机器人“芯”脏革新,FPGA为啥这么牛
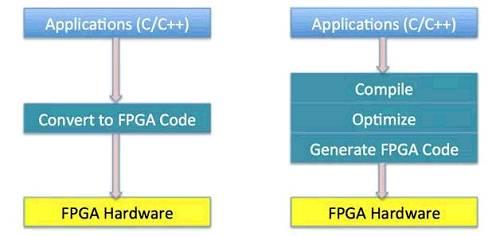
图4 传统FPGA开发流程与C-to-FPGA开发流程
图4显示了传统FPGA开发流程与C-to-FPGA开发流程的对比。在传统的FPGA开发流程中,我们需要把C/C++写成的算法逐行翻译成基于Verilog的硬件语言,然后再编译Verilog,把逻辑写入硬件。随着近几年FPGA技术的发展,从C直接编译到FPGA的技术已经逐渐成熟,并已在百度广泛被使用。在C-to-FPGA开发流程中,我们可以在C\C++的代码中加Pragma, 指出哪个计算Kernel应该被加速,然后C-to-FPGA引擎会自动把代码编译成硬件。在我们的经验中,使用传统开发流程,完成一个项目大约需要半年时间,而使用了C-to-FPGA开发流程后,一个项目大约两周便可完成,效率提升了10倍以上。
感知计算在FPGA上的加速
接下来主要介绍机器人感知计算在FPGA上的加速,特别是特征提取与位置追踪的计算(可以认为是机器人的眼睛),以及深度学习计算(可以认为是机器人的大脑)。当机器人有了眼睛以及大脑后,就可以在空间中移动并定位自己,在移动过程中识别所见到的物体。
特征提取与位置追踪
特征提取与位置追踪的主要算法包括SIFT、SURF和SLAM。SIFT是一种检测局部特征的算法,通过求一幅图中的特征点及其有关规模和方向的描述得到特征并进行图像特征点匹配。SIFT特征匹配算法可以处理两幅图像之间发生平移、旋转、仿射变换情况下的匹配问题,具有很强的匹配能力。SIFT算法有三大工序:1. 提取关键点;2. 对关键点附加详细的信息(局部特征)也就是所谓的描述器;3. 通过两方特征点(附带上特征向量的关键点)的两两比较找出相互匹配的若干对特征点,也就建立了景物间的对应关系。SURF算法是对SIFT算法的一种改进,主要是通过积分图像Haar求导提高SIFT算法的执行效率。SLAM即同时定位与地图重建,目的就是在机器人运动的同时建立途经的地图,并同时敲定机器人在地图中的位置。使用该技术后,机器人可以在不借助外部信号(WIFI、Beacon、GPS)的情况下进行定位,在室内定位场景中特别有用。定位的方法主要是利用卡曼滤波器对不同的传感器信息(图片、陀螺仪)进行融合,从而推断机器人当前的位置。
为了让读者了解FPGA对特征提取与位置追踪的加速以及节能,下面我们关注加州大学洛杉矶分校的一个关于在FPGA上加速特征提取与SLAM算法的研究。图5展示了FPGA相对CPU在执行SIFT feature-matching、SURF feature-matching以及SLAM算法的加速比。使用FPGA后,SIFT与SURF的feature-matching分别取得了30倍与9倍的加速,而SLAM的算法也取得了15倍的加速比。假设照片以30FPS的速度进入计算器,那么感知与定位的算法需要在33毫秒内完成对一张图片的处理,也就是说在33毫秒内做完一次特征提取与SLAM计算,这对CPU会造成很大的压力。用了FPGA以后,整个处理流程提速了10倍以上,让高帧率的数据处理变得可能。
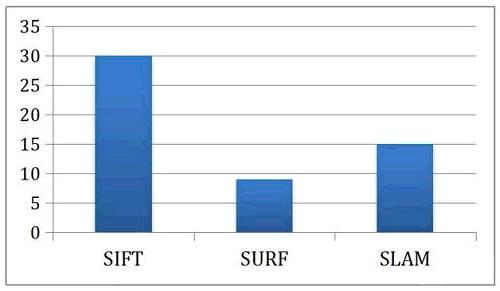
图5 感知算法性能对比 (单位:加速比)
图6展示了FPGA相对CPU在执行SIFT、SURF以及SLAM算法的节能比。使用FPGA后,SIFT与SURF分别取得了1.5倍与1.9倍的节能比,而SLAM的算法取得了14倍的节能比。根据我们的经验,如果机器人将手机电池用于一个多核的Mobile CPU去跑这一套感知算法,电池将会在40分钟左右耗光。但是如果使用FPGA进行计算,手机电池就足以支撑6小时以上,即可以达到10倍左右的总体节能 (因为SLAM的计算量比特征提取高很多)。
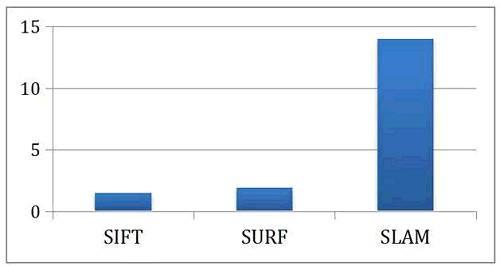
图6 感知算法能耗对比 (单位:节能比)
根据数据总结一下,如果使用FPGA进行视觉感知定位的运算,不仅可以提高感知帧率,让感知更加精准,还可以节能,让计算持续多个小时。当感知算法确定,而且对芯片的需求达到一定的量后,我们还可以把FPGA芯片设计成ASIC,进一步的提高性能以及降低能耗。
深度学习
深度神经网络是一种具备至少一个隐层的神经网络。与浅层神经网络类似,深度神经网络也能够为复杂非线性系统提供建模,但多出的层次为模型提供了更高的抽象层次,因而提高了模型的能力。在过去几年,卷积深度神经网络(CNN)在计算机视觉领域以及自动语音识别领域取得了很大的进步。在视觉方面,Google、Microsoft与Facebook不断在ImageNet比赛上刷新识别率纪录。在语音识别方面,百度的DeepSpeech 2系统相比之前的系统在词汇识别率上有显著提高,把词汇识别错误率降到了7%左右。
为了让读者了解FPGA对深度学习的加速以及节能,我们下面关注北京大学与加州大学的一个关于FPGA加速CNN算法的合作研究。图7展示了FPGA与CPU在执行CNN时的耗时对比。在运行一次迭代时,使用CPU耗时375毫秒,而使用FPGA只耗时21毫秒,取得了18倍左右的加速比。假设如果这个CNN运算是有实时要求,比如需要跟上相机帧率(33毫秒/帧),那么CPU就不可以达到计算要求,但是通过FPGA加速后,CNN计算就可以跟上相机帧率,对每一帧进行分析。
- 更多机器人参与日本地震搜救工作(03-28)
- e络盟引入欧姆龙E2A系列柱状距离传感器(05-16)
- 工业机器人与生产转型间的关系剖析(06-19)
- 工业机器人大规模应助力改变固有体系(07-29)
- 钕铁硼传统旺季 检测机器人将派上大用场(11-12)
- 大数据——Google机器人个性专利(04-15)