在基带处理中使用串行RapidIO协议进行DSP互连
非常灵活地适应更高复杂的要求,并且使对等网络通信成为可能,具有更高的吞吐量。
由于这种模块只有 DSP 在运算,需要进行负载均衡,对于处理链中的DSP 簇,需要给每个DSP 分配不同的算法模块。因为需要更高的数据速率并且需要更复杂的多用户运算,进行信道估计和检测,需要用多个DSP 对这些运算进行负载均衡,从而去实现更大的算法模块。比如说可以给每个DSP 相同的算法,也可以让每个DSP 本身成为一个独立的算法模块,这些都是非常灵活的。
2. 系统的具体实现
DSP 之间通过RapidIO 协议进行通信的实现方法,目前可以通过FPGA 实现,FPGA 作为DSP 节点本地互连网络协处理器,采用了分层结构,包括DSP 接口层、RapidIO 的逻辑层、运输层和物理层[4].DSP 通过外部存储器接口( EMIF) 和FPGA 相连。但是这种方法需要在FPGA 内部进行比较复杂的互连。目前,TUNDRA 公司推出了一款专门的串行RapidIO芯片--TSI568A.
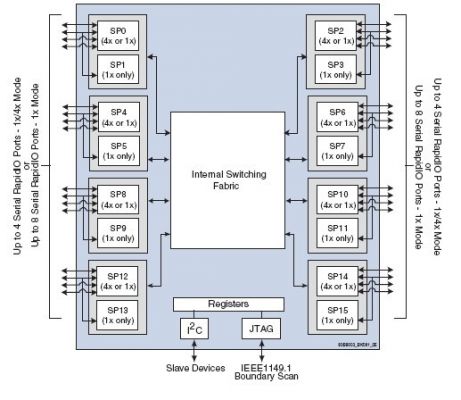
图 3 Tsi568a 的内部结构。
Tsi568A 是一款业内最先进的串行RapidIO 交换机,支持高达每秒80GB 的总带宽。它高度的灵活性可以满足多个I/O 设备的带宽要求,每个端口可以配置成4x 模式或者1x 模式,这样可以为多个DSP 连接提供接口。Tsi568A 还支持RapidFabric 扩展,包括以交互工作和封装为目的的数据流分组交换。而且Tsi568a 支持热插拔I/O 设备。同时,TI 公司的TMS320C6455 系列DSP 也集成了串行RapidIO 接口,这样就可以实现DSP 簇之间进行无缝的串行RapidIO 通信。
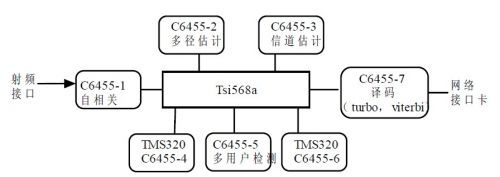
图 4 互连的实现。
如图 3 所示接收端基带处理。自相关和多径估计由DSP1 和DSP2 中完成,信道估计和多用户检测由DSP3 和DSP5 完成,QPSK 和MRC 也由DSP5 处理,turbo 译码和viterbi 译码由DSP7 完成。还可以看出,给DSP4 和DSP6 并没有使用,这时候它们可以进入Power down模式,可以根据需要来决定是否使用某个DSP.
另外,上图只是接收端的基带处理,给每个 DSP 分配不同或者相同的功能,使得DSP处理板还可以在系统的多天线接收板,多天线发送板,基带接收处理板中使用。由于是对等的关系,采用适当的升级可以使发送和接收功能在一块板卡中灵活实现。除了功能上的差别外,不同单板需要的处理能力不同,可以选用不同的DSP 来适应。如果处理能力要求不高,可以选用工作频率较低的6455-720 或者6455-850;如果处理能力要求比较高,则可选用工作频率最高的6455-1000.这种模块处理机制,每个DSP 都执行这一系列信道处理的功能,在某些时候几个DSP 可以进入Power down 模式,TSI568a 也能够中断没有使用的端口以节省功率。而在高通信量的时候可以使能所有的DSP 工作。
借助 Tsi568A 系列交换机,可以通过多种端口带宽和频率选项,可以选择灵活的端口配置各个DSP.系统基于串行RapidIO 规范,拥有多种功能:SerDes、错误恢复、给予优先级的体系路由、高有效载荷和基于表格的体系分组路由。由于拥有广泛缓冲和流量管理架构,可以有效防止线路中枢发生堵塞。Tsi568a 提供了芯片到芯片的互联,因此几个DSP 的数据传输是点到点的。同时,Tsi568A 可以通过区分数据包的优先级来提供流量汇总功能,通过自己的无阻塞体系来提供高性能的对等通讯。通过x4 串行RapidIO 连接,可以具有更高的信道密度,承载更高的吞吐量。
3. 结论
在基站的基带处理结构中灵活使用串行 rapidio 协议,能够减少复杂度,使电路板的设计更加简单,发送和接收功能更加灵活地在一块板卡中实现;并且多个DSP 同时执行并行计算提升了基带处理的能力;允许更灵活的现场切换;弥补了传统互联方案的不足,具有可升级的空间,可以通过软件改进对算法和数据路径进行升级。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)