大神讲解深度学习卷积在GPU上的优化思路
提到人工智能领域,现在最热的词之一就是深度学习Deep Learning(下文简称DL)。近年来,深度学习成为了学术界乃至整个工业领域视觉计算方面的绝对主流。除了传统的计算机几何处理、专业渲染、医疗、生命科学、能源、金融服务、汽车、制造业以及娱乐业纷纷着力深度学习应用和技术优化,避免在企业竞争中失利。在群雄逐鹿的技术比拼中,GPU扮演着至关重要的角色,与其相关的技术优化也是研发人员关注的焦点之一。
"深度学习技术已经可以用于解决实际的问题,而不是停留在Demo演示阶段"
如微软的语音翻译、Google的猫识别,再到最近很火的人脸识别,还有自动驾驶等等,这些都是深度学习的典型应用。Alibaba、Baidu、Facebook、Google、IBM等大公司都在DL方面有很大的投入。这里必须强调一句,目前很多主流的DL框架和算法基本上都是华人主导开发的,DL的复兴,离不开华人研究者。
"在进行深度学习训练之前,你需要考虑的两件事"
一个是软件框架,例如Caffe,Tensorflow,Mxnet等等。
另一个就是硬件。硬件方面,目前有多种异构形式,cpu,fpga,dsp等等,但是最主流的还是GPU,真正能在DL当中快速形成战斗力的也是CUDA硬件(NVIDIA GPU)+CUDA的DL学习软件(cuDNN),这也是NVIDIA多年研发与培育的结果。
工欲善其事,必先利其器
现在主流的DL开发训练平台一般都用NVIDIA的显卡,比如NVIDIA TITAN系列就是非常好的工具。为了加快训练速度,一般选择在配备多个GPU的高性能计算机或集群上面进行训练,训练好的网络也很容易移植到采用NVIDIA Tegra处理器的嵌入式平台上面,如NVIDIA Jetson TX1,它们拥有相同的架构,所以移植起来会非常方便。
Jetson TX1基于NVIDIA Tegra X1处理器打造,它采用和超级计算机完全相同的Maxwell架构256核心GPU,可提供高达1T-Flops的计算性能并完整支持CUDA(Compute Unified Device Architecture)技术,配合预装的开发工具,非常适合基于深度学习的智慧型嵌入式设备的打造。前不久就有用户通过配备Tegra处理器的Jetson平台,检测自家花园是否有小猫闯入。
重头戏:卷积神经网络CNN算法优化
检测小猫闯入花园的视频红遍网络,这一应用就用到了卷积神经网络(Convolutional Neural Network,简称CNN)的分类,在台式机或者集群上学习,然后porting(移植)到Tegra上,CNN算法起了关键作用。而CNN最关键的部分就是卷积层。在图像识别,图像分类领域来讲大多数问题之所以CNN能起作用,关键就是卷积。它从两个方面演变而来,一个是声音处理的延时网络,一个是图像处理的特征点提取算法。对后者而言,卷积就是对图像做滤波,简单说,就是做一些特征值提取。常见的有sobel做边缘提取,还有hog,高斯滤波等等,这些都是二维卷积。
卷积形状优化
虽然现在大家做卷积都是方块的,但其实这只是定义,你完全可以不遵循这个标准,可以用其他的形状来代替卷积,去更好的适应你的运算方式,尤其是卷积核心比较大的时候,这也是对卷积做出优化的一种方式。 一般来说,目前比较流行的CNN网络,卷积部分会占用70%以上的计算时间,优化卷积部分就是很有必要的。你需要从算法角度、并行化角度,以及GPU硬件特性等诸多方面做出考量。 GPU本身是一种可编程的并行计算架构,它有很多很好的算法,同时NVIDIA也提供了相应的工具,帮你去进行优化。
卷积优化的基本思路
1. 计算并行
2. 数据并行
3. 并行的粒度
4. 空间换时间
5. IO和计算叠加
6. 更多的利用高效的缓存空间
7. 针对硬件的并行特性,更高效率的利用网络并发型
用内存来换时间
如果深度学习DL中每一层的卷积都是针对同一张图片,那么所有的卷积核可以一起对这张图片进行卷积运算,然后再分别存储到不同的位置,这就可以增加内存的使用率,一次加载图片,产生多次的数据,而不需要多次访问图片,这就是用内存来换时间。
乘法优化
卷积是对一个小区域做的乘法,然后再做加法,这在并行计算领域是非常成熟的。
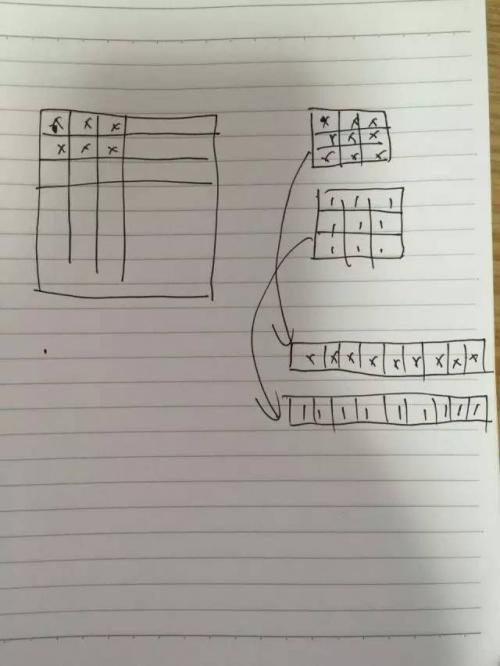
以上图为例,左边是一张图片,右边是卷积核。我们可以把卷积核心展开成一条行,然后多个卷积核就可以排列成多行,再把图像也用类似的方法展开,就可以把一个卷积问题转换成乘法问题。这样就是一行乘以一列,就是一个结果了。这样虽然多做了一些展开的操作,但是对于计算来讲,速度会提升很多。
GPU优化的几个思路
了解IO访问的情况以及IO的性能;
多线程的并行计算特性;
IO和并行计算间的计算时间重叠
对于NVIDIA的GPU来讲,
- 人脸识别安全吗?双胞胎先别哭,看看专家怎么说(08-08)
- 人脸识别技术哪家强,新红外LED来“逞强”(01-04)
- 生物特征识别技术的发展趋势及对数字信号处理器的挑战 (02-17)
- 一个天才少年研发的人工智能处理器,据说要撼动英特尔(02-25)
- 50大“全球最聪明公司”出炉,BAT掉队的百度排名第50(05-28)
- 不把iPhone 8人脸识别放在眼里,高通哪来的自信?(07-16)