STA Timing Report分析
Startpoint: rxRX/*/FE1_reg
(rising edge-triggered flip-flop clocked by RXCK_LB_EXT)
Endpoint: rxRX/*/r_CDERR_LEN_reg_reg_11_
(rising edge-triggered flip-flop clocked by RDCK_LB_EXT_SEL')
Path Group: RDCK_LB_EXT_SEL
Path Type: max
Scenario: USER_SETUP_11_CMAX_HOT
PointIncrPath
---------------------------------------------------------------------------------
clock RXCK_LB_EXT (rise edge)0.000.00
clock network delay (propagated)8.828.82
rxRX/*/FE1_reg/CP (F2QX4)0.008.82 r
rxRX/*/FE1_reg/Q (F2QX4)0.19 &9.01 r
rxRX/*/U4/Z (IVX1)0.05 &9.06 f
rxRX/*/U3/Z (NR2X1)0.14 &9.19 r
rxRX/*/Z (IVX6)0.11 &9.30 f
rxRX/*/Z (ND2X12)0.07 &9.38 r
rxRX/*/add_place_opt_381/Z (IVX12)0.05 &9.43 f
rxRX/*/add_post_place_optX2_154/Z (IVX16)0.04 &9.47 r
rxRX/*/add_post_place_optX2_153/Z (IVX16)0.05 &9.52 f
rxRX/*/add_place_opt_376/Z (IVX16)0.11 &9.63 r
rxRX/*/add_place_opt_277/Z (NIVX16)0.14 &9.77 r
rxRX/*/U115/Z (ND2IX1)0.10 &9.87 r
rxRX/*/U117/Z (ND2X1)0.24 &10.11 f
rxRX/*/r_CDERR_LEN_reg_reg_11_/D (FD1EQX4)0.03 &10.13 f
data arrival time10.13
clock RDCK_LB_EXT_SEL' (rise edge)1.981.98
clock network delay (propagated)7.189.16
clock reconvergence pessimism0.009.16
rxRX/*/r_CDERR_LEN_reg_reg_11_/CP (FD1EQX4)9.16 r
library setup time-0.358.81
data required time8.81
---------------------------------------------------------------------------------
data required time8.81
data arrival time-10.13
---------------------------------------------------------------------------------
slack (VIOLATED)-1.32
derating要求:-late 1.146 -early 1.0
请教高手有何良方解决这个violation?
1、skew在clock route前0.15ns,clock route后
0.5ns左右,加上derating之后,skew变为1.6ns。所以setup违例
这个latency已经是调试过最小的一个。
2、usefull skew的方法暂不考虑
3、RDCK_LB_EXT_SEL' 是clock翻转吧,与前端沟通不能设muilti-cycle。
补充:CRPR 设定的是same_transition,所以这里crpr没起作用
拉近2个FF的距离,重做CTS,减小skew
谢谢涛哥的回复。这类违例的path有近200条,全部手动拉近FF的距离吗?CTS时的skew已经做到0.15ns了,现在的skew是加上clock route和derating之后的skew。
"skew在clock route前0.15ns, clock route后0.5ns左右,加上derating之后,skew变为1.6ns"
这个现象比较奇怪,
1)查clock route的结果,选用RC小的metal,
2)CRPR 设定是否可以去掉same_transition的条件?
谢谢您的回复。crpr的设定是客户要求,不能改变。
clock route已经选用高层rc较小的layer,clock route完skew0.5还能接受,关键是derating的影响。
这种timing path即使我在cts时skew做到0ns,因为7ns的latency,加上derating计算后skew也是1ns左右。
Pre CTS也考虑了derating的margin去优化的。
ICC CTS时能考虑derating去做CTS吗?
only "usefull skew" can help
谢谢小编指点。usefull skew我也用过,但是带来两个其他问题。
1、normal setup使用usefull skew修完后,scan capture的setup和normal hold出现较大违例
2、min pulse width出现违例。使用的都是INV,因为一个INV的delay在worst条件下大概0.08ns
左右,如果加1ns的delay需要10个INV左右。开始我考虑用少量INV加上net delay,这样报出大量
的min pulse width违例;后来我改用cell delay(不考虑net delay),min pulese width违例减小一点,但是还是存在。
所以 ,我的前提是暂时不考虑uesfull skew的方法。想从其他方面着手,例如减小latency、考虑OCV的CTS、PreCTS考虑OCV加margin的优化等方法,都无济于事,真的很无奈。
另外,FF lib中记载是rise edge查的,现在timing report中出现clock反转,很奇怪,不知小编有何高见,请指点,谢谢!
你的clk不是很快,为什么会有min pulese width?
clk反转是设计上的原因,可以向前端确认,其实这条path的重要问题就是只有半个周期的时间
derate到底设了多少?
问题解决方法:
减小latency,进而减小derating的影响。
usefull skew也可以解决但是如果违例量很大,就不太好实现。
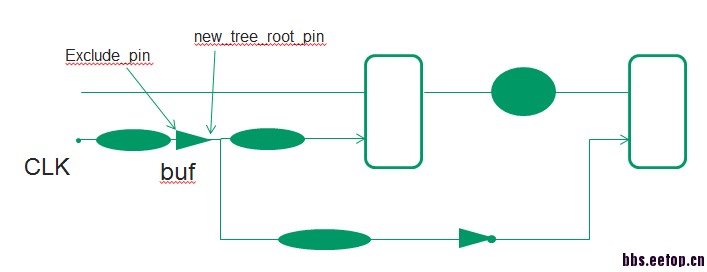
对于你这条path,我画了个简单的电路图,如上图。
你这条path明显是同一个clock下的半周期check path。
造成violation的原因是tree没长好,skew太大。
1. 如果你这个module rxRX下的FF不需要和其他module下的FF做balance
我推荐的方法使在common path上找一个buf,作如下设置:
set_clock_tree_exceptions -exclude_pins "$buf/A"
create_clock -name new_clk -period $num -waveform { 0$num/2 } [get_pins {$buf/Z}]
set_clock_uncertainty$num/10 [get_clocks {new_clk}]
set_clock_transition -rise -max$num/10 [get_clocks{new_clk}]
set_clock_transition -fall -max$num/10 [get_clocks{new_clk}]
set_clock_transition -rise -min$num/10 [get_clocks{new_clk}]
set_clock_transition-fall -min $num/10 [get_clocks {new_clk}]2.如果你这个module rxRX下的FF需要和其他module下的FF做balance
可以将rxRX的FF设为float pin。
set all_reg [all_registers ]
set dbg_all_regs [get_cells $all_reg -filter "full_name=rxRX/*"]
set dbg_all_regs_pins [get_pins -of $dbg_all_regs -filter "name==CLK"]
foreach_in_collection clk_pin $dbg_all_regs_pins {
set_clock_tree_exceptions -float_pins $clk_pin -float_pin_max_delay_rise -$num-float_pin_max_delay_fall -$num -float_pin_min_delay_rise -$num -float_pin_min_delay_fall -$num
}
注意两段代码中每个$num,需要你自己set。
小编,请你一定要尝试下我的方案,并及时反馈结果。
我的方法会增加latency,如果latency达不到你们chip的要求,你可以通过 set_clock_latency -max以及手动fix clock cell等方法来调节。
我这个方法在我遇到的类似的问题中都能很好的解决吧。如果要没解决你的问题,或者不懂,请回复我。
一级逻辑不过几十p,clock latency确实够长,report 加个-path full_clock_ex 上来看看。useful skew没什么不好,hold有问题就工具修,很少看到两边顶上的,真要是顶上,可能约束有问题或者其他奇怪的地方。还是先确认采样时钟的半周期问题是否合理,这比什么都重要。然后确认clock latency没问题。
clock latency 8.82, data requirement 8.81
首先,不知道你有没有注意到crpr的设定是same transition。
另外,skew是长的latency加后derating引起的。不加derating我的skew几乎接近0。
你说的设floatingpin的方法我在工作之后尝试过,效果不是很明显。
关于半周期及制约都经过严格确认,没有问题.
我没怀疑什么啊。
那你latency那么大,所以我说你tree没长好。
在方法1中,你参考图片上的结构图,在common path的结束点设置新的tree的root点,就是做新的tree,重新计算latency,此时新tree的latency就小了,derating影响小,你的这些path就met了。
你能不能发这条path在dc综合,place后,cts后,route后这四步full clock timing report。
我想看看这条path如何变化。
麻烦顺便把这条path的launch path map和capital path map发出来。
都知道你的latency很大,那就找出为什么这么大的原因撒。
首先,非常感谢您的耐心解答。
您说的方法1,制约不能随便修改,clk root改也只能是在cts阶段修改,sta时还是laytency很大。
另外,这个工作3个月前就结束了,数据已经全部删除,很抱歉不能提供您要的一些数据。
还是很感谢您的耐心指点,以后有什么新发现及时和您沟通。
最后,我工作最终减小latency的方法是:
手动配置clock path上的mux、icg等cell,size驱动;
修正clock port作为root的制约;
调试一些cts的制约option;
最终的laytency不到5ns。
我说怀疑制约可能是对另外一位仁兄overdriver 的回答,请不要见怪。
谢谢!
呵呵,先恭喜你。
好吧,其实我的意思就是要你在CTS时做。你说的:
手动配置clock path上的mux、icg等cell,size驱动;
修正clock port作为root的制约;
调试一些cts的制约option;
和我给的方法:
方法1和方法2.
“如果latency达不到你们chip的要求,你可以通过 set_clock_latency -max以及手动fix clock cell等方法来调节”
入手点是一样:都是调好这个clock的tree。
因为你这个timing根本就修不下去,所以只有调tree。
减少latency,还可通过mesh等结构来解决的。
后端最简单的回答就是发现问题,找到原因,给出对策。
你这个case不错,一起学习,一起进步。
最后我想问下,你的这个block的latency做到5ns,同一款芯片下的其他人的block的latency都得做得和你差不多才行吧。那他们是怎么做?
是个chip,不是block,都是我一个人在做。痛苦的一逼......
不错啊,一个人做,那钱都都你一个人拿了。好差事。
mark 一下,慢慢研究
i学习下
common path 设长点,可以减小derating的影响
我想说针对这样的design,clock 用FB将是明智的选择呀!
mark.
具体怎么实现呢? place之前加用move bound?
FB现在能全自动化吗
markmark
MARK,学习下!