这个语音识别领域最牛的人,这样揭秘深度学习与语音识别
从深度学习角度来讲,我们还有一种编码和解码的方法,第一步由编码完成,第二步用解码完成。我将在这里给你们展示一些细节。这里,你们可以看到一个公式,这是目前的神经网络的第一步用到的,唤醒词Alexa以及它的嵌入(embedding),这些编码描述的是说话者的声音特性。然后是第二步,要识别说话者何时结束,我们依旧用锚点词来定位,也就是当那个人说出"jazz"这个词的时候,就知道这句话已经结束了。虽然周围的声音仍在影响判断,但锚点嵌入(anchor embedding)可以告诉我们:"你需要聆听的那个人在那里。"
我没有进入太多细节,但是你们也许注意到了,幻灯片上有我们已发表的论文信息。不用急着拍照,感兴趣的朋友可以从之后论文中找到你们想要的信息。我还不知道要怎么发送给你们,但有兴趣的话可以之后再问我。
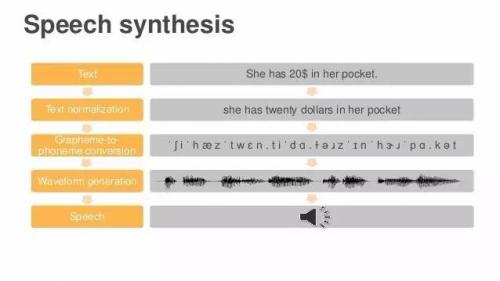
我今天想谈的第二个领域,就是语句合成。现在深度学习用以做很多自然语言处理的工作,今天我主要讲的是语音分析和语句合成。我认为Alexa目前做得很不错,我们还将在这两个领域投入更多资源。
我将以为大家演示一遍问题来结束。这里有一些文本,你希望Alexa说出它们--这是语音识别最后一步的倒序做法。我们将这些文本转化为字素,没有美元符号之类的任何符号,只有单词。然后再将字素转化为音素,由音标组成。现在文本变成了一堆音标,我们没法读出来,但是系统将读出来,这是最难的一步,将字串变为波形,成为真实可听的声音。来,请听--"她口袋里有20美元(She has 20 dollars in her pocket)。"哇,还真读出来了,不错,这就是Alexa的工作方式。
下面我要说说Alexa是怎么做到的。大部分高端系统是这样做的:找一个专业配音员,录下数小时他或她自然发音的音频,就得到了一个巨大的数据库。然后将所有片段和成分都进行标注,然而过程中会产生很多问题--哪里是高音?发音多长?这个音从哪个词发出的?对应的音标是什么?等等。收集到的音素会进入数据库,经过搜索最近似发音后,重组成一句连贯的语句,听起来就像一个人自然而然说出来的。

被切割的片段被称为"双连音片段"(Di-phone segment)

数据库里的音频有三个属性:音高(pitch)、时长(duration)、密度(intensity)
这个技术在业内已经被用了很久了,我想说的是我们的创新,即,交给深度学习来做这些事。比如现在你有一些音素和想说的词汇,你想找出数据库中符合的目标。例如在某个特定语境下,你希望最后发出的声音,音高达到120赫兹,时长达50毫秒,你只要直接搜索数据库中这种类型的片段,就可以合成出你想要的语句了。


- 传感器让植物“开口”,渴了冷了全知道(11-15)
- iKair转型传感器厂商发布Maxense 撬动物联硬件领域(05-29)
- Fairchild FIS1100评估套件登陆Mouser,内置全球首款高精度、低功耗MEMS IMU(07-07)
- 投资者最喜欢这样的传感器和人工智能项目(02-24)
- Touch Taiwan 2016智慧显示与触控展览会(07-19)
- AI全面超越人类还需多少年?352名专家这样预测的(05-02)