浅谈处理器核心构架,嵌入应用又有啥新招
NEON指令集可用下列多种方式存取:
.有程式库支援常见的数学与分析功能及演算法。
.编译器支援完整的内部功能集,允许从C直接存取完整的NEON指令集。透过这种方法,NEON作业便能以最便利的方式与C程式码交错处理。
.NEON可直接在组译器内手动执行。
.编译器亦支援反覆回路的自动向量。只要遵循一些简单的指示来编写程式码,即使是稍显复杂的回路,编译器也能有效执行及向量化。
如果使用者熟悉ARMv7-A处理器,应该也会注意到ARMv8-A加入一些额外的指令。
.密码编译延伸模组(Cryptographic Extensions)
这些指令为ARMv8-A新加入,目的是为了有效实作常见的加密功能建构区块演算法。这些延伸是在NEON备份暂存器上运作。
.Load-Acquire和Store-Release
这些新指令符合C++11记忆体排序语法,能提升编译效率。也可用来减少对资料侧记忆体局限的需求,并部分减少与其相关的工作量。
还有一些其他与浮点和限制指令有关的小型延伸。
虚拟记忆体支援
支援完整虚拟记忆体环境为ARMv8-A主要功能之一,正是透过这项功能,这些装置才能支援Linux和Android等平台作业系统。因此,虚拟记忆体功能经常也是在这些核心中进行选择时最为关键的条件。
虚拟记忆体环境可让作业系统管理记忆体时更富弹性,像是使个别处理程序动态延伸堆叠区,启用个别的程式码,让资料区能视需要在外部储存空间内部和外部进行分页,让个别的使用者处理程序可以检视完全相同的系统记忆体配置图。
为发挥作用,虚拟记忆体在处理器所配发的每个位址上加入了"转译",如图7所示。软体会在"虚拟位址空间"执行,还有一个名为记忆体管理单元的区块会将其转译为实体位址空间。
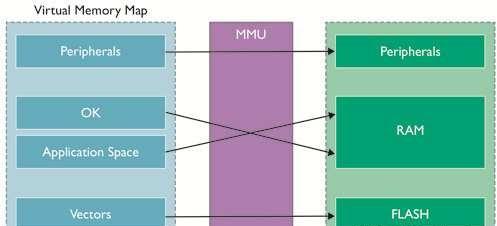
图7 虚拟记忆体
为了使作业系统完整控制存取权限等内容,以针对系统内的各项使用者工作及作业系统本身建立新的虚拟记忆体配置图。每项工作可当作系统内唯一的工作,在自己的虚拟记忆体空间内执行。只有作业系统知道工作程式码及资料区在外部实体记忆体内的实体位置。
在切换工作时,作业系统的其中一项任务就是重新设定记忆体管理单元,以启用传入工作所用的程式码及资料,同时让传出工作的记忆体暂时无法存取。如此可强制区分工作,为安全且弹性的系统的必要元素。
此处不会提供完整说明,ARM处理器内的记忆体管理单元使用保留在外部记忆体中的"分页表"所含的资料来带动及控制转译。系统整合多项最佳化作业(例如,包含Translation Lookaside Buffers,或简称为TLB,能为最近使用过的转译建立快取,以减少读取分页表的工作量),可尽量缩小转译处理程序的工作量。
从ARMv7-M到ARMv7-A的软体转移
多数的高阶软体皆须要简单的重新编译。下列区域的软体则须详加注意:
.重置程式码及其他例外处理常式
如果使用作业系统,这部分的工作将由作业系统所提供的工具来处理。多数情况下,常见作业系统的连接埠将透过公开网域散布或装置供应商提供。
因异常模式差异较大,因此须重新写入中断处理常式。作业系统同样会提供基础架构来完成这部分工作,藉以简单地重新编译多数中断处理常式的主体。
.周边驱动程式
从RTOS转移到Linux这类的多功能平台作业系统时,应用程式码及周边驱动程式须更明确地加以区隔。
.系统组态功能
采用Cortex-M与Cortex-A的装置在提供系统组态与控制功能存取方面有较大的差异。Cortex-M处理器通常透过具名或记忆体对映的暂存器来设定,可直接读取及写入,以达成所要的功能。Cortex-A处理器(为Cortex-A32所支援的AArch32执行状态)则是透过"系统控制协同处理器"来支援设定。概念性的"协同处理器15"包含大量的设定暂存器集,使用专属的指令进行读取及写入。非由作业系统执行的系统组态功能则须重新写入,以完成这部分的工作。也就是说,作业系统通常会提供应用程式介面(API),以用于须要由使用者介面存取的功能。
.汇编程式码
很明显地,汇编程式码也须特别注意。因为写入汇编程式码的其中一个主要原因,便是为了获得最高的效能,因此必须详加检验这些功能,确定重新写入能在存取NEON等某些延伸指令集功能时提供好处。若旧型的汇编程式码已使用"Uniform Assembler Language(UAL)"语法写入,则多数程式码将简单地重新汇编为ARM或Thumb指令。
- 细说嵌入式领域的那些专业厂商认证(02-22)
- 嵌入式微处理器将走向何方?(03-09)
- 嵌入式系统与FPGA的最新动向(05-18)
- 2011 TI技术研讨会中国站揭开大幕(09-24)
- 新兴嵌入式产品持续推动传感器快速增长(06-20)
- Cortex-M4致三大嵌入式领域比拼新技术(09-13)