艳压CPU、GPU、ASIC,微软中意的FPGA到底有什么好?
群,里面插满了 FPGA
每台机器一块 FPGA,采用专用网络连接
每台机器一块 FPGA,放在网卡和交换机之间,共享服务器网络

微软 FPGA 部署方式的三个阶段
第一个阶段是专用集群,里面插满了 FPGA 加速卡,就像是一个 FPGA 组成的超级计算机。下图是最早的 BFB 实验板,一块 PCIe 卡上放了 6 块 FPGA,每台 1U 服务器上又插了 4 块 PCIe 卡。

最早的 BFB 实验板,上面放了 6 块 FPGA
只要规模足够大,对 FPGA 价格过高的担心将是不必要的。

最早的 BFB 实验板,1U 服务器上插了 4 块 FPGA 卡
像超级计算机一样的部署方式,意味着有专门的一个机柜全是上图这种装了 24 块 FPGA 的服务器(下图左)。这种方式有几个问题:
不同机器的 FPGA 之间无法通信,FPGA 所能处理问题的规模受限于单台服务器上 FPGA 的数量;
数据中心里的其他机器要把任务集中发到这个机柜,构成了 in-cast,网络延迟很难做到稳定。
FPGA 专用机柜构成了单点故障,只要它一坏,谁都别想加速了;
装 FPGA 的服务器是定制的,冷却、运维都增加了麻烦。

部署 FPGA 的三种方式,从中心化到分布式
一种不那么激进的方式是,在每个机柜一面部署一台装满 FPGA 的服务器(上图中)。这避免了上述问题 (2)(3),但 (1)(4) 仍然没有解决。
第二个阶段,为了保证数据中心中服务器的同构性(这也是不用 ASIC 的一个重要原因),在每台服务器上插一块 FPGA(上图右),FPGA 之间通过专用网络连接。这也是微软在 ISCA‘14 上所发表论文采用的部署方式。

Open Compute Server 在机架中

Open Compute Server 内景。红框是放 FPGA 的位置

插入 FPGA 后的 Open Compute Server

FPGA 与 Open Compute Server 之间的连接与固定
FPGA采用Stratix V D5,有172K个ALM,2014个M20K片上内存,1590个 DSP。板上有一个8GB DDR3-1333内存,一个PCIe Gen3 x8接口,两个10 Gbps网络接口。一个机柜之间的FPGA采用专用网络连接,一组10G网口8个一组连成环,另一组10G网口6个一组连成环,不使用交换机。
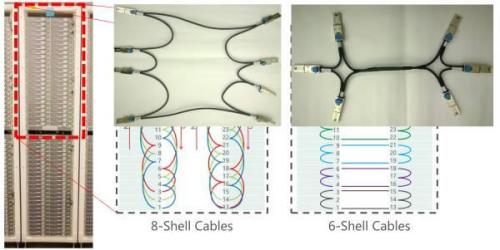
机柜中 FPGA 之间的网络连接方式
这样一个 1632 台服务器、1632 块 FPGA 的集群,把必应的搜索结果排序整体性能提高到了 2 倍(换言之,节省了一半的服务器)。如下图所示,每 8 块 FPGA 穿成一条链,中间用前面提到的 10 Gbps 专用网线来通信。这 8 块 FPGA 各司其职,有的负责从文档中提取特征(黄色),有的负责计算特征表达式(绿色),有的负责计算文档的得分(红色)。
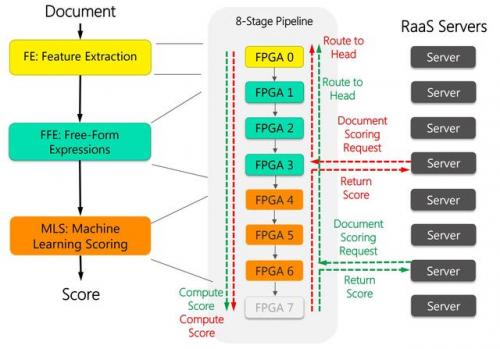
FPGA 加速必应的搜索排序过程
除了加速搜索结果的排序(RaaS,Ranking as a Service),FPGA 还被用来加速从倒排索引中取出相关文档并译码的过程(SaaS,Selection as a Service)。为了加快文档数据结构的访问,FPGA 把服务器主存里常用的 4K 内存页面缓存在 FPGA 板上的 DDR 上。

FPGA 不仅降低了必应搜索的延迟,还显著提高了延迟的稳定性

本地和远程的 FPGA 均可以降低搜索延迟,远程 FPGA 的通信延迟相比搜索延迟可忽略
FPGA 在必应的部署取得了成功,Catapult 项目继续在公司内扩张。微软内部拥有最多服务器的,就是云计算 Azure 部门了。Azure 部门急需解决的问题是网络和存储虚拟化带来的开销。Azure 把虚拟机卖给客户,需要给虚拟机的网络提供防火墙、负载均衡、隧道、NAT 等网络功能。由于云存储的物理存储跟计算节点是分离的,需要把数据从存储节点通过网络搬运过来,还要进行压缩和加密。
在 1 Gbps 网络和机械硬盘的时代,网络和存储虚拟化的 CPU 开销不值一提。随着网络和存储速度越来越快,网络上了 40 Gbps,一块 SSD 的吞吐量也能到 1 GB/s,CPU 渐渐变得力不从心了。例如 Hyper-V 虚拟交换机只能处理 25 Gbps 左右的流量,不能达到 40 Gbps 线速,当数据包较小时性能更差;AES-256 加密和 SHA-1 签名,每个 CPU 核只能处理 100 MB/s,只是一块 SSD 吞吐量的十分之一。

网络隧道协议、防火墙处理 40 Gbps 需要的 CPU 核数
为了加速网络功能和存储虚拟化,微软把 FPGA 部署在网卡和交换机之间。如下图所示,每个 FPGA 有一个 4 GB DDR3-1333 DRAM,通过两个 PCIe Gen3 x8 接口连接到一个 CPU socket(物理上是 PCIe Gen3 x16 接口,因为 FPGA 没有 x16 的硬核,逻辑上当成两个 x8 的用)。物理网卡(NIC)就是普通的 40 Gbps 网卡,仅用于宿主机与网络之间的通信。

Azure 服务器部署 FPGA 的架构
FPGA(SmartNIC)对每个虚拟机虚拟出一块网卡,虚拟机通过 SR-
- 嵌入式系统与FPGA的最新动向(05-18)
- FPGA走向硅片融合时代(07-12)
- 20nm时代,FPGA或将拔得头筹(11-30)
- 没有退路的FPGA与晶圆代工业者(01-03)
- 电源管理成为FPGA新的技术突破口(12-16)
- 数字电源为FPGA带来高效率(12-16)