基于语音识别的IVR系统的设计与实现
时间:02-14
来源:21IC
点击:
1 引言
IVR系统(Interactive Voice Response),即交互式语音应答系统,它被应用于呼叫中心(Call Center),以提高呼叫服务的质量、减轻服务员的工作强度并节省费用,是呼叫中心实现人机交互的重要门户,在传统的IVR系统中,用户与系统交互的方式是通过电话的键盘。通常,用户在进入IVR系统后,会听到相关的语音提示选单,根据自己的需要可以按下键盘上相关的按键。系统通过DTMF信号传送用户按下的键,同时也将用户的请求传送给系统,从而触发相关的语音信息。然而,传统的电话仅能通过DTMF信号,传送有限的几个数字及符号按键。这使得用户与系统的交互界面受到很大的限制,同时也就使得IVR系统的信息查询范围变得相当狭窄,用户在实际使用时会感到诸多不便。
随着计算机技术和人工智能总体技术的发展,自然语言理解不断取得进展。语音识别系统已成为一个越来越广泛的应用方向。由于电话网络的普及性,自然语言处理系统在电话信道上的应用已成为最重要的应用之一。而且随着移动通信技术的发展和人们对于信息获取的移动性的需求不断增加,市场对于电话语音识别系统的需求也不断的增加。因此在新一代呼叫中心的IVR系统中引入了语音识别技术作为用户的输入手段,用户可以直接用语音与系统进行交互,这样大大提高了工作效率。
2 系统流程及主要模块
本系统目标是支持多用户并发查询车辆违章信息和驾驶证信息。用户使用自然的语言说出需查询信息的类别和车牌号码,系统识别后将识别结果反馈给用户,经用户确认后,系统把识别结果作为后台数据库查询的关键字进行查询,并将查询结果播放给用户。其流程见图1。本系统主要包括以下几个模块:
话路处理模块:以并发的方式控制和管理各电话话路。
语音识别模块:负责查询类别和车牌号码的识别。
后台数据库查询模块:将语音识别的结果作为数据库查询的关键字进行查询。
IVR系统(Interactive Voice Response),即交互式语音应答系统,它被应用于呼叫中心(Call Center),以提高呼叫服务的质量、减轻服务员的工作强度并节省费用,是呼叫中心实现人机交互的重要门户,在传统的IVR系统中,用户与系统交互的方式是通过电话的键盘。通常,用户在进入IVR系统后,会听到相关的语音提示选单,根据自己的需要可以按下键盘上相关的按键。系统通过DTMF信号传送用户按下的键,同时也将用户的请求传送给系统,从而触发相关的语音信息。然而,传统的电话仅能通过DTMF信号,传送有限的几个数字及符号按键。这使得用户与系统的交互界面受到很大的限制,同时也就使得IVR系统的信息查询范围变得相当狭窄,用户在实际使用时会感到诸多不便。
随着计算机技术和人工智能总体技术的发展,自然语言理解不断取得进展。语音识别系统已成为一个越来越广泛的应用方向。由于电话网络的普及性,自然语言处理系统在电话信道上的应用已成为最重要的应用之一。而且随着移动通信技术的发展和人们对于信息获取的移动性的需求不断增加,市场对于电话语音识别系统的需求也不断的增加。因此在新一代呼叫中心的IVR系统中引入了语音识别技术作为用户的输入手段,用户可以直接用语音与系统进行交互,这样大大提高了工作效率。
2 系统流程及主要模块
本系统目标是支持多用户并发查询车辆违章信息和驾驶证信息。用户使用自然的语言说出需查询信息的类别和车牌号码,系统识别后将识别结果反馈给用户,经用户确认后,系统把识别结果作为后台数据库查询的关键字进行查询,并将查询结果播放给用户。其流程见图1。本系统主要包括以下几个模块:
话路处理模块:以并发的方式控制和管理各电话话路。
语音识别模块:负责查询类别和车牌号码的识别。
后台数据库查询模块:将语音识别的结果作为数据库查询的关键字进行查询。
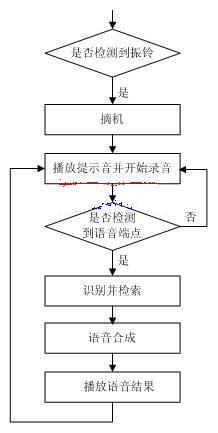
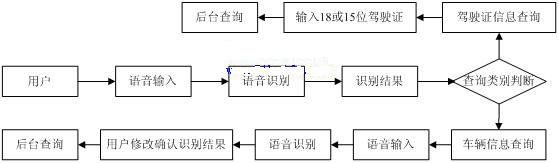 图1 车辆违章信息和驾驶证信息查询系统流程图 3 话路处理模块的实现 本系统的硬件部分是由电话语音卡和一台PC机组成,语音卡通过其提供的语音处理和信令处理能力,来实现用户的接入请求和挂机信号的检测,并负责录音和回放语音。本系统采用的是东进D161A语音卡。该语音卡可接入16条模拟电话线,提供16路以内的话路并行处理能力。其主要功能有:(1)自动增益控制及语音信号的压扩变换;(2)采集和播放各种格式的电话语音信号,实现A律PCM、μ律PCM、ADPCM等算法;(3)辨识和产生DTMF信号;(4)ITU-TSS G3传真功能。 话路处理的主要任务是电话振铃检测,播放系统提示语音信息,接受用户的按键请求和语音请求,与后台数据库模块通讯,检索结果的语音合成和播放。整个模块有点类似于一个有限状态机,在程序设计时要跟踪系统所处的状态进行相应的动作,并进入下一个状态,其程序流程如图2所示。 本系统话路处理模块的关键部分是语音数据的实时采集。东进语音卡在这方面提供了一系列接口函数,如:StartRecordFile、StartRecordFileNew、VR_StartRecord等。这几个函数都能够实现对通道的录音,所不同的是前两个函数将语音数据保存到磁盘文件,后一个函数则将语音数据保存到存储器缓冲区。由于我们要实现的是一个实时语音识别系统,因此我们采用后者来采集语音数据。在开始录音之前,我们首先调用VR_SetEcrMode函数启动回声抑制功能,然后每隔一段时间调用一次VR_GetRecordData函数取得录音数据,并将其送入语音识别引擎。当语音识别引擎有识别结果返回时,停止录音,并根据识别结果转入下一个状态。
|
- 基于IXP421的VoIP网关及其性能测评(10-02)
- STP在未来通信网中的发展(01-12)
- 蓝牙技术硬件实现模式分析(01-11)
- 网络接入技术中光纤网络名词解释(08-28)
- 相变存储器(PCM)技术基础(10-24)