在蜂窝式无线电基础架构中实现软件可编程数字预失真
蜂窝网络运营商正努力通过使用最新空中接口、采用最新传输频率、提高带宽以及增加天线数量和蜂窝基站数量的方式提高网络容量,为此他们需要大量削减设备成本。此外,运营商们还要提高设备效率和网络集成度,以便减少运营成本。为了提供可满足这些不同需求的设备,无线基础设施设备制造商正在寻找具备更高集成度、性能和灵活性且功耗与成本更低的解决方案。另外,设备制造商在实现以上目标的同时还要缩短产品上市时间。
减少设备总体成本的关键是集成,但减少运营成本则需要采用高级数字算法来改善功率放大器效率。其中最常用的一种算法就是数字预失真(DPD)。在设备配置变得越发复杂的同时提高设备效率,这本身就是一种挑战。无线电传输带宽凭借先进的长期演进(LTE-A)技术正在接近100MHz,而且随着厂商试图在一个非连续频谱中采用多个空中接口,这一数字甚至会更高。同时有源天线阵列(AAA)和支持MIMO的远端射频单元(RRU)也不断对算法的计算带宽提出更高要求。本文我们将研究如何利用Zynq-7000 All Programmable SoC(AP SoC)来提高当前及未来DPD系统的性能,同时为设备厂商提供具有完全可编程功能的低成本、低功耗解决方案,帮助他们以最快的速度向市场推出产品。
实现蜂窝无线电
AP SoC采用包含串行收发器(SERDES)和DSP模块的高性能可编程逻辑(PL)架构和一个与其紧密集成的硬化处理子系统(PS)。该处理子系统又包含一个双核ARM Cortex A9、浮点单元(FPU)和NEON媒体加速器,并配有实现完整无线电操作和控制所必需的UART、SPI、I2C、以太网和存储控制器等多种外设。与外部通用处理器或DSP处理器不同,由于PL与PS之间有大量的连接,因此其间的接口需要极高的带宽,这是单个解决方案所无法实现的。凭借这些软/硬件组合,AP SoC器件能够在单个芯片上实现RRU所需的全部功能,如图1所示。

PL中丰富的DSP资源可用于实现数字上变频(DUC)、数字下变频(DDC)、峰值因数降低(CFR)和DPD等数字信号处理功能。此外,SERDES能够支持9.8Gbps CPRI和12.5Gbps JESD204B接口,分别用于连接基带转换器和数字转换器。PS支持对称多处理(SMP)和非对称多处理(AMP)。在本案例中,假设采用AMP模式,其中的一个ARM A9处理器用于实现下传消息、调度、校准和警报等板级控制功能,用以运行裸金属架构,更可能的是Linux等操作系统。而另一个处理器则用于实现部分所需的DPD算法,因为并非算法的所有部分都支持纯硬件解决方案。
DPD可通过扩大线性范围来提高功率放大器效率。加强对放大器的驱动以改善输出功率,从而提高效率,同时静态功耗保持相对不变。为了扩大线性范围,DPD利用放大器的模拟反馈路径以及大量信号处理操作来计算系数(该系数为放大器非线性的倒数);然后利用这些系数对所发送的功率放大器驱动信号进行预修正,最终达到扩大放大器线性范围的目的。
DPD算法可分解为如下多个功能块,如图2所示。

DPD是一个闭环系统,可捕捉之前发送的信号,以确定放大器根据发送信号所表现出的行为。DPD的首个任务是在校准模块(alignment block)中将放大器的输出与之前的发送信号进行校准。在开始任何后续算法操作之前,需要利用存储器来校准数据。一旦数据校准后,就可用自相关矩阵计算(AMC)和系数计算(CC)算法来创建代表PA非线性倒数近似值的系数;获得系数后,数据路径预失真器会利用这些数据对发送到PA的信号进行预修正。
加速DPD系数估算
这些功能可以通过多种不同方式来实现。有的功能适合用软件,有的则适合用硬件,还有的则既可用软件也可用硬件来实现,但最终还是由性能来决定采用何种实现方式。有了AP SoC器件,设计人员就可自主决定采用硬件还是软件来实现功能。对于DPD算法而言,包含高速滤波功能的数据路径预失真器由于需要极高的采样率,一般应在PL中实现,而用于生成DPD系数的校准引擎与估算引擎则可以在PS中的ARM A9上运行。
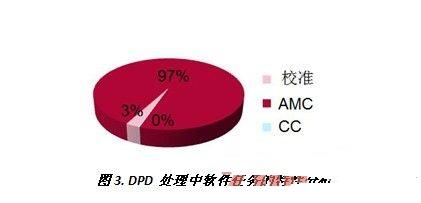
为了确定到底用软件还是硬件来实现功能,必须首先对软件进行特性分析,确定其耗时情况。图3显示了图2中DPD算法用于实现三个可识别功能的软件特性。根据分析结果显示,赛灵思DPD算法中97%的时间都用于AMC处理,因此首先对该功能进行加速意义最大。
ARM A9可用于执行一些附加功能,这样也有助于提高这类应用的性能。例如,作为PS的一部分,每个ARM A9都有一个浮点单元和一个NEON媒体加速器。NEON单元是一种128位单指令多数据(SIMD)矢量协处理器,可同时执行两个32x32b乘法运算,非常适合以乘法累加(MAC)运算为主的AMC功能的要求。充分利用NEON模块,就能发挥软件的内在优势,从而无需用汇编语言进行低层次编程。
因此,相对采用Microblaze或外部DSP等软处理器而言,使用PS中的附加功能可以显著提高性能。
为了进一步提高DPD性能,最好将这些功能移植到采用PL的硬件内。然而软件由C或C++编写,要将C或C++转换为能够在采用VHDL或Verilog语言的PL中运行的硬件内,需要花费一些时间。
随着高层次综合(HLS)工具(例如C-to-RTL)的推出,这个问题现在已经得到解决。这些工具让有C/C++编程经验的程序员能够以FPGA的形式进行硬件转换。Vivado HLS工具使设计人员和系统架构师可以轻松将C/C++代码映射到可编程逻辑,以实现代码重用、尽可能移植以及简单的设计空间探索机制,从而最大限度地提高生产力。
- GPRS与CDPD的技术比较(03-02)
- CDPD(蜂窝数字分组数据网)技术(03-08)
- 赛灵思和AXIS共同发布新型集成射频卡开发平台(11-20)
- 一种高效新型WCDMA 直放站PA 方案的设计与实现(02-28)
- TI GC5322 在CDMA中的应用(08-13)