AVS 运动补偿电路的VLSI 设计与实现
摘要:
提出了一种基于AVS |0">AVS 标准的高效的运动补偿电路硬件结构, 该设计采用了8 ×8 块级流水线操作, 运动矢量归一化处理和插值滤波器组保证了流水线的高效运行以及硬件资源的最优利用。采用Verilog 语言完成了VLSI |0">VLSI 设计, 并通过EDA 软件给出仿真和综合结果。
关键词:
运动补偿; 流水线; AVS
0 引言
AVS 标准是数字音视频编解码技术标准工作组(AVS 工作组) 制定的数字音视频编码标准,其视频部分已于2006 年2 月份被信产部颁布为国家标准,于2006 年3 月1 日起实施。该标准主要面向高清晰度和高质量数字电视广播、数字存储媒体和其他相关应用。
运动估计和运动补偿是AVS 中去除时间冗余的主要方法,它采用多种宏块划分方式,1P4 像素插值、双向估计和多参考帧等技术大大提高了编码效率,但同时也给编解码器增加了一定的复杂度。本文针对AVS 所特有的运动补偿解码过程进行深入分析,并提出了与其算法相适应的运动补偿电路的设计方案,电路采用Verilog 语言描述,并给出了综合和仿真的结果。
1 AVS 运动补偿关键技术分析研究
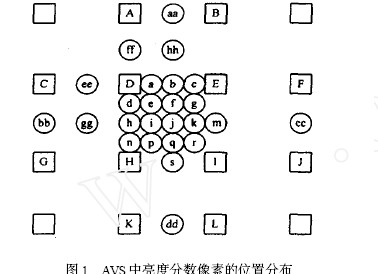
与其他视频编解码算法相类似,AVS 的运动补偿技术主要涉及三个步骤:通过比特流中的相关信息计算运动矢量、按照运动矢量的指示进行地址转换从MIU 中读取参考像素值、通过参考像素值对当前解码块进行预测。同时,作为一种高效率的视频压缩算法,AVS 也有其独特的技术特征。
AVS 共有4 种宏块划分类型:16 ×16 ,16 ×8 ,8 ×16和8 ×8 ,比MPEG- 2 增加了8 ×8 大小块的运动估计,但并未像H. 264 一样进行更细一级到4x4 块的划分;同时AVS 支持的最大参考帧数为2 帧,而不是MPEG- 4PH. 264 的16 帧,这些都使得AVS 既保证了一定的数据压缩率,又控制了运算复杂度。
AVS 充分利用了图像的运动连续性,对双向预测分两种模式进行处理:对称模式和直接模式。在对称模式中,前向矢量由当前图像中空间相邻块的运动矢量获得,而后向运动矢量由前向运动矢量通过一定的对称规则获得,从而节省了后向运动矢量的编码开销;在直接模式中,前向和后向运动矢量都是由后向参考图像中相应位置的时间相邻块的运动矢量获得,不需要传送运动矢量差值,从而也提高了编码效率。
 |
2 AVS 运动补偿处理器的VLSI 结构设计
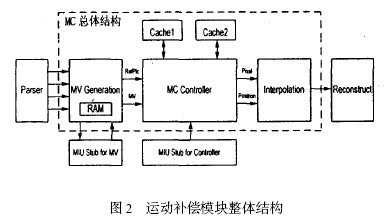
2. 1 运动补偿处理器整体结构
分析AVS 的解码算法,其运动矢量的计算,参考像素的读取以及插值的计算三个部分计算量相当,于是该运动补偿结构相应的包括三个主要功能模块:MV Generation ,MC Controller 和Interpolation ,整个解码器通过三个模块的并行流水操作完成,从而实现了高清图像的实时解码。其中,MV Generation 根据Parser 解出的宏块信息来产生运动补偿过程所需要的运动矢量;MC Controller 根据得到的运动矢量从参考帧读取相应的参考像素并总体控制运动补偿的进行; Interpolation 完成非整数像素点的插值以及加权平均等一系列后处理操作,并将结果输出给Reconstruct 模块。
 |
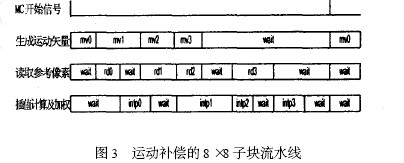
2. 2 MC Controller 的流水控制
在运动补偿过程中,运动矢量的计算,MIU 访问地址的转换以及像素的插值之间具有严格的数据依赖特性,并且,运动矢量的生成时间以及向MIU 响应时间均无法确定,导致运动补偿存在严重的等待问题。如果对每个宏块都依次采用生成运动矢量、读取参考像素、插值计算三个步骤,将会形成非常严重的时钟浪费。
对此本文采用8 ×8 子块级的流水线结构,通过握手机制对运动矢量的生成,参考像素的读取,插值计算和加权进行调度,有效的降低了各模块间因等待造成的时钟浪费。
 |