迎合三重播放业务时代需要的基础局端 DSP
时间:01-28
来源:
点击:
语音/数据/媒体网络的兴起要求高性能与高速 IO 完美结合。本文将探讨如何选择可满足上述要求的 DSP,为引导系统提供低成本解决方案。
多媒体内容随着总流量的增长而变得日益丰富,这为设备制造商带来了前所未有的工程设计挑战与机遇。他们必须制造出新一代能够处理持续急速上升的汇聚流量的设备,该汇聚流量基本不同于过去主导基础局端设计范例的语音与数据流量。
这种变革是上个世纪 70 年代计算机革命以来的多重趋势引发的:
* 从纯语音流量到语音与数据流量的转变。这一趋势在数十年前就已开始了,现在仍在继续。
* 多媒体流量,特别是流媒体,加入现有的语音与数据流量。电信营运商转向提供语音、视频与数据服务的"三重播放业务"可充分证实这一发展趋势。
* 从固定地址服务到家庭服务再到移动服务的演进。有线基础局端中从语音到数据再到媒体的演讲现在正在无线领域悄然进行。
* 上述前三个趋势推动了另一趋势的发展:从电路交换传输到基于数据包的传输的演进,特别是对因特网协议 (IP) 流量。
在语音通信时代,电信信号处理无非是回声消除、数据调制解调器的线路调节以及在交换电路上进行数据调制/解调的信号处理。目前,用来进行音频、视频和数据流量的数字编码/解码以及压缩/解压缩的算法就有数十种之多。简言之,电信基础局端不仅仅是要处理更多的数据,而且要实现信号处理量的指数级增长以实时处理大量数据。
显而易见,要实现信号处理量的指数级增长需要大幅提高性能。方法一是仅加快数字信号处理器 (DSP) 的时钟速度。但这种解决方案不是长久之计,主要原因如下:首先,芯片时钟速度有限;其次,流量负载呈指数级而非线性增长,即使在最高时钟速度下,也将很快无法满足性能要求。另一个基本问题是基础局端设备采用机架安装,对尺寸和散热都有严格的要求。在机架尺寸不变(缩小尺寸除外)的情况下,就是高时钟速度带来的高散热最终也会使仅提高时钟速度这一方法不可行。将来,电路板性能的提升会受到其功耗预算、楼宇的使用年限与位置以及安装基础局端设备的机架等的限制。
提高性能
电信设计工程师面临着一个巨大的挑战。他们必须在更小的板级空间内提供更出色的性能、增加通道密度、处理日益多样化的媒体阵列,并同时保持通信的灵活性与低成本特性。
为应对这些挑战,我们一直在改进 DSP。从芯片设计人员的角度来说,这意味着要将上述趋势转化为特定的 IC 特性与架构。
同时实现高性能与低功耗目标的最佳战略方案是在低电压芯片上采用优化的处理引擎及高效 I/O 处理尽可能多的数据。
处理不断增多的原始数据量要求极高的性能与高效的片上数据传输能力。从架构上讲,这可通过交换中心资源 (SCR) 连接处理元件(DPS CPU、DSP 外设、协处理器加速器以及内部存储器)得以实现,即具有主从单元的纵横制架构。德州仪器 (TI) TMS320C6455 DSP 采用的就是这种架构(见图1)。
SCR左边的任一主单元均可直接与SCR右边的从单元相连。主单元包括DSP的CPU、串行高速IO (SRIO)、四个传输控制器(TC)以及连接将三个主外设(PCI、HPI与EMAC)的连接至SCR的纵横制端口。从单元包括DSP存储器、DDR存储器接口、Turbo协处理器 (TCP)、Viterbi 协处理器(VCP)以及将多个外设连接至 SCR 的纵横制端口。
这种架构既快速又高效,因为 SCR 使主从单元之间实现了真正的同时数据传输。例如,PCI 至 DDR EMIF 的连接独立于 PCI 166 至 DSP CPU 的连接。数据完全是并行传输。当多个主单元访问同一个从单元时,SCR 执行判优。同时系统设计人员可以通过对主单元的优先级别进行编程来施加某些控制。
架构要求
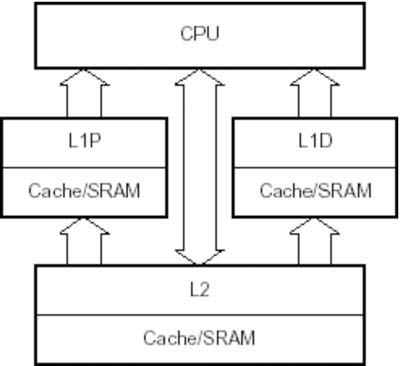
在执行算法时,CPU 与存储器之间的指令和数据传输至关重要。在如图 2 所示的 TMS320C6455 DSP 存储器系统中,可通过使用 256 位宽的数据总线并在 CPU 与存储器之间的内部直接存储器存取 (DMA) 架构上创建两层高速缓存来优化数据传输。
另一个架构要求是高效片上处理引擎。一种高效的方法是集成片上协处理器,以加速要求高性能的特定功能。例如,MS320C6455 DSP 就集成了 Viterbi 协处理器 (VCP) 与 Turbo 协处理器 (TCP),如图 1 所示。
片上处理工作完成后,开发人员仍需将大量数据从芯片传输至电路板上,最终传输到电信传输介质上。显然应选择高速 IO,但考虑到上述的异构架构,确定哪种处理方法最佳就会变得复杂。
最佳解决方案是为片内板级接口提供多种高性能 IO 接口。SRIO 是异构多处理器器件间通信的最佳选择,因为其高吞吐消息传递方案可实现 95% 的带宽利用率(4x 串行双向链路可达 10 Gb/s)。
当然,外部存储器传输最好采用 32 位 DDR2 存储器控制器;同样,连接片外器件最好采用 66 MHz PCI 总线;处理板上或板外 IP 流量的最好选择 1 Gb/s 以太网媒体接入控制器 (EMAC);电信专用的通用测试与操作 PHY 接口则可充分满足 ATM (UTOPIA 2) 连接的需求。
虽然 DSP 处理能力随着具有更强并行能力以及其它高级特性的新架构的推出而显著提高,但电路板设计人员还可通过将多个 DSP 高效集成到单个电路板来获取更明显的改善。使用 SRIO 快速连接大大简化了这项工作,因为从 DSP 软件的角度来看,DSP 之间的数据流处理与单个 DSP 内的数据流处理并没有很大的差异。
多媒体内容随着总流量的增长而变得日益丰富,这为设备制造商带来了前所未有的工程设计挑战与机遇。他们必须制造出新一代能够处理持续急速上升的汇聚流量的设备,该汇聚流量基本不同于过去主导基础局端设计范例的语音与数据流量。
这种变革是上个世纪 70 年代计算机革命以来的多重趋势引发的:
* 从纯语音流量到语音与数据流量的转变。这一趋势在数十年前就已开始了,现在仍在继续。
* 多媒体流量,特别是流媒体,加入现有的语音与数据流量。电信营运商转向提供语音、视频与数据服务的"三重播放业务"可充分证实这一发展趋势。
* 从固定地址服务到家庭服务再到移动服务的演进。有线基础局端中从语音到数据再到媒体的演讲现在正在无线领域悄然进行。
* 上述前三个趋势推动了另一趋势的发展:从电路交换传输到基于数据包的传输的演进,特别是对因特网协议 (IP) 流量。
在语音通信时代,电信信号处理无非是回声消除、数据调制解调器的线路调节以及在交换电路上进行数据调制/解调的信号处理。目前,用来进行音频、视频和数据流量的数字编码/解码以及压缩/解压缩的算法就有数十种之多。简言之,电信基础局端不仅仅是要处理更多的数据,而且要实现信号处理量的指数级增长以实时处理大量数据。
显而易见,要实现信号处理量的指数级增长需要大幅提高性能。方法一是仅加快数字信号处理器 (DSP) 的时钟速度。但这种解决方案不是长久之计,主要原因如下:首先,芯片时钟速度有限;其次,流量负载呈指数级而非线性增长,即使在最高时钟速度下,也将很快无法满足性能要求。另一个基本问题是基础局端设备采用机架安装,对尺寸和散热都有严格的要求。在机架尺寸不变(缩小尺寸除外)的情况下,就是高时钟速度带来的高散热最终也会使仅提高时钟速度这一方法不可行。将来,电路板性能的提升会受到其功耗预算、楼宇的使用年限与位置以及安装基础局端设备的机架等的限制。
提高性能
电信设计工程师面临着一个巨大的挑战。他们必须在更小的板级空间内提供更出色的性能、增加通道密度、处理日益多样化的媒体阵列,并同时保持通信的灵活性与低成本特性。
为应对这些挑战,我们一直在改进 DSP。从芯片设计人员的角度来说,这意味着要将上述趋势转化为特定的 IC 特性与架构。
同时实现高性能与低功耗目标的最佳战略方案是在低电压芯片上采用优化的处理引擎及高效 I/O 处理尽可能多的数据。
处理不断增多的原始数据量要求极高的性能与高效的片上数据传输能力。从架构上讲,这可通过交换中心资源 (SCR) 连接处理元件(DPS CPU、DSP 外设、协处理器加速器以及内部存储器)得以实现,即具有主从单元的纵横制架构。德州仪器 (TI) TMS320C6455 DSP 采用的就是这种架构(见图1)。
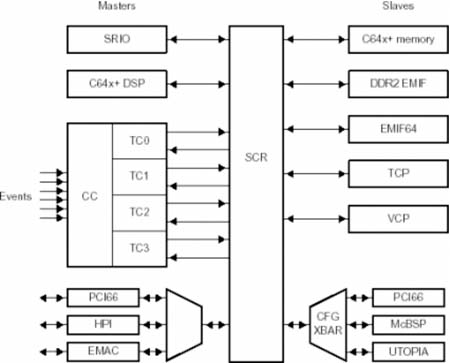
SCR左边的任一主单元均可直接与SCR右边的从单元相连。主单元包括DSP的CPU、串行高速IO (SRIO)、四个传输控制器(TC)以及连接将三个主外设(PCI、HPI与EMAC)的连接至SCR的纵横制端口。从单元包括DSP存储器、DDR存储器接口、Turbo协处理器 (TCP)、Viterbi 协处理器(VCP)以及将多个外设连接至 SCR 的纵横制端口。
这种架构既快速又高效,因为 SCR 使主从单元之间实现了真正的同时数据传输。例如,PCI 至 DDR EMIF 的连接独立于 PCI 166 至 DSP CPU 的连接。数据完全是并行传输。当多个主单元访问同一个从单元时,SCR 执行判优。同时系统设计人员可以通过对主单元的优先级别进行编程来施加某些控制。
架构要求
在执行算法时,CPU 与存储器之间的指令和数据传输至关重要。在如图 2 所示的 TMS320C6455 DSP 存储器系统中,可通过使用 256 位宽的数据总线并在 CPU 与存储器之间的内部直接存储器存取 (DMA) 架构上创建两层高速缓存来优化数据传输。
另一个架构要求是高效片上处理引擎。一种高效的方法是集成片上协处理器,以加速要求高性能的特定功能。例如,MS320C6455 DSP 就集成了 Viterbi 协处理器 (VCP) 与 Turbo 协处理器 (TCP),如图 1 所示。
片上处理工作完成后,开发人员仍需将大量数据从芯片传输至电路板上,最终传输到电信传输介质上。显然应选择高速 IO,但考虑到上述的异构架构,确定哪种处理方法最佳就会变得复杂。
最佳解决方案是为片内板级接口提供多种高性能 IO 接口。SRIO 是异构多处理器器件间通信的最佳选择,因为其高吞吐消息传递方案可实现 95% 的带宽利用率(4x 串行双向链路可达 10 Gb/s)。
当然,外部存储器传输最好采用 32 位 DDR2 存储器控制器;同样,连接片外器件最好采用 66 MHz PCI 总线;处理板上或板外 IP 流量的最好选择 1 Gb/s 以太网媒体接入控制器 (EMAC);电信专用的通用测试与操作 PHY 接口则可充分满足 ATM (UTOPIA 2) 连接的需求。
虽然 DSP 处理能力随着具有更强并行能力以及其它高级特性的新架构的推出而显著提高,但电路板设计人员还可通过将多个 DSP 高效集成到单个电路板来获取更明显的改善。使用 SRIO 快速连接大大简化了这项工作,因为从 DSP 软件的角度来看,DSP 之间的数据流处理与单个 DSP 内的数据流处理并没有很大的差异。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)