32位DSP两级cache的结构设计
时间:09-17
来源:
点击:
5 如何根据地址在cache中找到所需要的数据
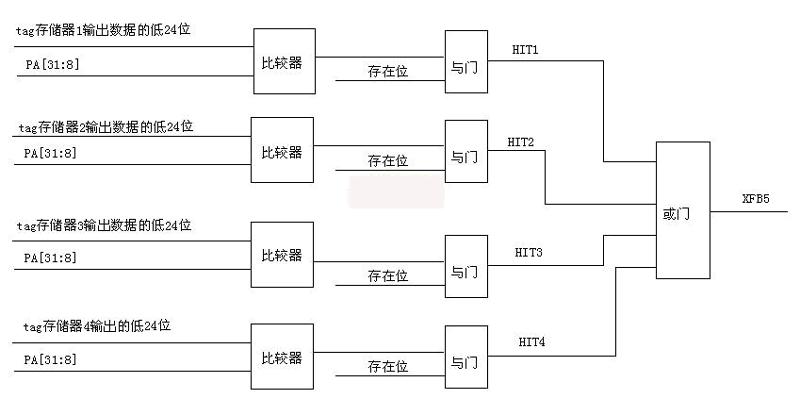
图6 I cache查找数据的过程
能够映射到cache中某一行的数据很多,那么是怎样在cache中找到所需要的数据呢?主要是借助于标记。以 I cache 为例,当CPU发出读信号时,则首先以组号PA[7:3]为地址,从I cache的四组标记寄存器中读取标记,送往对应的比较器,和地址信号PA[31:8]进行比较,如果比较相等,且存在位有效,则表示命中。HIT1表示第1组命中,依次类推。HIT1 ,HIT2,HIT3,HIT4经过或门以后,就是总体命中与否的输出信号。如果HIT1有效,以PA[7:0]对cache的数据体1进行寻址,读取相应的数据。其它情况类似。在这个过程中,可以看出,地址和数据之间的一一对应关系。
6 数据块传输
数据块传输是对存储器的一种重要操作,根据译码电路的层次性,知道如果只是地址的低位发生改变,译码电路很快就可以达到稳定状态,选择对应的单元,进行读写。因此对数据进行整组传输,有利于提高传输的效率。在该cache中,对存储器的访问都是定长的,如果产生不命中的信号,则立即产生8拍定长的读写信号。具体实现时,设计了一个控制块传输信号的模块。每当产生不命中的信号,则把块传输的初始地址读入到该模块的初始地址寄存器,设置相应的传输单元数为8,以及对应的cache单元的读写信号。在每个时钟的上升沿,地址寄存器增1,传输单元个数寄存器减1,当传输单元个数寄存器的数据为0时,就结束传输。
由于L2 cache是个单端口的存储器,一级cache采用哈佛结构,对数据和指令同时进行操作,当D cache和I cache失效时,都会访问L2 cache,这样就有可能产生冲突。为了解决这个问题,在块传输控制的模块中,设置了一位busy位,用来标志总线忙状态。当某个请求得到响应,其余的请求只有进入等待状态。在设计时,制定了访问L2 cache的优先级协议:读指令不命中的优先级最高,写数据不命中的优先级次之,读数据不命中的优先级最低。当I cache和D cache同时产生不命中的信号时,根据优先级协议来访问L2 cache。
7 结束语
在命中率方面,采用两级cache结构及组关联映射方法提高了cache系统的命中率。在数据处理效率方面,由于一级cache采用哈佛结构,指令和数据可并行操作,显着提高了系统的数据处理能力。在功耗方面,采用了数据体和标记相分离的措施,这使得只有在cache命中的情况下,才会访问数据体,可降低系统的功耗。
整个设计采用自顶向下的设计流程,用Verilog语言描述整个系统,在synopsys工具下进行仿真和综合。在综合的结果中,指令cache的延迟最长,为4.3ns.整个cache系统的等效门数约24万个门。
作者的创新点:设置busy位标志总线忙状态,并制定优先级协议处理多信号同时访问总线的情况,有效解决了总线的访问冲突问题。
图6 I cache查找数据的过程
能够映射到cache中某一行的数据很多,那么是怎样在cache中找到所需要的数据呢?主要是借助于标记。以 I cache 为例,当CPU发出读信号时,则首先以组号PA[7:3]为地址,从I cache的四组标记寄存器中读取标记,送往对应的比较器,和地址信号PA[31:8]进行比较,如果比较相等,且存在位有效,则表示命中。HIT1表示第1组命中,依次类推。HIT1 ,HIT2,HIT3,HIT4经过或门以后,就是总体命中与否的输出信号。如果HIT1有效,以PA[7:0]对cache的数据体1进行寻址,读取相应的数据。其它情况类似。在这个过程中,可以看出,地址和数据之间的一一对应关系。
6 数据块传输
数据块传输是对存储器的一种重要操作,根据译码电路的层次性,知道如果只是地址的低位发生改变,译码电路很快就可以达到稳定状态,选择对应的单元,进行读写。因此对数据进行整组传输,有利于提高传输的效率。在该cache中,对存储器的访问都是定长的,如果产生不命中的信号,则立即产生8拍定长的读写信号。具体实现时,设计了一个控制块传输信号的模块。每当产生不命中的信号,则把块传输的初始地址读入到该模块的初始地址寄存器,设置相应的传输单元数为8,以及对应的cache单元的读写信号。在每个时钟的上升沿,地址寄存器增1,传输单元个数寄存器减1,当传输单元个数寄存器的数据为0时,就结束传输。
由于L2 cache是个单端口的存储器,一级cache采用哈佛结构,对数据和指令同时进行操作,当D cache和I cache失效时,都会访问L2 cache,这样就有可能产生冲突。为了解决这个问题,在块传输控制的模块中,设置了一位busy位,用来标志总线忙状态。当某个请求得到响应,其余的请求只有进入等待状态。在设计时,制定了访问L2 cache的优先级协议:读指令不命中的优先级最高,写数据不命中的优先级次之,读数据不命中的优先级最低。当I cache和D cache同时产生不命中的信号时,根据优先级协议来访问L2 cache。
7 结束语
在命中率方面,采用两级cache结构及组关联映射方法提高了cache系统的命中率。在数据处理效率方面,由于一级cache采用哈佛结构,指令和数据可并行操作,显着提高了系统的数据处理能力。在功耗方面,采用了数据体和标记相分离的措施,这使得只有在cache命中的情况下,才会访问数据体,可降低系统的功耗。
整个设计采用自顶向下的设计流程,用Verilog语言描述整个系统,在synopsys工具下进行仿真和综合。在综合的结果中,指令cache的延迟最长,为4.3ns.整个cache系统的等效门数约24万个门。
作者的创新点:设置busy位标志总线忙状态,并制定优先级协议处理多信号同时访问总线的情况,有效解决了总线的访问冲突问题。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)