大神讲解深度学习卷积在GPU上的优化思路
时间:07-19
来源:雷锋网
点击:
内存访问是有一些特性的,连续合并访问可以很好地利用硬件的带宽。你可以看到,NVIDIA最新架构的GPU,其核心数目可能并没有明显增加,架构似乎也没有太大变化,但在几个计算流处理器中间增加缓存,就提高了很大的性能,为IO访问这块儿带来了很大优化。 上面是一张比较经典的内存和线程模型,shared memory和registers是访问速度最快的内存,内存的访问跟计算比起来,太慢了,所以尽量把多的数据都放到高速的缓存里面。 矩阵优化的几个思路 从计算角度出发 从结果出发 以上面这张图为例,当我们从C矩阵的结果出发,每一个C需要A的一行和B的一列来进行计算,利用GPU的特性,我们可以把零时的结果存储在registers面,那我们就可以划分64x2个线程,来作为计算线程。 在C的影印部分,可以有64×2这么多个线程在一次访问,就可以存储64×2个数据。你可以让64×2个线程每一个线程都存储16个或者32个数据,那么,我们就可以用64×2个线程存储64×2×16(32)个数据。 这么多个数据都可以一次存储在最快的内存里面,多次读写的时候,速度就可以很快。同时,我们在考虑对A和B矩阵的访问,可以把B矩阵的相应的数据,大量的放到shared memory里面,这样就提高了shared memory的公用性。这样,整个A×B再根据这些线程可以在读取globalmemory( A矩阵)的时候,可以合并访问,可以按照每一排32、32的读取,可以加快合并访问=C。这样就把整个矩阵优化的思路整理出来了。 以上就是针对深度学习卷积在GPU、乃至Jetson TX1平台上的一些优化思路。 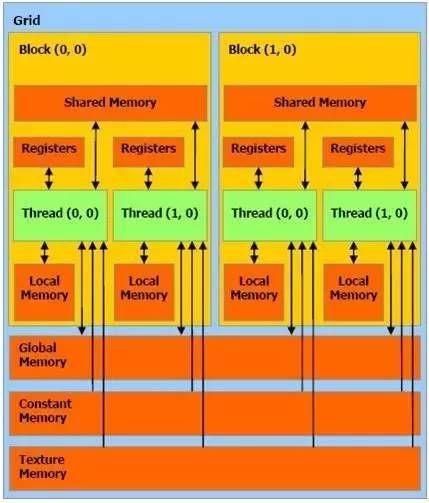

- 人脸识别安全吗?双胞胎先别哭,看看专家怎么说(08-08)
- 人脸识别技术哪家强,新红外LED来“逞强”(01-04)
- 生物特征识别技术的发展趋势及对数字信号处理器的挑战 (02-17)
- 一个天才少年研发的人工智能处理器,据说要撼动英特尔(02-25)
- 50大“全球最聪明公司”出炉,BAT掉队的百度排名第50(05-28)
- 不把iPhone 8人脸识别放在眼里,高通哪来的自信?(07-16)