全面解读AMD Zen构架,风光无两背后到底靠的啥优势?
引爆点
Zen的基本构件是核心复合体(CCX):四核为一个单元,同时跑八个线程。恰好印证了AMD在桌面处理器的设计上对多核多线程的信仰的是,第一代锐龙Ryzen 7系列处理器搭载两个CCX,共八核十六线程。有三个版本即将发布:1800X,速度3.6-4.0GHz, 售价 $499/£490; 1700X,速度3.4-3.8GHz ,售价 $399/£390,以及1700, 速度3.0-3.7GHz,售价 $329/£320 。

Zen的核心复合体
第二季度中,锐龙Ryzen 5也将面世。R5 1600X是六核十二线程的芯片,以3.6-4.0GHz运行(两个CCX各关闭一核),1500X是四核八线程的芯片,以3.5-3.7GHz运行(只有单个CCX)。
Zen也会扩大规模。如AMD的服务器处理器,代号"那不勒斯(Naples)",搭载八个CCX,32核,64线程。
不同的设计决策已经让AMD和英特尔分道扬镳了。英特尔的处理器性能分布被岔开得很奇怪,它最新的处理器是Kaby Lake,但Kaby Lake只有双核和四核,有些有同时多线程(SMT)而有些没有。四核以上你又不得不回到前一代处理器架构了:Broadwell。
2014年9月首次面世的Broadwell是英特尔14纳米工艺的芯片,上一代Haswell架构的微缩版。目前,任何大于四核八线程的主流桌面或移动处理器都是基于Broadwell。这不仅包括面向发烧友的Broadwell-E处理器,搭载了六核、八核或十核以及12、16或20线程;还包括Broadwell-EP服务器处理器,直到两周前刚发布的Xeon E7-8894V4。这是8个插口24核48线程的芯片,定价在9000美元且不会有过多浮动。
第一代锐龙处理器刚好横跨英特尔产品线的断裂点。R7 1700多多少少会和Kaby Lake i7-7700K正面竞争。后者利用了英特尔14纳米工艺以及最佳单线程性能的最新架构,运行速度为4.2-4.5GHz. 但1800和1800X将迎击Broadwell架构,分别是六核12线程3.6-3.8GHz的i7-6850K处理器(约$620/£580 ),以及八核16线程3.2-3.7GHz的i7-6900K处理器(约$1,049/£1,000)。到了更高核数,英特尔就会迫使你放弃最新的核和最高的电源效力,从而不得不换回更老的、更新频率比较低的芯片集(目前的X99早在2014年底就发布了)。
更大更强悍的内核
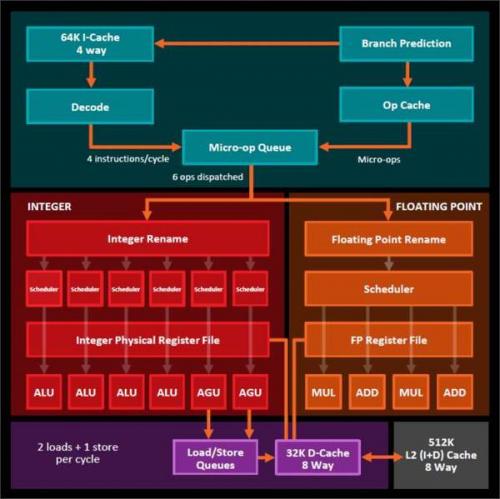
这些新的核都比推土机搭载了更多的运行资源。在整数管线上,Zen有4个算术逻辑单元(ALU)和两个地址产生单元(AGU)。浮点管线上,共享浮点单元的概念被废弃了:现在每个核都有一对独立的128位乘法叠加运算单元(FMA)。浮点单元内有分开的加法和乘法管线,用于在不进行乘法累积运算时应对更多样的混合指令。但256位AVX指令集还是得分开在两个FMA单元上执行,并动用所有的浮点单元。
这是推土机之后的巨大飞跃,从本质上讲,每个核可动用的整数和浮点运算资源都翻了个倍。然而与Broadwell和Skylake相比就不好说了。AMD的四个ALU虽然相似但不完全一样,所以有些指令必须在特定单元内处理(只有一个会算乘法,另一个会算除法),就算有其他的闲置单元也不能跨界运行。英特尔的就更加多样化,所以对于一些混合指令来说,英特尔的四个ALU实际上可能比AMD的要少。
更加复杂的是,AMD说总共六个指令可以在每周期中被发送到核的十个管线中(4个ALU,2个AGU,4个FP)。而Broadwell和Skylake都可以每周期发送八个指令。其中4个发送到AGU--Skylake有两个通用AGU和两个专用的。另外四个运算一些算数,要么整数要么浮点。
英特尔把所有功能单元分组分到四个发送端口下,编号0,1,5,6. 所有四个端口都包含一个普通的整数ALU,但端口0还含有一个AVX FMA单元、一个除法单元和一个分支单元。端口1有另一个AVX FMA单元但没有除法单元。端口5和6既没有FMA也没有除法单元。这意味着在一个周期内,处理器可以同时安排两个AVX FMA操作或是一个除法和一个AVX FMA操作,但没法同时做一个除法和两个FMA。
大体上,这说明在一个周期内,Zen可以发送四个整数运算和两个浮点运算。Skylake可以发送四个整数运算,但这需要动用所有四个端口,导致没法进行任何浮点运算。另一方面,Skylake和Broadwell都能在一个周期内同时发送四个整数运算和四个地址操作。Zen只能容纳两个地址操作。
推土机的弱点依旧如影随形
撇开区别不谈,我们就没法直接衡量这些设计的好坏。尽管如此,还是有些设计在个别方面的优势极其显著。英特尔的两种芯片都具备两个能同时启用的全256位AVX FMA单元。对于可以利用这一优势的代码来说,Skylake和Broadwell的性能都应该可以做到Zen的两倍。多年以来,AMD一直在尽力让GPU成为运行这种高强度浮点并行运算的最优选。所以某种意义上说这种差距也可以理解--但重度依赖AVX指令集的程序就会毫不犹豫地选择英特尔芯片了。
比如这在Geekbench的浮点测试SGEMM中就非常明显。这是一个矩阵乘法测试,为了最佳性能会调用AVX和FMA指令集。在单线程上,6900K管理着大约每秒900亿单精度浮点指令(90 gigaflops)。相比之下,1800X的处理速度只有53 gigaflops。虽然1800X相对更高的时钟速度有点用,但英特尔芯片在每个周期内能完成其两倍的工作量。高出来的几百兆赫不足以抵消架构区别带来的劣势。
当然,这种工作量从某种角度证明了AMD的观点:由GPU加速的相同矩阵乘法运算可以达到800以上gigaflop。如果你的计算需求包含大量的矩阵乘法,你是决不会想用慢吞吞的CPU来完成这项工作的。
AMD长期以来的难题,也是通用GPU计算的难题,就是当只有部分运算工作适合用GPU完成时该怎么办。把数据在CPU和GPU上搬来搬去会消耗额外的资源,而且这要求开发者在开发工具和编程语言间进行切换。虽然解决方法是有的,比如AMD的异构系统架构和OpenCL,但目前还没有被行业广泛采纳。
有一个Geekbench子测验从另一个角度显示了突出的优势。Geekbench有关于目前主流处理器用到的所有密码指令集的测试。在一个单线程性能测试中,锐龙碾压Broadwell-E,解码速度为4.5GB/s比2.7GB/s。锐龙有两个AES单元,都位于处理器的浮点部分。Broadwell只有一个,让AMD大大领先了。
但从单线程转到十六线程时情况就突然逆转:英特尔系统能跑到24.4GB/s而AMD只有10.2GB/s。这说明该测试在高线程数时会带宽受限,使得6900K的四存储渠道领先于1800X的双存储渠道。尽管锐龙具备更多的计算资源来进行这种运算,但当处理器干坐着等待数据传输时再多计算资源也无济于事。
至于单线程性能上,他们都输给了Kaby Lake i7-7700K。鉴于它更高的IPC和更快的时钟速度,Broadwell-E和Zen都是远远追不上的。
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 一季度AMD全球处理器市场份额遭英特尔蚕食(07-01)
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- AMD 2016-2017 x86处理器路线图曝光(05-08)
- AMD结合显示与传统芯片力拚数据中心市场(05-18)
- 通过创新架构和电源技术提升处理器能效(08-05)