深度学习硬件这件事,GPU、CPU、FPGA到底谁最合适?
基本单元。
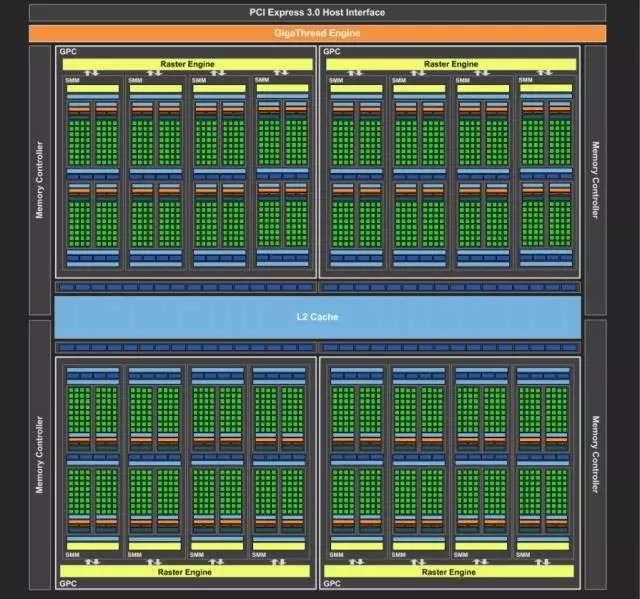
GPU进行数据处理的过程可以描述成:GPU从CPU处得到数据处理的指令,把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。如果一个核心的计算算作一个线程,那么在这颗GPU中就有32×4×16, 2048个线程同时进行数据的处理。尽管每个线程/Core的计算性能、效率与CPU中的Core相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于CPU。对于基于神经网络的深度学习来说,它硬件计算精度要求远远没有对其并行处理能力的要求来的迫切。而这种并行计算能力转化为对于硬件的要求就是尽可能大的逻辑单元规模。通常我们使用每秒钟进行的浮点运算(Flops/s)来量化的参数。不难看出,对于单精度浮点运算,GPU的执行效率远远高于CPU。
除了计算核心的增加,GPU另一个比较重要的优势就是他的内存结构。首先是共享内存。在NVIDIA披露的性能参数中,每个流处理器集群末端设有共享内存。相比于CPU每次操作数据都要返回内存再进行调用,GPU线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存》全局内存)。
再就是高速的全局内存(显存):目前GPU上普遍采用GDDR5的显存颗粒不仅具有更高的工作频率从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
而在传统的CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在CPU中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在60GB/s左右徘徊。与之相比,大显存带宽的GPU具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
而且就目前而言,越来越多的深度学习标准库支持基于GPU的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据GPU所具有的线程/Core数,去自动分配数据的处理策略,从而达到优化深度学习的时间。而这些软件上的全面支持也是其他计算结构所欠缺的。
2.2、未来
但是CPU真的在未来规模深度神经网络的计算中沦为花瓶么?CPU巨擘英特尔显然不甘于出现这样的局面。
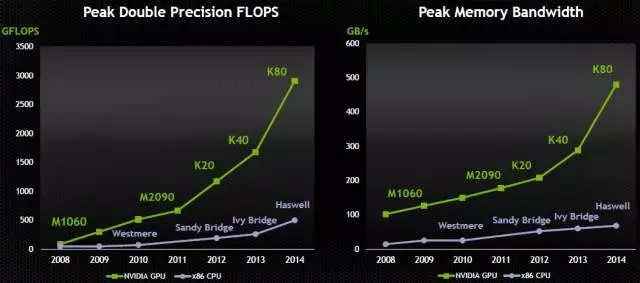
在其于去年发布的代号"KNL(Knignts Landing)融核"处理器介绍中,我们发现英特尔针对目前CPU的种种弊端做出了很大的调整:首先在硬件架构上集成了更多的核心(72颗),这意味着有更多的逻辑单元去进行运算。其次是英特尔为这些核心增加了"可变精度"的支持,在低精度模式下(深度学习通常使用单精度)大幅度提高其浮点运算能力(3+TFlops),甚至接近GPU的性能指标。在内存支持方面,它不仅可以支持更多的内存,而且大幅提高了与内存间数据通讯的带宽,这也解决了目前CPU数据传输速度的弊端。

与这颗处理器相匹配的,是"MIC(Many Integrated Core)"众核同构计算模型。也是有别于其他加速硬件而被称为众核计算的原因:它可以完美运行X86代码。简而言之就是它可以直接脱离CPU直接与内存相连来进行深度学习。相对于"CPU+加速硬件"的异构模型,这种众核计算在很大程度上避免了CPU与加速硬件之间的通讯带宽问题。从而优化深度学习训练时间。
以现状而论,GPU的风头远远盖过CPU,但是对于CPU而言,新发布的处理器在构架上的变化让它把曾经的劣势(核心数/带宽)逐渐变为了它潜在的优势。因此,二者数据训练领域之争还依旧会持续下去。
三、数据的推断:FPGA VS ASIC
虽然"CPU+GPU"或者"MIC"的计算模型被广泛的应用于各种深度学习中去。其实CPU与GPU都是利用现有的成熟技术去提供了一种通用级的解决方法来满足深度学习的要求,尽管如Intel 与NVIDIA不断推出了如"KNL"和"Pascal"系列加速芯片来助阵深度学习,但这仅仅是大公司对于深度学习的一种妥协,而并不是一种针对性的专业解决方案。
目前在深度学习模型的训练领域基本使用的是SIMD(Single Instruction Multiple Data:单指令多数据流架构)计算,即只需要一条指令就可以平行处理大批量数据。但是,在平台完成训练之后,它还需要进行推理环节的计算。这部分的计算更多的是属于MISD(Multiple Instruction Single Data:多指令流单数据流)。比如讯飞语音输入法
- 国内电子阅读器销量破百万 冲破发展瓶颈关键在内容(02-22)
- 台湾移动互联遇短板:硬件厂商大陆抢人才(06-07)
- 芯片大厂加入低价竞争 未来芯片市场愈发激烈(12-21)
- 移动支付之争剑拔弩张:硬件成本成普及拦路虎(01-11)
- 半导体消费无线硬件商居首 超普通PC厂商(02-06)
- 2012 MWC初探 华为大放异彩(03-05)