技术控必看,谷歌工程师首次揭秘AlphaGo的算法
AlphaGo的几个核心部分是:
1。 Policy Network: 用来预测如果是人类最好的选手,他会选择哪一个走法。这个模型是用深层神经网络实现的,其实是建立了最好棋手棋感的一部分。
2。 Fast rollout: 快速走子,跟1的功能一样,但是用了不同的模型,这个模型跟预测点击率的Logistic Regression模型没有区别。
3。 Value Network: 评估当前的棋局形势。
4。 Monte Carlo Tree Search: 蒙特卡洛树搜索。用来进行状态空间的快速搜索的概率模型。
拿着刚刚学习的东西来对比:
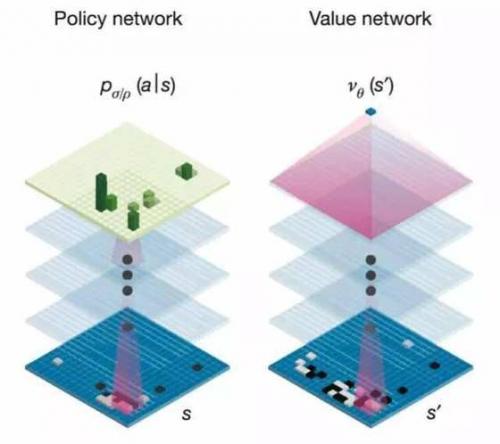
Policy/Value Network是对比与上文说的评估函数。在上面的搜索树里面用了一个简单的数数的方式,而在AlphaGo中,用的是棋感和预测走子的方式来进行构建状态空间。
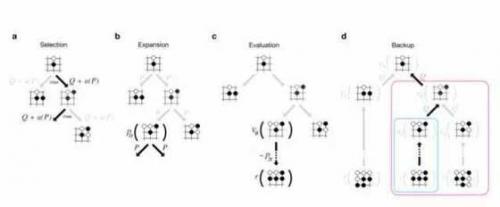
而蒙特卡洛树搜索是一个概率搜索算法,跟上面的博弈树搜索是一个套路的东西,只是用的是概率模型来进行更有效的搜索。
鼓励师
太复杂了没看懂,那么您直接告诉我。。。他的贡献是什么吧?
许丞
建立了棋感是很重要的贡献。人和机器根本的不一致在于: 如果你给他看一个图片;对于机器而言,他看到的都是0/1这样的二进制数字,除了最基础的可以去数里面有多少不同颜色什么信息以外,啥都不知道。而人可以从全局的角度看这个图片,这样就能知道这个图片大概是什么东西,是什么内容。
棋感也是一样--人工神经网络应用在计算机视觉上的重要突破,就是人不再让计算机用0/1来去识别图像内容了,而是让计算机自动的去抽取图像的语义特征--当然很可能只是一个一个小图块tiles这种组合方式的语义特征。这样计算机就可以开始慢慢的能够开始感知到这个物体可能是什么特征通过线性组合出来的。慢慢的也就形成了概念。而棋感就是类比于这样的概念!
其二是增强学习。也就是说计算机可以开始通过自己和自己进行比赛的方式来提高自己的模型的精度。在此之前,所有的机器学习大部分都可以说是监督学习,人类在扮演着一个家长的角色,不停的告诉自己的计算机模型说这个是对的,这个需要修正。而现在在AlphaGo中,他们实现的无监督学习已经可以让人不用再去当家长,他们左右互搏也能学习到非常强的知识。这个结果非常可怕
鼓励师
目前不管是AlphaGo战胜李世石还是李世石战胜了AlphaGo ,这场人机大战对未来会有什么影响呢?
许丞
我认为这个影响将会是巨大的。在此之前,虽然人工智能,机器学习也算是人尽皆知的词汇,但是此次新闻的传播影响之大,从来没有过让普通人去这么去关心人工智能的进展。这次人机大战可以说是影响力全面超越了卡斯帕罗夫深蓝大战那次。可以预言人工智能在接下来的几年之内一定是最热的热点话题,可以想象会有更多大学生投入到其中的学习和研究之中,也可能会让投资更多的聚焦于这个领域,更多的应用和场景,进而会产生让人不可思议的结果。
AlphaGo中的技术和算法显然不会只用于下棋,有意思的是历史上的每一次人机棋类大战都会带来更多新技术的进步。1989年我的老师李开复博士带着他的实习生在奥赛罗比赛中,利用统计学习打败了当时的世界冠军。也许当时对大部分的人来说,其实也仅仅是一次人机大战而已。然而那次之后,统计学习在非特定人语音识别系统开始发挥无与伦比的作用,传统的基于规则的语音识别系统被打得找不着北。现在我们能用到的siri, 自动电话应答机都是从此变为现实。更重要的是,从此之后,统计学习理论基本上统治了整个机器学习这个学科的所有研究方向,延续了差不多20多年。
今天,风水轮流转,曾经被认为没前途的神经网络技术卷土重来,通过深度学习的方式再次让人类在视觉识别,棋类竞技等项目上败给机器,重新占据了学术研究的焦点。这是一场计算机智能革命,这些比人机大战结果的更有现实意义。我相信,随着这些算法应用到计算机视觉,自动驾驶,自然语言理解等领域,AlphaGo及其带来的人工智能革命必将改善我们所有人的生活。
- 美博客称谷歌摩托移动交易可能成为一场灾难(08-16)
- 谷歌再加码投资可再生能源(10-10)
- 谷歌苹果在美手机市场排前两位(12-31)
- 谷歌收购摩托罗拉 国产手机厂商将继续受益(05-23)
- 未来Android平台可能走向半封闭(05-26)
- 苹果VS谷歌,谁是最后的赢家?(06-26)