一种面向云架构的高性能网络接口实现技术
在绝大多数情况下,应用程序并不直接通过物理内存地址来访问内存,而是采用虚拟地址,当CPU收到内存访问指令时会先把虚拟地址转换成实际的物理地址,然后进行内存的访问操作。这种方式已经被普遍接受,甚至被称作是IT时代最杰出的发明之一,但是这种非直接内存访问方式并不是没有代价的,地址的翻译需要通过页表来完成,页表通常情况下是储存在内存当中的,访问速度很慢,为了解决这个问题,大部分系统都采用了TLB(Tralaslation Lookaside Buffer)的方式,最近触发的一些地址翻译结果都会保存在TLB中,TLB实际上使用的是CPU的缓存(cache),访问速度非常快,然而cache容量小,只有最近访问的一部分页表项能保存下来,因此出现了"TLB Miss";当CPU发现当前虚拟地址无法在TLB里面找到相对应的表项时,就引入了一个TLB Miss,此时CPU需要回到内存当中的页表进行查找,性能会显著降低。因此当程序需要进行频繁的内存操作时,需要尽量减少TLBMiss的次数。当前系统定义的页面大小一般是4k字节,当应用程序使用比如2G这样的大内存时,总共需要50多万个页表项,这个数目是相当庞大的,同时因为只有一小部分的表项能够装载在TLB中,因此TLB Miss的几率也很大。另外,一般情况下程序的虚拟内存空间都是连续的,但其对应的物理内存空间却不一定是连续的,这样会导致一次虚拟内存寻址操作可能需要进行多次物理内存寻址操作才能完成,这也会成倍地增加内存访问消耗的时间。
1.3多核亲和力
多核系统对提高系统的性能有很大的帮助,当前大部分系统的调度算法会把当前的任务放到最空闲的核上执行,这样的好处是能够增加CPU资源的利用率,但因为每个CPU核心都有自己独立的寄存器和cache,当任务从一个核心迁移到另一个核心时,会引发大量的核问切换开销,比如上下文切换,cache miss等等。另外,对于使用NUMA(Non-Uniform Memory Access)架构的系统而言,核间切换的开销会更大,在SMP(Svmmetric Multiprocessing)架构下,所有核心是通过共享接口访问内存的,因此每个核心访问内存的速度是一样的,但在NUMA架构下,核心对内存的访问分为本地访问和远程访问。核心访问本地内存的速度要比访问远端内存的速度快很多,当任务从核心A切换到核心B的时候,如果它仍然使用之前在A上分配的内存,那么其内存访问模式会从本地模式切换成远程模式,从而引起内存访问速度的下降。
1.4共享队列的访问
当把数据包从一个任务传递到另外一个任务的时候,需要用到共享队列。通常情况下,在访问共享队列的时候会用到Mutex锁来保证访问的一致性。当应用程序申请Mutex锁失败之后会陷入内核态中睡眠,当锁可用之后再从内核态切换到用户态执行,这里也引入了上下文切换的开销,而且当数据流量很大的时候,相应的开销也会非常大。为了消除这类开销,业界也提出了一些改进的方法,比如自旋锁(spinlock),自旋锁一直在用户态运行,不会陷入内核态中,因此也不会产生上下文切换的开销,但是它还是存在一些弊端:一方面可能造成死锁,如果一个线程拿到锁之后被意外销毁,其它等待此锁的线程会发生死锁;另一方面,当共享队列和线程数量猛增时,锁的数量也会同时增加,对锁的管理会给系统带来很大的负担。
2 HPNI实现原理
2.1传统网络接口实现模式的不足
从上述分析可以得出传统网络接口的实现主要有以下几点不足:
(1)上下文切换开销太多,这些开销主要是由中断、系统调用、锁以及核间切换引入;
(2)内存拷贝的开销太多;
(3)内存访问效率不高,缺乏相应的优化;
(4)采用带锁共享队列进行数据共享,引入额外开销;
(5)收发包操作必须经过Linux内核单线程完成,无法扩展成多核多线程模式从而提高性能。
2. 2 HPNI的原理
针对上述不足,提出了一种新型的网络接口实现模式,如图3所示。
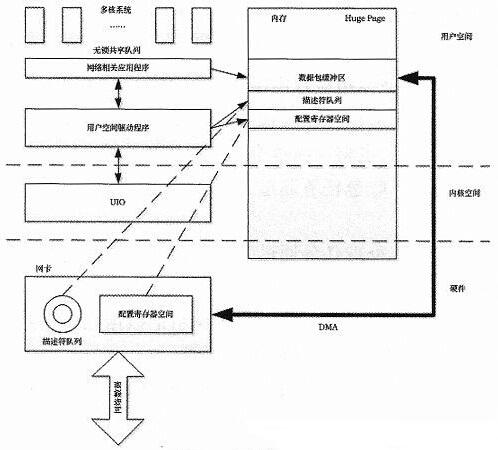
图3 HPNI网络接口实现
HPNI主要包括以下几项关键技术:
(1)通过Linux提供的UIO框架,实现了网卡用户空间驱动程序,UIO能够把网卡设备内存空间通过文件系统的方式传递给用户空间,比如dev/uioXX,因此用户空间程序能够读取到设备地址段并映射到用户空间内存中,比如通过mmap()。通过上述方式可以在用户空间程序中完成驱动程序的功能。这种方法的优点是去掉了内存拷贝,同时因为所有工作都在用户空间完成,也节省了系统调用的开销。
(2)关掉网卡中断,驱动程序采用轮询方式,消除中断引起的开销。
(3)用户空间的数据包缓冲区采用huge page分配的连续物理内存区,通过LinuX提供的huge page接口能够分配大于4k的页,从而减少页表的大小,降低TLB Miss发生的概率。另外连续的物理内存块也能减少地址转换引起的查表次数,进一步提高性能。
(4)任务线程和CPU核心之间采用静态绑定,比如接收包线程绑定1核,处理包线程绑定2核,发送包线程绑定3核,从而消除核间切换产生的开销。
另外,对于NUMA架构的CPU,每个任务都使用本地内存,进一步提高内存访问速度。
(5)通过CAS(Compare And Swap)原子操作,多个任务可以在不加锁的情况下对共享队列进行访问,增加和删除节点。在X86架构下CAS是通过CMPXCHG指令实现的,该指令的作用就是把一个指针指向内存的值同一个给定的值进行比较,如果相等,就对对应内存赋一个新的值,否则不做任何操作。通过上述方法可以实现一种冲突检测机制,当任务发现该队列己经被访问时,主动等待直到队列空闲。无锁队列消除了加锁引起的开销,同时也能避免死锁的情况。
(6)基于网卡RSS(Receive-side Scaling)功能可以平滑扩展成多任务模式,RSS功能可以将收到的数据包基于五元组做哈希运算,从而分发到不同的队列当中进行并行处理,每一个队列可以对应一个收包任务,从而成倍地提高处理性能。
云架构 CPU Linux 网络接口实现 HPNI 相关文章:
- 意法半导体之宽带多媒体解决方案(01-12)
- 蓝牙技术硬件实现模式分析(01-11)
- 关于计算机接口(04-16)
- PC电源常见故障判断分析与排除 (04-16)
- 采用软处理器IP规避器件过时的挑战(05-04)
- 在Windows Vista中提高SATA硬盘性能(06-12)