉高了52%已经非常惊艳的话,那么降低能耗这方面更是有过之而无不及:在多线程Cinebench上,AMD声称效能功耗比提高了269%。同功耗下,Zen的跑分是挖掘机的3.7倍。
能源效率的提高来自于很多方面。一项重大的突破出自AMD自己之手:效能功耗比自切换到GlobalFoundries的14纳米鳍式场效应晶体管工艺(FinFET)后上升了70%(就算GlobalFoundries跟不上的话,AMD也已经证实了三星14纳米工艺的可用性);甚至面向移动端的挖掘机处理器目前也是基于古董级的28纳米工艺。此外其他方面的提高要归功于AMD的工程师。
129%的提高来自更优的新架构设计。不仅运行速度更快,而且更加节能。微指令缓存不仅减轻了读取和解码指令的压力,而且降低了能耗。从微指令缓存直接读取比从一级指令缓存读取再运行解码器所消耗的资源要少得多。类似地,改良版的分支预测器意味着处理器在预测错误后在错误分支上浪费的时间更少,浪费的能源也就更少。
整数核还带有提高性能与效率的特性。最常见的x86指令就是移动指令,把数据从存储器搬到寄存器上,从这个寄存器搬到那个寄存器上,从寄存器搬到存储器上。那些寄存器之间的数据移动已经被整数核取消了,取而代之的是寄存器重命名,这个技巧曾被首次用在推土机上。
x86还包括操纵堆栈的指令;这些指令会一边从存储器读写数据一边在特定寄存器上加减数据(堆栈指针)。推土机采用了一些堆栈的特殊处理,用以降低堆栈相关指令之间的依赖度(从而扩大并行运算的规模),而Zen配有一个更加复杂的堆栈引擎,它可以取消某些堆栈操作指令。这同时改良了性能(同样是通过更大的并行运算规模)且降低了能耗。
核心设计的大大优化也为降低能耗做出了贡献。集成电路由多种不同的标准单元构成,比如NAND和NOT逻辑门,触发器,甚至是更复杂的元素,比如半加器和全加器。这其中的每个组成部分(叫做标准单元)都可以接受多种不同的设计,从而在性能、尺寸和耗能上权衡利弊。
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 一季度AMD全球处理器市场份额遭英特尔蚕食(07-01)
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- AMD 2016-2017 x86处理器路线图曝光(05-08)
- AMD结合显示与传统芯片力拚数据中心市场(05-18)
- 通过创新架构和电源技术提升处理器能效(08-05)