DSP嵌入式说话人识别系统的设计与实现
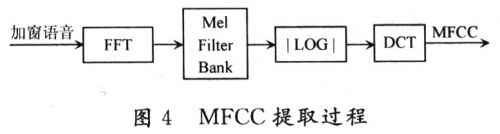
知的非线性特性。在DSP硬件资源配置中,MFCC在识别性能和DSP内部空间占用方面也取得了很好的平衡。在该系统中使用16个滤波器(M=16)构成的滤波器组。图4所示是MFCC的提取过程。
2.3 识别方法选择与实现
基于该系统对速度、识别效率、存储空间的要求,这里的识别方法选为高斯混合模型。高斯混合模型(GMM)可以看成是状态数为1的连续分布隐马可夫模型CDHMM。一个M阶混合高斯模型的概率密度函数是由M个高斯概率密度函数加权求和得到,所示如下:
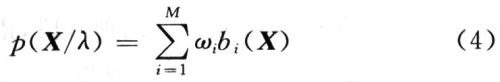
式中:X是一个D维随机向量;bi(Xi)是子分布,i=1,2,…,M是子分布;ωi是混合权重,i=1,2,…,M。对GMM模型参数的估计方法该系统采用最大似然估计。对于一组长度为T的训练矢量序列X={X1,X2,…,XT},GMM的似然度可表示为:
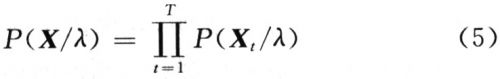
由于式(5)是参数λ的非线性函数,很难直接求出其最大值。因此,该系统采用EM算法估计参数λ。
2.4 算法实现过程中的具体考虑.
(1)FFT变换点数的选择。FFT变换点数选择很重要,如果选择太大,则运算复杂度变大,使系统响应时间变长,如果选择太小则可能造成频率分辨率过低,提取参数误差过大。该系统中选取的点数为240点。
(2)模型参数的选择。首先模型阶数M必须适中,必须足够大,可以充分表示出空间的分布。然而,阶数也不能太大,否则数据数量不足,也无法准确描述特征空间分布。考虑该系统对参数的存储空间要求,并综合以上考虑,该系统选用的阶数为32阶。
(3)协方差矩阵类型。考虑到减少计算量,这里采用对角阵。在高维特征空间中,对角阵比全矩阵优势更为明显。
(4)方差限定。当训练数据不足或者是存在噪声干扰时,方差幅度会很小,这样会导致模型概率函数的奇异性,所以每次EM迭代时,都需要对方差进行限定。即:
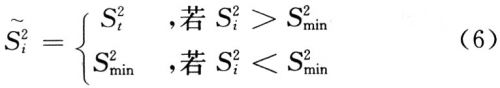
根据实验结果,该系统选取S2 min为0.025
(4)模型初值的设定:EM算法是寻找局部最大概率的模型。不同的初值会导致不同的局部极值。该系统中采用的是K均值法。
2.5 K均值法应注意的几个问题
(1)聚类中心的初始化。对于聚类中心数目由GMM模型决定,假设是N。对于聚类中心的初始化,一般取前N个矢量作为聚类中心,但在实验过程中发现,这种方法不具有针对性,往往设立的初始的聚类中心不具有很好的聚类效果。所以这里采用取质心法。具体方法为:
第一步先求出训练集S中全体矢量X的质心,然后在S中找出一个与此质心的畸变量最大的矢量Xj,再在S中找到一个与Xj的畸变量最大的矢量Xk。以Xj和Xk为基准进行胞腔划分,得到Sk和Sj两个子集。对这两个子集分别按照同样的方法划分得到4个子集。依次类推,得到N个子集。这N个子集的质心即为初始的聚类中心。
(2)聚类中心改进量δ的选择。对于聚类中心改进量δ的选择,若选择太大,则聚类不充分,影响训练效果;若太小,则会导致训练无法完成,该系统通过试验,取比较适中的数0.01。
(3)最大迭代次数的选择。对于最大迭代次数的选择,太小会导致误判,太大导致训练不成功时过多的占用系统时间。该系统迭代次数设为100,比较适中。
3 实验结果及改进点
通过系统调试及改进,该系统最终实现10个说话人的身份识别,并自举运行。运行时通过Switch组合可方便的选择训练或识别的功能,并可更新说话人。训练,识别的进度及结果通过LED组合显示。利用该系统对5男5女10个人进行训练,每人500次测试,结果正确识别率为98%,识别时间为3 s左右。说明该系统可以有效的识别说话人的身份。对于该系统,识别时间及识别率上还有改进空间,以后工作可围绕识别时间上改进。
发布者:小宇
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)