基于DSP的HPI接口的视频数据传输系统设计
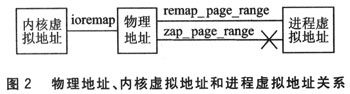
储器管理单元)将内核虚拟地址转换为物理地址。采用虚拟内存技术,每个进程都有互不干涉的虚拟空间。三者直接映射的关系如图2所示,其中内核函数zap_page_range完成去掉物理地址与进程虚拟地址映射关系的功能。
2.1 驱动结构
在Linux中,设备也是作为文件来访问的。VFS(虚拟文件系统)为各种不同的文件系统提供了统一的访问接口,通过这些接口,应用程序可以直接使用open、read和IOctl等系统调用对设备进行访问和控制。
本例中,把HPI作为一个外围设备,其驱动主要实现对设备的打开、关闭、内存映射、视频数据缓冲区管理和物理内存切换等功能。根据原理图,可以确定HPI 四个寄存器对应的物理地址,在驱动初始化过程中,调用ioremap_uncache函数把物理地址映射为内核虚拟地址,在驱动层通过内核虚拟地址访问 HPI的4个寄存器。
存储器映射I/O把HPI驱动分配的数据空间直接映射到应用程序的虚拟地址空间,应用程序直接访问该空间,避免了用read/write系统调用导致的视频数据二次拷贝。在内核里,由驱动分配一定的缓存,当应用程序不能及时处理DSP发送过来的视频数据,可以缓存这些数据;当应用程序处理完一帧图像时,采用Linux的物理内存切换技术,把下一帧数据所在的物理地址重映射到应用程序的同一虚拟地址,这样,应用程序不用频繁调用mmap函数映射内存。
2.2 存储器映射I/O
一般情况下,当应用程序用read/write读写设备数据时,该设备的驱动先将设备数据从设备上采样到内核缓冲区,再从内核缓冲区拷贝到应用程序缓冲区,数据经过了两次拷贝。当数据量比较小时,如一些控制命令或状态信息,对系统性能几乎没有影响。但是,如果一次传输的数据量比较大,比如视频显卡上的实时视频图像,两次拷贝将大大影响系统的数据处理效率。这时,可采用存储器映射I/O技术,在内核层存储器映射I/O由函数 remap_page_range完成。
由remap_page_range函数的原型可以知道,该函数的意义在于通过将特定物理地址映射到进程虚拟地址,进程可以访问特定的物理地址,而这在普通情况下是不可能的。在本例中,当进程调用mmap函数进行存储映射时,内核会调用驱动注册的hpi_mmap函数,传入的参数之一包括进程虚拟地址。在 hpi_mmap函数里,调用remap_page_range完成从缓冲区物理地址到进程虚拟地址的映射。hpi_mmap函数实现如下:

其中vm_flags字段设置了VM_RESERVED,表示该数据缓冲区一直常驻内存,在内存不足时,不会被交换出去。内核和进程同时对数据缓冲区读写,为了保证数据的一致性,对该区域的访问不应该经过CPU内部的缓冲区,所以用pgprot_noncached设置非缓冲标志。
mmap系统调用返回一个进程虚拟地址,该地址就是vma->vm_start字段,进程对该虚拟地址的访问,最终变为对物理地址CACHE_PHY的访问。
2.3 数据缓冲管理
缓冲管理的主要任务是,当ARM接收到新的一帧时,为其分配相应的缓存,并将在物理地址重映射到进程虚拟地址。当应用程序处理该帧时,缓冲管理负责内存区域的回收。
当Linux内核启动时,可以传人参数mem=PHY_LEN,指定存储空间的大小。在本例中,内核启动时为HPI驱动预留8 MB的高端物理内存。在本例中,借助Linux中对普通外设I/O内存(PCI卡内存等)管理的思想,用高度为2的树表示一块连续的区域。该数据结构的优点在于,资源分配简单,把离散的小内存合并为一块连续的大缓冲区的算法复杂度为O(1)。具体实现请参阅内核源码中resource结构相关部分。
重映射新一帧视频数据到进程虚拟地址是缓冲管理的另一任务。因为前一帧数据物理地址已经映射到进程虚拟地址,需要先将前帧物理地址与进程虚拟地址的映射关系去掉,然后重映射当前帧数据到进程虚拟地址。去掉物理地址与进程虚拟地址的映射关系由内核函数zap_page_range完成,调用该函数后,如果进程再访问该虚拟地址,内核会产生缺页中断。这时再用remap_page_range建立当前帧数据物理地址与进程虚拟地址间的映射关系,进程就可以通过同一虚拟地址访问当前帧的数据了。该方法的意义在于,进程不用频繁调用mmap建立物理地址与虚拟地址的映射,只用调用一次,当有新数据到达时,驱动自动将新帧数据映射到先前的进程虚拟地址,提高了进程处理视频数据的效率。实现代码如下:

结 语
在当前视频处理平台上,视频处理、视频传输、复杂任务管理等工作一般都是由一块DSP处理器单独完成,结合其他嵌入式微处理器协同工作的技术方案刚刚起步。经测试,在基于本文提出的高速通信方法设计的视频处理平台上,TMS320DM642与AT9lRM9200间的通信速率可以达到50 Mbps,带宽足够用来传输MPEG等压缩视频数据。如果用HPl32模式,速度还会大幅度提高。同时,因为Linux系统的实时性不是很强,如果采用其他实时性强的操作系统,如Vxworks等,系统性能还会有大的提高。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)