一种面向云架构的高性能网络接口实现技术
3对比实验及结果分析
3. 1实验一
实验环境描述如下:一台数据包发生器,最大可产生流量为80Mpps的64字节的数据包。一台服务器配置Intel的Sandy Bridge 8核处理器,每个核心2.0GHZ.操作系统采用RedHat Enterprise Linux 6.2.网卡采用Intel 82599 10G以太网控制器。运行的软件包含三个线程,一个收包线程,一个转发线程,一个发送线程。传统网络实现方式下采用了RAWSocket方式直接收发处理层二数据包,如图4所示。
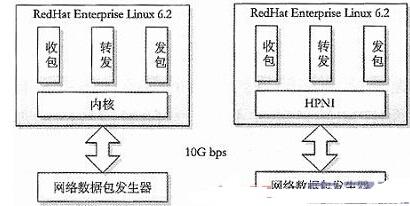
图4 单线程模式下性能比较图
实验结果如图5所示,可以得出传统网络接口实现模式下性能的峰值在180Kpps左右,而且随着网络数据流量的增大,性能呈现下降趋势,主要因为随着网络流量的增加,额外的系统开销也在不断增加。HPNI模式下性能峰值在1.8Mpps左右,而且随着网络流量的增加,性能比较稳定,抗冲击力比较强。
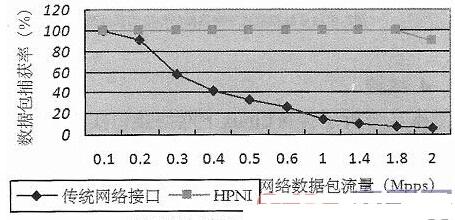
图5 单线程模式下性能测试结果
3.2实验二
采用与实验一相同的硬件环境,同时开启多个相同的任务线程,每个线程在一个任务循环内完成收包、改包、发包的工作,比较两种接口模式在多核多任务配置下的性能。另外,在HPNI模式下同时使能网卡的RSS功能,生成多个队列分别对应每个任务线程,每个任务线程静态绑定一个CPU核心,如图6所示。

图6 多核多线程模式下网络接口性能分析
实验结果如图7所示,在传统网络接口实现模式下,因为受限于Linux内核处理的瓶颈,即使采用了多线程并发,其性能峰值仍然处于180Kpps左右。HPNI却能很好地利用多线程的并发,在网卡RSS功能的配合之下性能得到成倍的提高。也可以看到多核下面HPNI的性能并不是一直随着核数的增加而线性增加的,主要因为CPU内的核心之间并不是完全独立的,它们之间也存在一些共享资源的竞争,比如总线的访问,从而对性能产生一些负面的影响。
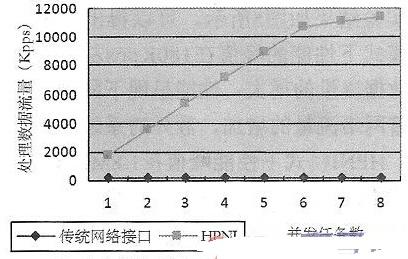
图7 多核多线程模式下网络接口性能测试结果
4结语
本文分析了传统Linux下网络接口实现的性能瓶颈,针对其不足提出了一种新型的网络接口实现模式。实验结果表明,HPNI可以达到12Mpps的包转发速率,完全可以胜任核心路由网络以外网络聚合点的工作,比如小型企业网关等。另外,因为HPNI的容量可以动态调整,因此可以以较高的性价比实现各种性能要求的网络转发节点。基于通用处理器和标准操作系统的特性,也使得HPNI能够快速地部署到SDN中。HPNI既可以直接部署在IT server上,也可以部署在虚拟机当中,从而实现高速NFV的功能。当然,HPNI也存在一点不足,因为采用了轮询模式,虽然保证了数据处理的实时性,但也导致了较大的CPU负载,当网络流量很低的时候,系统资源利用率不是很高。后续可以针对此点做一些优化,比如结合机器学习算法对输入数据流量进行预测,当输入流量降低时通过CPU提供的pause指令降低CPU负载,从而降低系统资源的使用。
云架构 CPU Linux 网络接口实现 HPNI 相关文章:
- 意法半导体之宽带多媒体解决方案(01-12)
- 蓝牙技术硬件实现模式分析(01-11)
- 关于计算机接口(04-16)
- PC电源常见故障判断分析与排除 (04-16)
- 采用软处理器IP规避器件过时的挑战(05-04)
- 在Windows Vista中提高SATA硬盘性能(06-12)